Steel-LLM is a 1-billion-parameter open-source language model developed entirely from scratch with a strong focus on Chinese language understanding and…
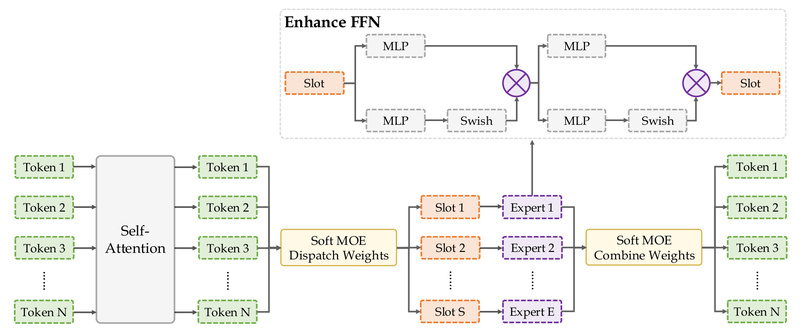
Steel-LLM is a 1-billion-parameter open-source language model developed entirely from scratch with a strong focus on Chinese language understanding and…
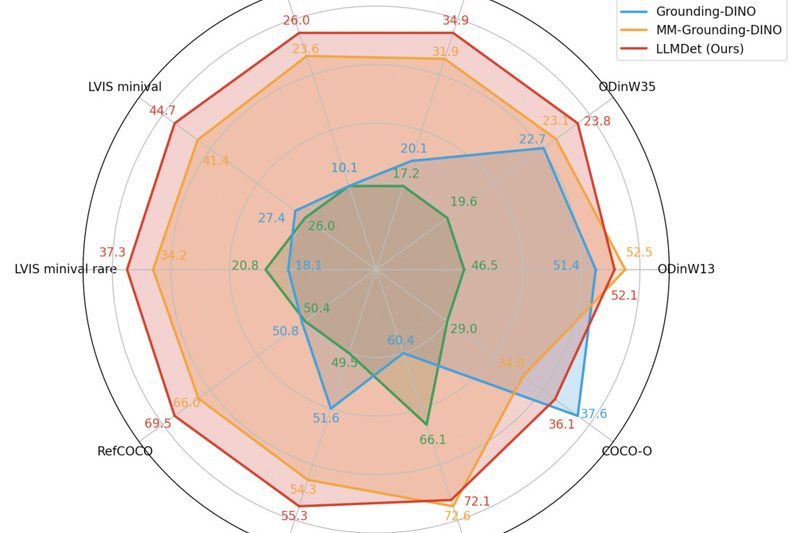
Imagine building a vision system that can detect not just pre-defined classes like “car” or “dog,” but any object described…
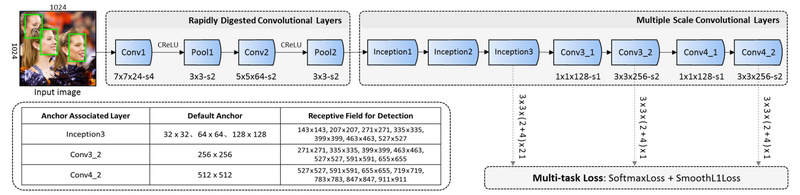
In many real-world applications—ranging from video conferencing and surveillance to edge-based biometric systems—face detection must run quickly, reliably, and without…
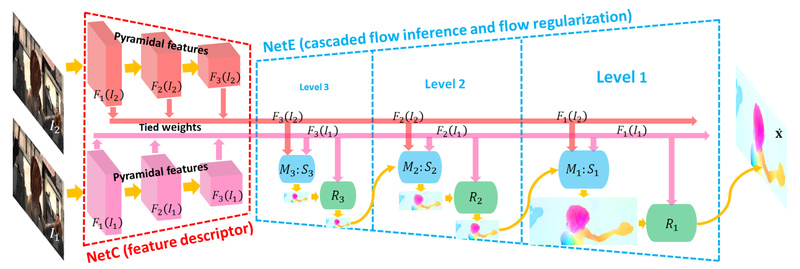
Optical flow estimation—the task of predicting per-pixel motion between consecutive video frames—is foundational in computer vision applications ranging from autonomous…
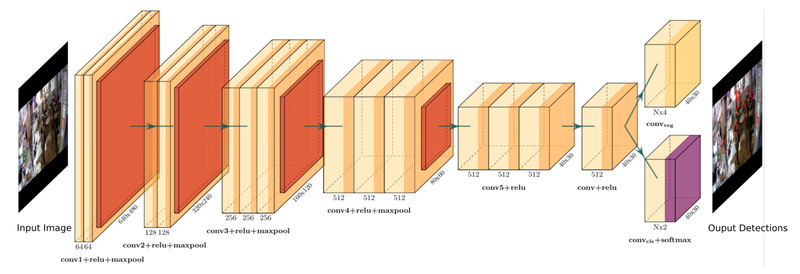
Detecting human heads in dense, real-world environments—like subway platforms, concerts, or retail stores—is a surprisingly tough problem in computer vision.…

PytorchInsight is a practical, research-oriented PyTorch library designed to accelerate deep learning development—especially for computer vision practitioners who need reliable,…
Facial landmark detection—the task of locating key points on a human face like eyes, nose, and mouth—powers countless applications, from…
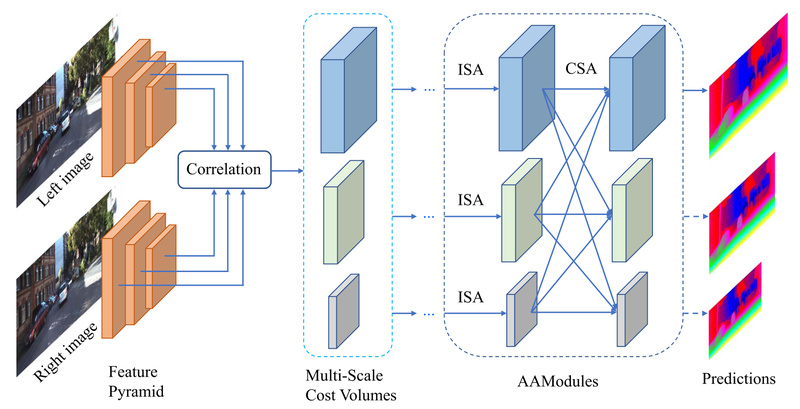
Stereo matching—the task of estimating depth from a pair of rectified images—is foundational in applications like autonomous driving, robotics, and…

Diffusion models like Stable Diffusion and SDXL have revolutionized AI image generation—but they still stumble on one persistent, high-visibility flaw:…
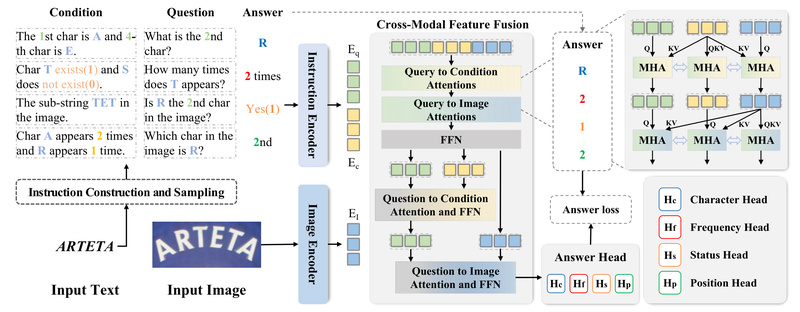
OpenOCR is a general-purpose optical character recognition (OCR) system developed by the FVL Laboratory at Fudan University. Designed with both…