Modern software development faces persistent bottlenecks: slow iteration cycles, coordination overhead in large teams, opaque AI-assisted coding workflows, and limited…
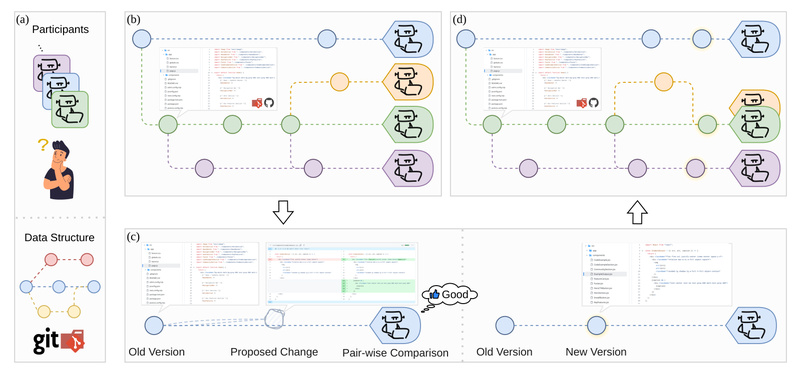
Modern software development faces persistent bottlenecks: slow iteration cycles, coordination overhead in large teams, opaque AI-assisted coding workflows, and limited…
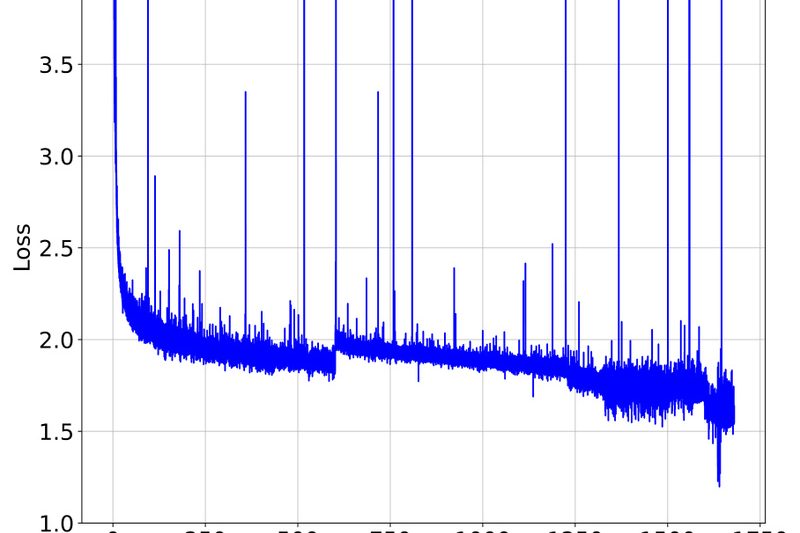
YuLan is an open-source large language model (LLM) series developed by the Gaoling School of Artificial Intelligence (GSAI) at Renmin…
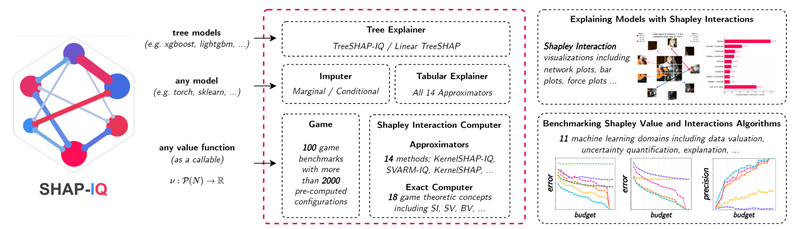
In the world of explainable AI, understanding which features matter is only half the story. What if two seemingly unimportant…
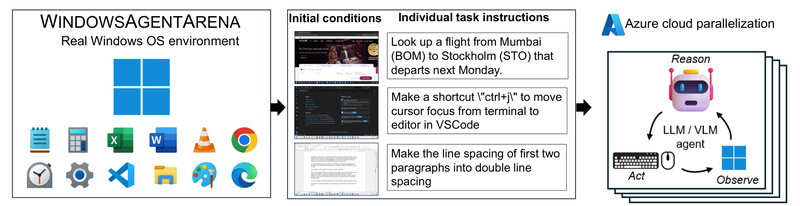
Evaluating AI agents that interact with desktop operating systems has long been hampered by artificial or limited test environments. Most…
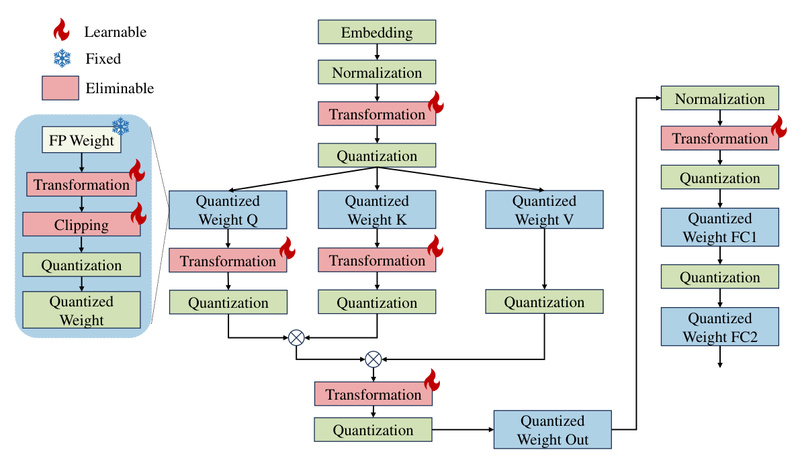
Deploying large language models (LLMs) in real-world applications remains a major engineering challenge. While models like LLaMA-2, Falcon, and Mixtral…
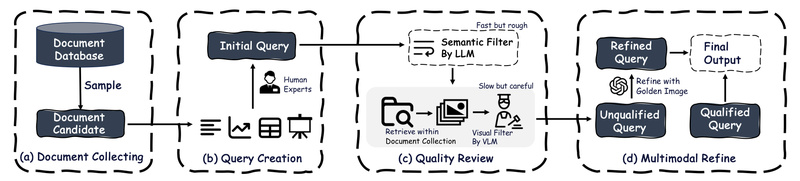
Traditional Retrieval-Augmented Generation (RAG) systems excel at answering questions using text-based documents—but they often stumble when faced with visually rich…
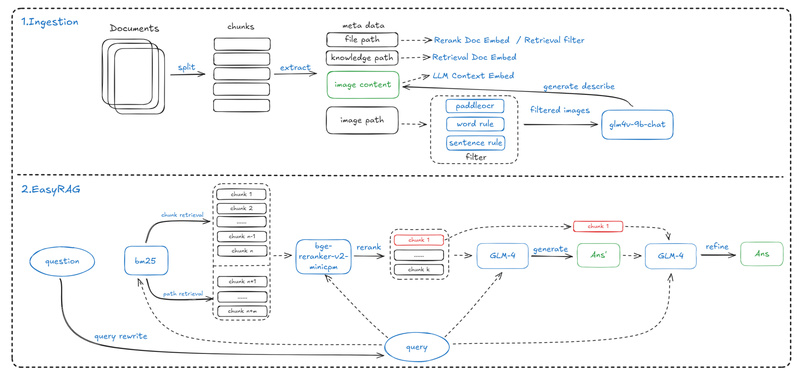
In today’s fast-paced IT and enterprise environments, teams increasingly rely on retrieval-augmented generation (RAG) systems to provide accurate, context-aware answers…
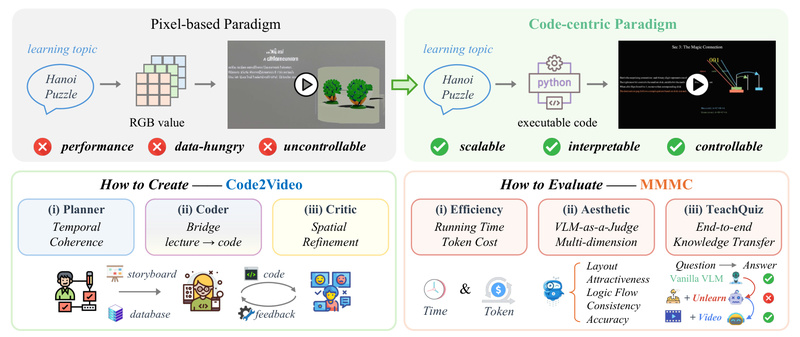
Traditional AI-powered video generators—especially those based on diffusion or pixel-level synthesis—struggle when it comes to creating high-quality educational content. While…
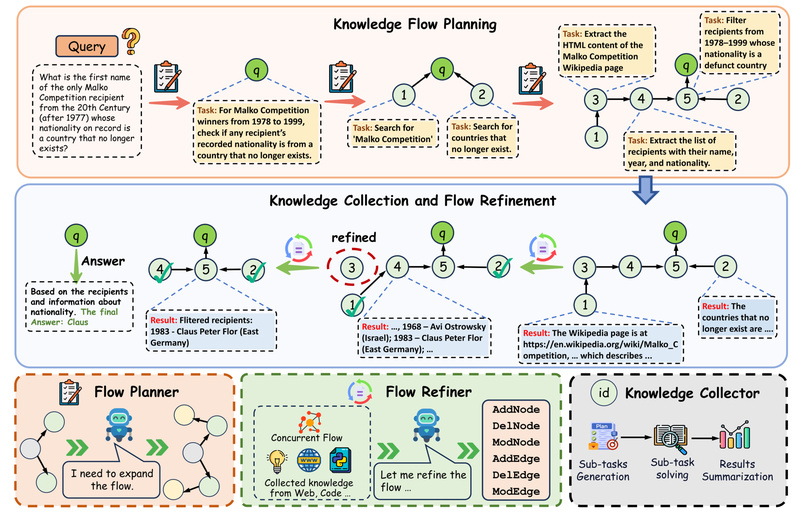
Deep research—whether in scientific discovery, engineering design, or AI innovation—is rarely linear. It demands navigating complex dependencies, synthesizing cross-disciplinary insights,…
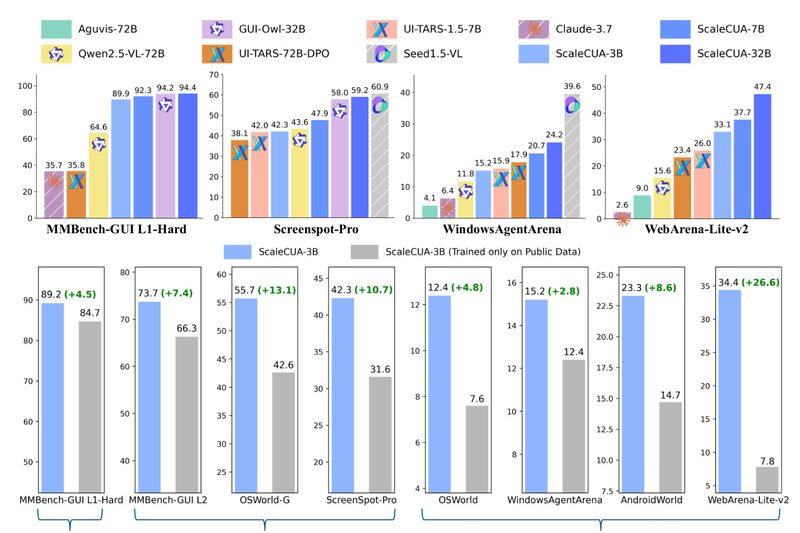
Building reliable computer use agents (CUAs)—systems that can autonomously interact with graphical user interfaces (GUIs)—has long been hindered by a…