For teams building real-world AI applications that combine vision and language—whether it’s parsing scanned documents, analyzing instructional videos, or creating…
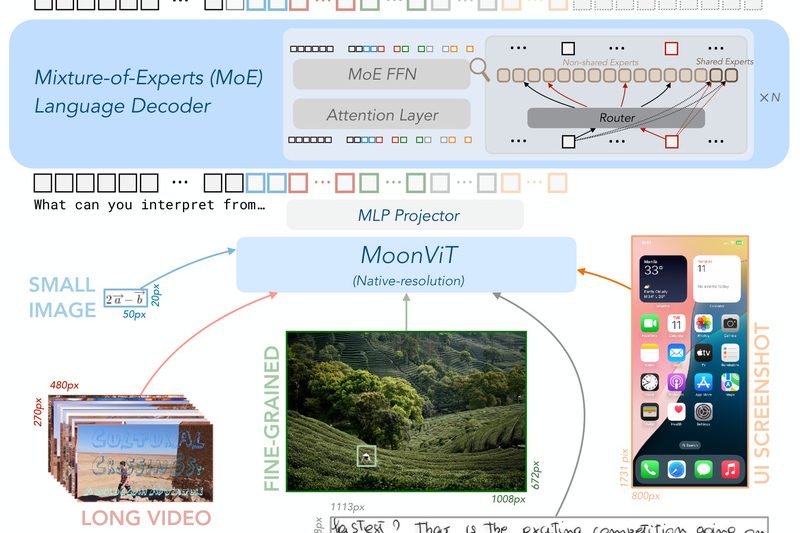
For teams building real-world AI applications that combine vision and language—whether it’s parsing scanned documents, analyzing instructional videos, or creating…

In the rapidly evolving landscape of large language models (LLMs), a critical limitation persists: despite their impressive fluency, LLMs often…
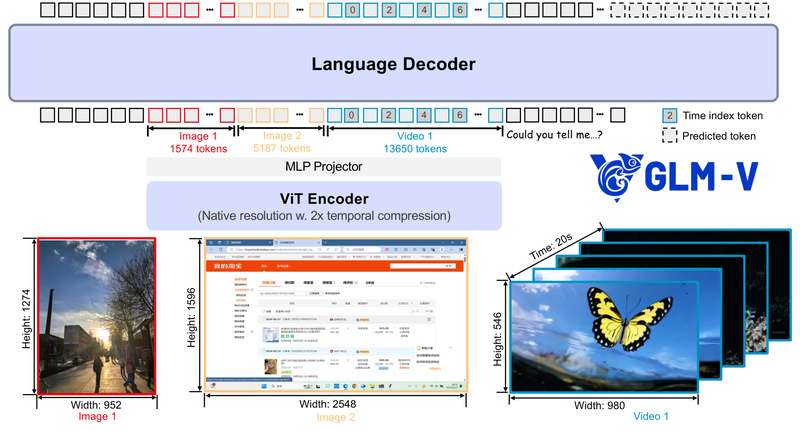
If your team is building AI applications that need to see, reason, and act—like desktop assistants that interpret screenshots, UI…
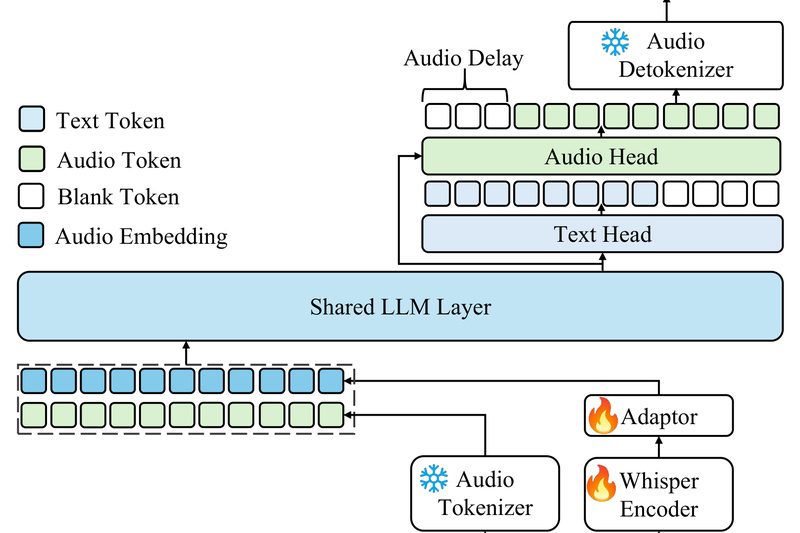
Building voice-enabled applications today often means stitching together separate models for speech recognition, sound classification, audio captioning, and spoken response…
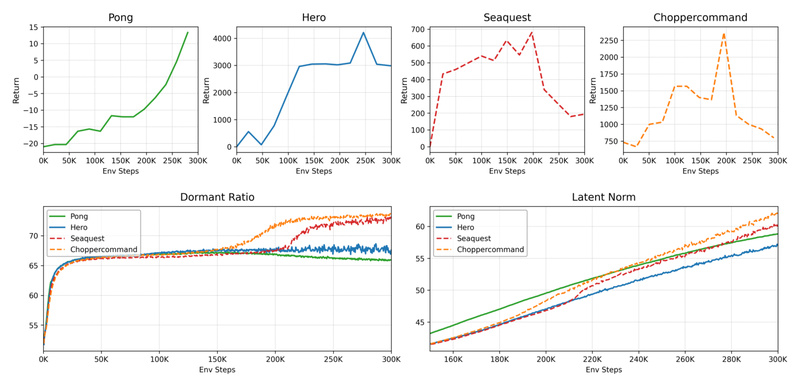
If you’re evaluating tools for building intelligent agents that combine planning and learning—whether for games, robotics, scientific discovery, or general…

Step-Audio 2 is an open-source, end-to-end multimodal large language model (MLM) purpose-built for real-world audio understanding and natural speech conversation.…
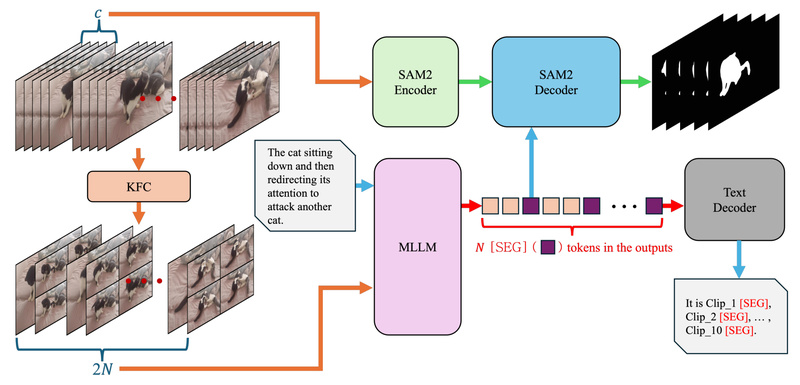
Sa2VA represents a significant leap forward in multimodal AI by seamlessly integrating the strengths of SAM2—Meta’s state-of-the-art video object segmentation…

Quantum computing holds immense promise—but building, optimizing, and executing quantum circuits remains a formidable challenge for most developers, researchers, and…
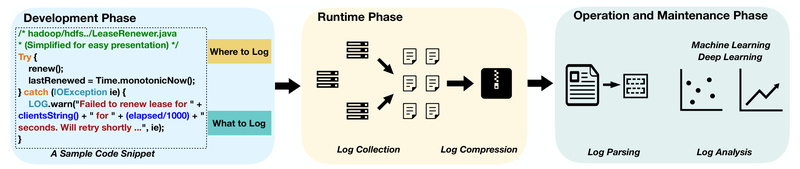
In the world of software systems—whether they’re cloud-native applications, distributed infrastructures, or legacy enterprise platforms—logs are the lifeblood of observability.…

In today’s open-source AI landscape, building truly multimodal applications often means stitching together separate models for vision, speech recognition (ASR),…