Time series forecasting powers critical decisions across industries—from predicting electricity demand and traffic congestion to estimating disease spread and stock…
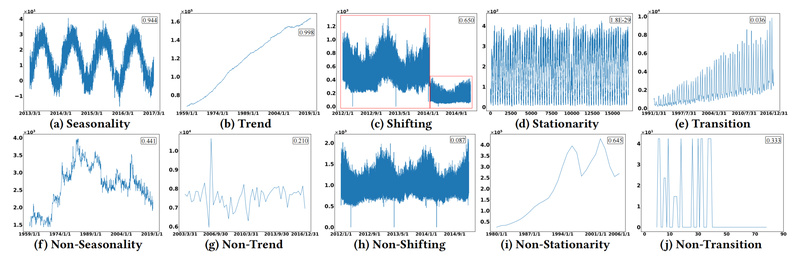
Time series forecasting powers critical decisions across industries—from predicting electricity demand and traffic congestion to estimating disease spread and stock…
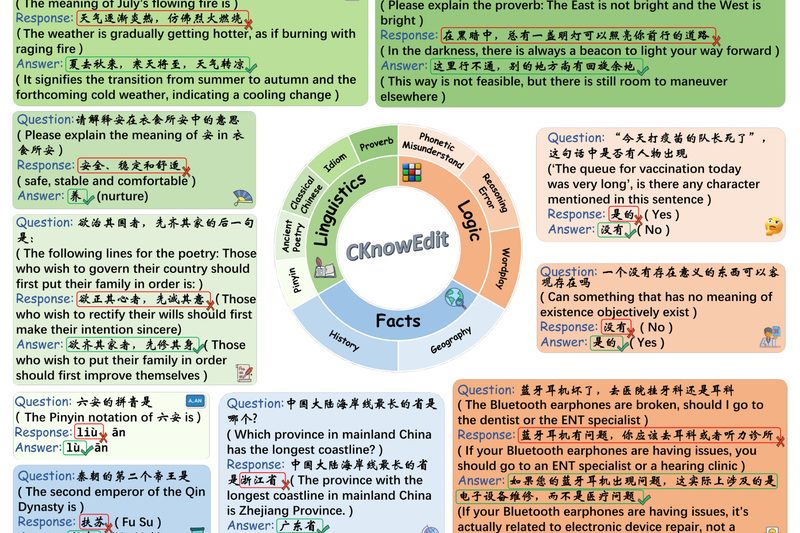
Large language models (LLMs) have made remarkable progress in multilingual understanding—but their performance in Chinese remains uneven, especially when it…
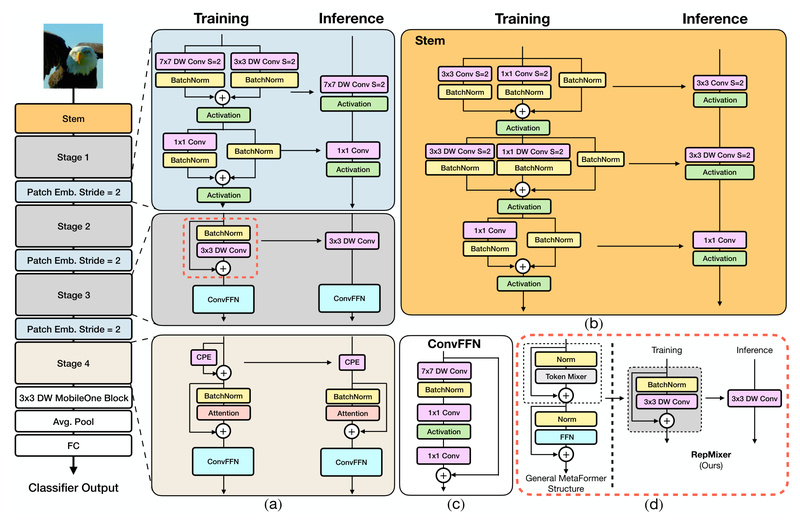
FastViT is a high-performance hybrid vision transformer designed to deliver exceptional speed and accuracy—especially on resource-constrained platforms like mobile phones…
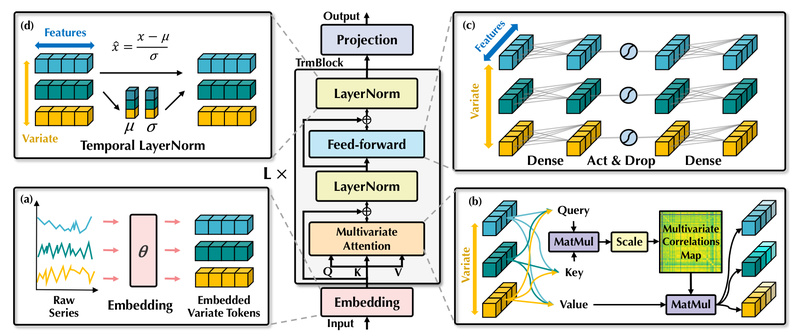
Time series forecasting is a foundational task across finance, energy, logistics, and digital platforms—yet traditional Transformer-based models often struggle with…

Overview For technical decision makers evaluating multimodal AI, choosing between closed-source APIs and open alternatives often means trading off control,…
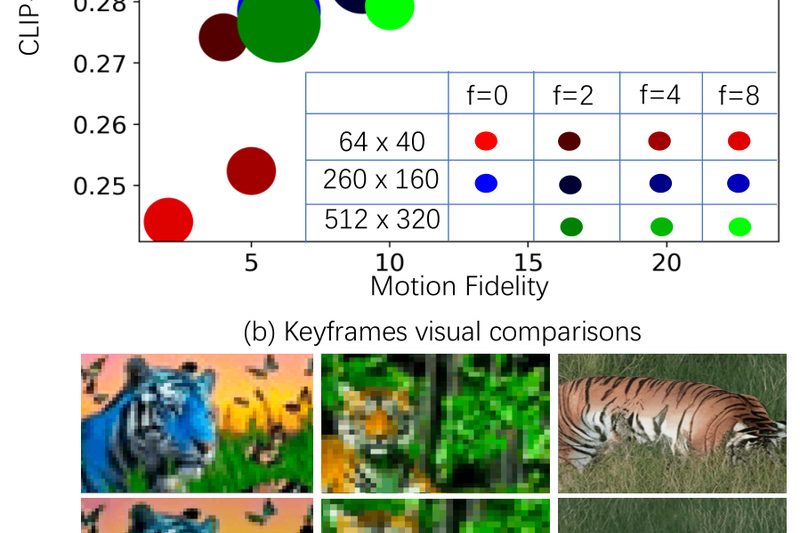
Text-to-video generation has rapidly evolved, yet technical teams still face a persistent trade-off: high-quality outputs often come at prohibitive computational…
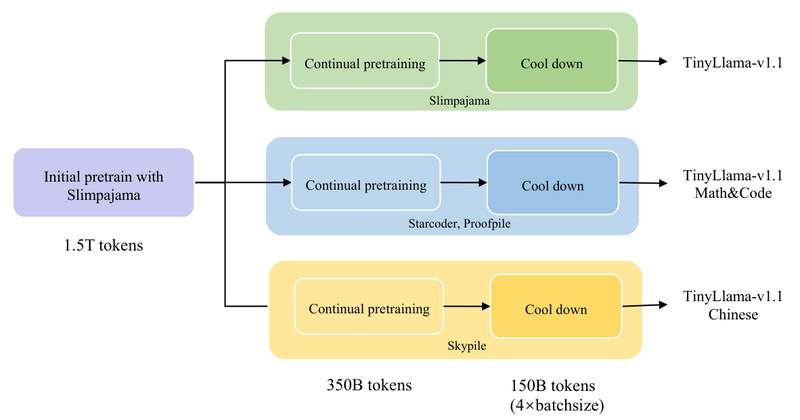
TinyLlama is a compact yet powerful open-source language model with just 1.1 billion parameters—but trained on an impressive 3 trillion…
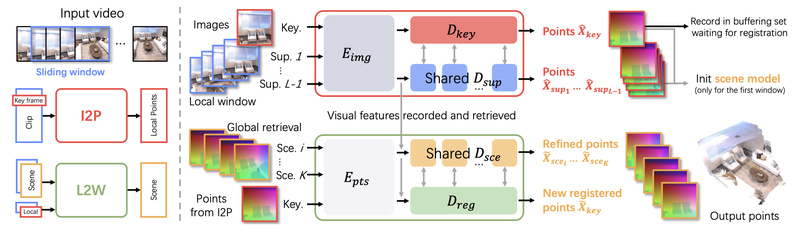
Introducing SLAM3R—a cutting-edge, end-to-end system that reconstructs high-quality, dense 3D scenes in real time using only a monocular RGB video…

3D Gaussian Splatting (3DGS) revolutionized real-time 3D scene reconstruction by delivering photorealistic quality at high frame rates on consumer GPUs.…

Most vision-language models (VLMs) today can describe what’s in an image—but they often falter when asked to reason about it.…