Building intelligent systems that can understand and act in the real physical world remains one of the toughest challenges in…
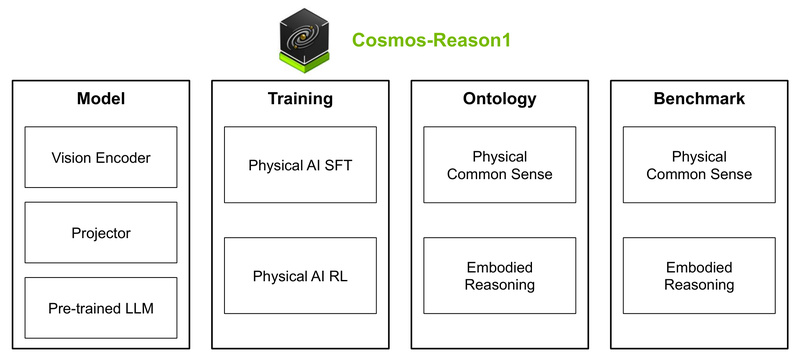
Building intelligent systems that can understand and act in the real physical world remains one of the toughest challenges in…
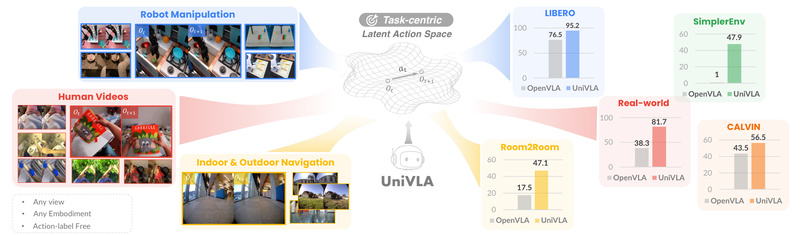
Imagine deploying a single robot policy that works across different hardware—robotic arms, mobile bases, or even human-inspired setups—without retraining from…

Generating high-quality, long-form videos with diffusion models remains one of the most computationally demanding tasks in generative AI. Standard attention…
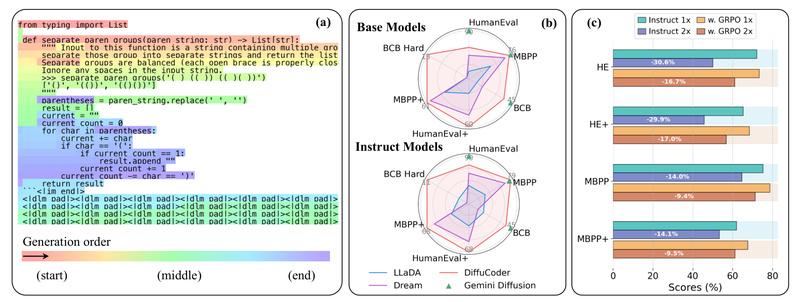
If you’re evaluating next-generation code generation tools, you’ve likely worked with autoregressive (AR) large language models—systems that build code one…

Image segmentation has long been a cornerstone of computer vision—yet traditional approaches often behave like black boxes, especially when faced…
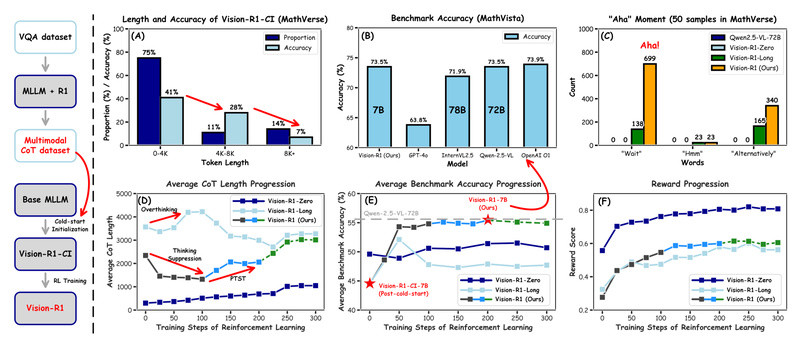
If you’re evaluating multimodal AI systems for tasks that demand deep reasoning—such as solving visual math problems, interpreting charts, or…
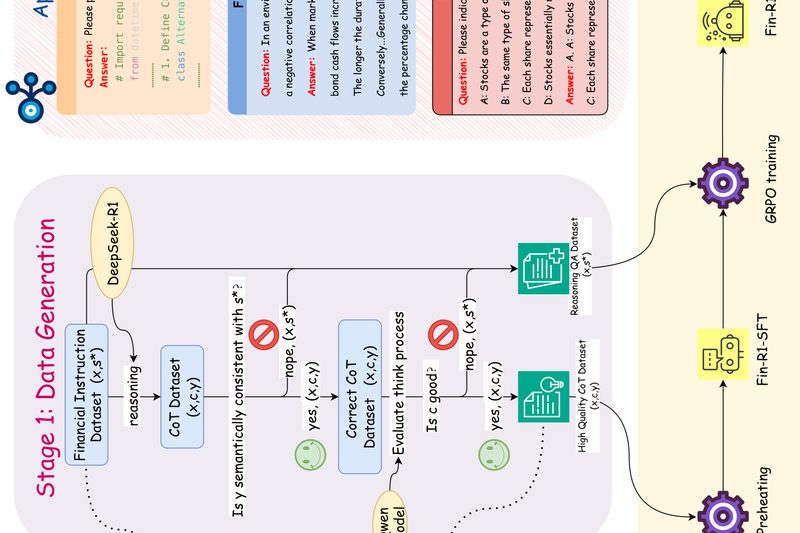
Fin-R1 is a purpose-built reasoning large language model (LLM) designed specifically for the financial domain. Despite having only 7 billion…

In the rapidly evolving field of multimodal AI, most models still struggle to combine visual understanding with precise, step-by-step logical…

Image-to-image translation is a foundational capability in computer vision, enabling applications from photo editing to 3D scene understanding. Yet many…
If you’ve ever tried to track 3D points in a monocular video—say, for robotics perception, AR/VR content creation, or sports…