Creating long, coherent, and visually rich videos with AI has long been bottlenecked by computational complexity, memory constraints, and error…
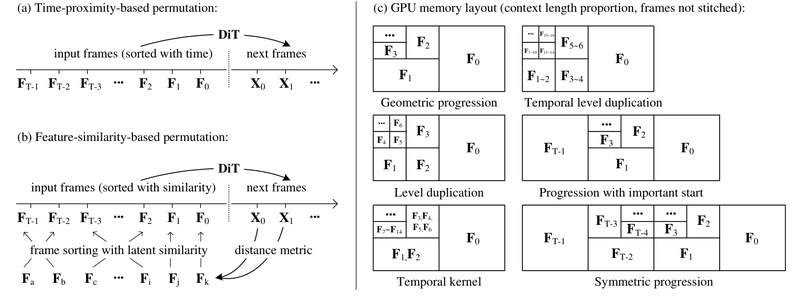
Creating long, coherent, and visually rich videos with AI has long been bottlenecked by computational complexity, memory constraints, and error…
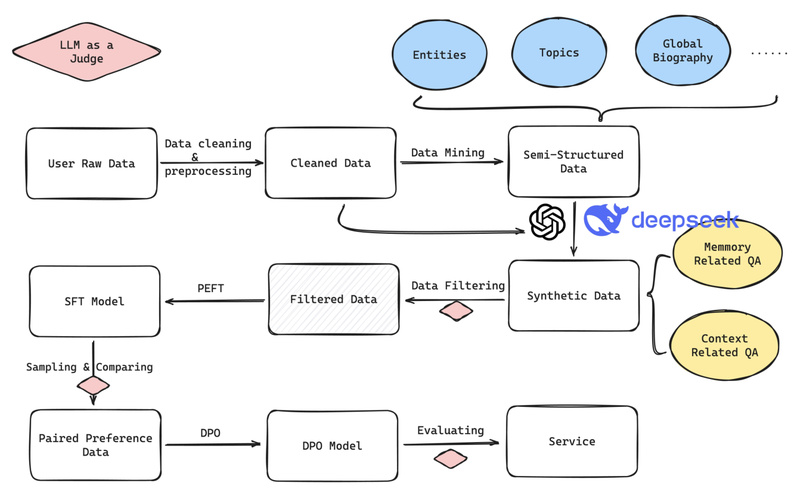
In a world where AI assistants increasingly mediate our interactions with apps, services, and even other people, a critical problem…
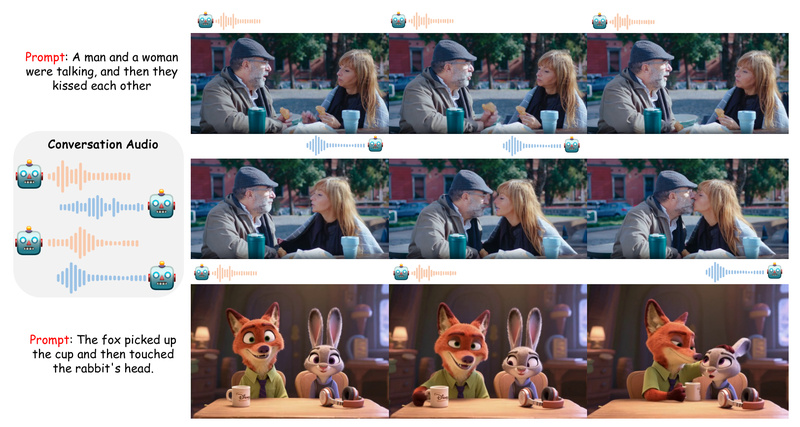
Creating lifelike videos of people talking has long been dominated by “talking head” technologies—tools that animate a single face from…
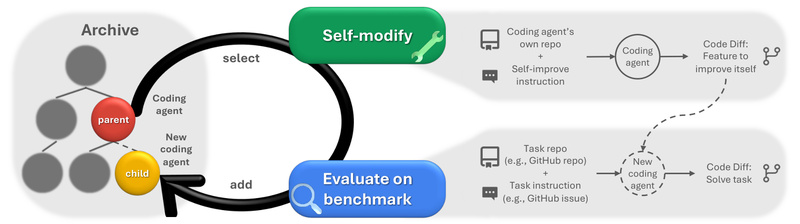
Most AI systems today are stuck in time. Their architectures, prompts, and tooling are all hand-crafted by engineers—once deployed, they…
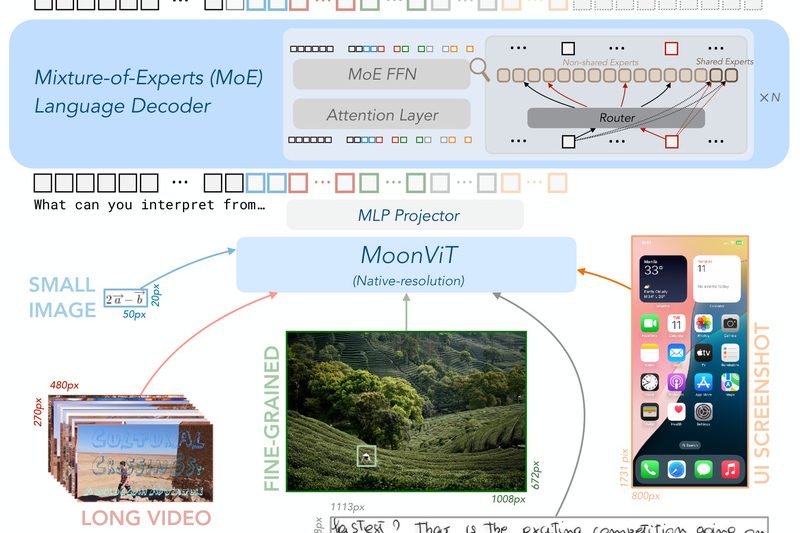
For teams building real-world AI applications that combine vision and language—whether it’s parsing scanned documents, analyzing instructional videos, or creating…

In the rapidly evolving landscape of large language models (LLMs), a critical limitation persists: despite their impressive fluency, LLMs often…
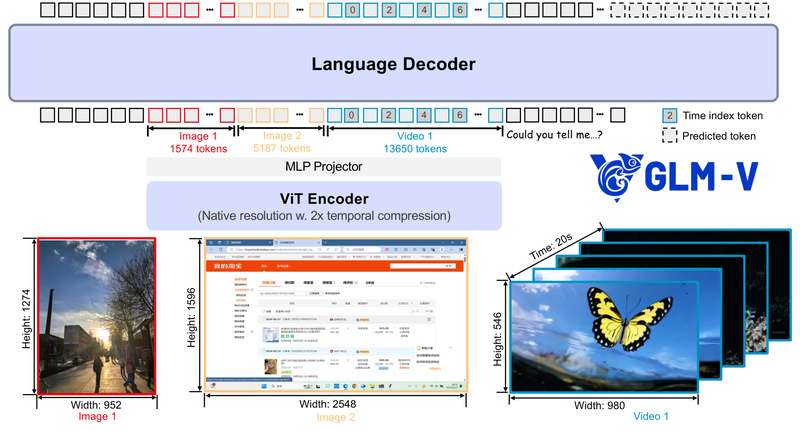
If your team is building AI applications that need to see, reason, and act—like desktop assistants that interpret screenshots, UI…
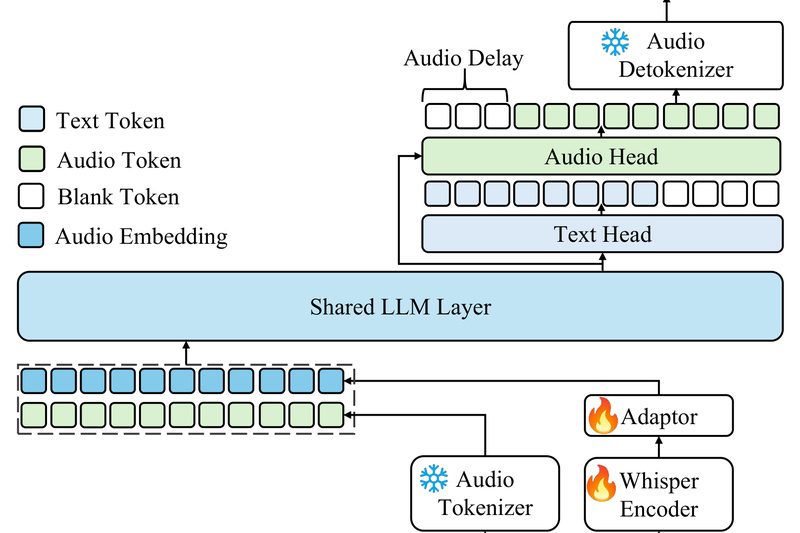
Building voice-enabled applications today often means stitching together separate models for speech recognition, sound classification, audio captioning, and spoken response…
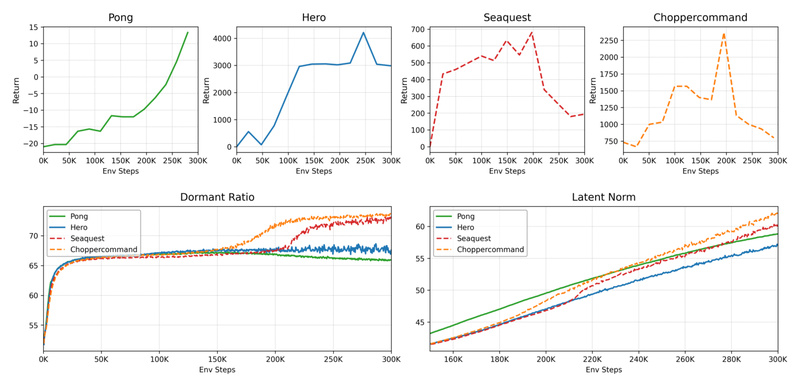
If you’re evaluating tools for building intelligent agents that combine planning and learning—whether for games, robotics, scientific discovery, or general…

Step-Audio 2 is an open-source, end-to-end multimodal large language model (MLM) purpose-built for real-world audio understanding and natural speech conversation.…