Retrieval-Augmented Generation (RAG) has become a go-to architecture for grounding large language models (LLMs) in external knowledge. Yet, even the…
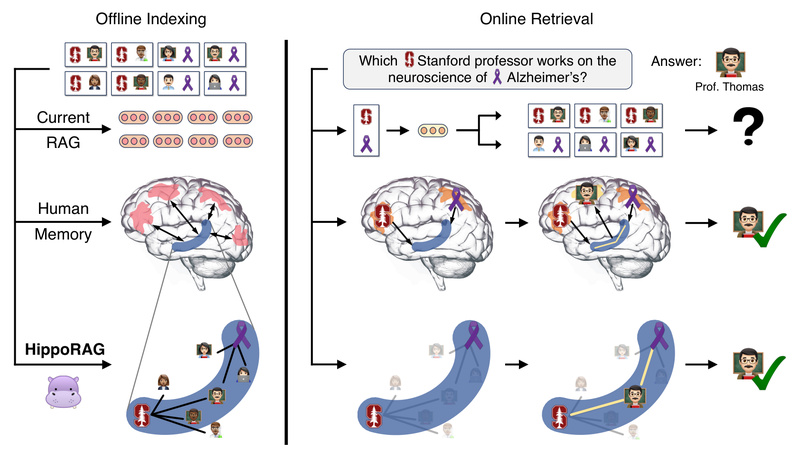
Retrieval-Augmented Generation (RAG) has become a go-to architecture for grounding large language models (LLMs) in external knowledge. Yet, even the…

Blind image restoration—recovering high-quality images from degraded inputs without knowing the exact type or severity of degradation—is a longstanding challenge…
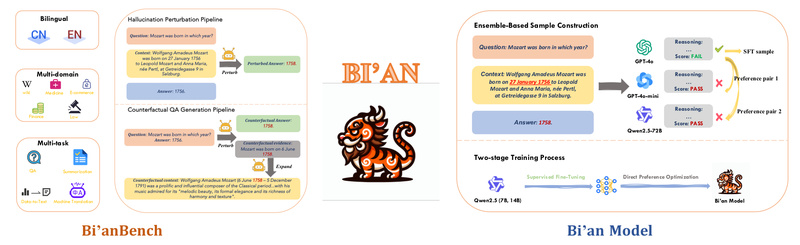
Retrieval-Augmented Generation (RAG) has become a go-to strategy for grounding large language model (LLM) responses in real-world knowledge. By pulling…
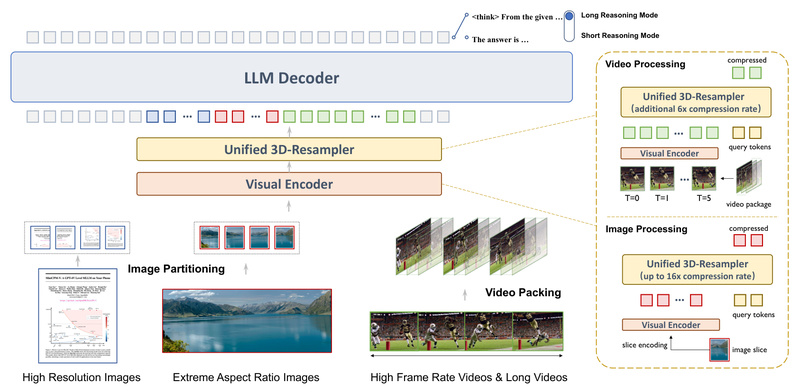
Multimodal Large Language Models (MLLMs) promise to transform how machines understand images, videos, and text—but most top-performing models come with…

Reconstructing accurate 3D geometry from 2D images has long been a fragmented, multi-step process—requiring separate models for camera pose estimation,…
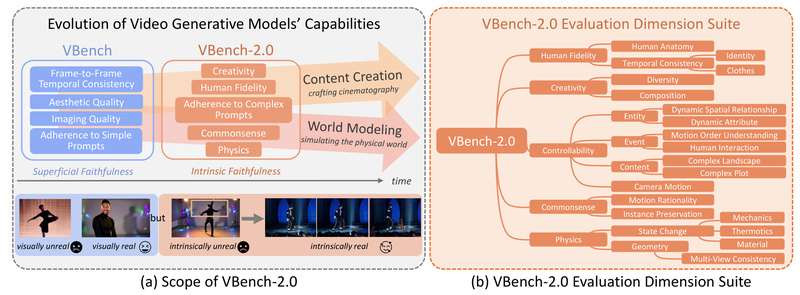
As AI-generated videos grow increasingly convincing—featuring smooth motion, vivid aesthetics, and coherent narratives—a critical question emerges: How do we reliably…
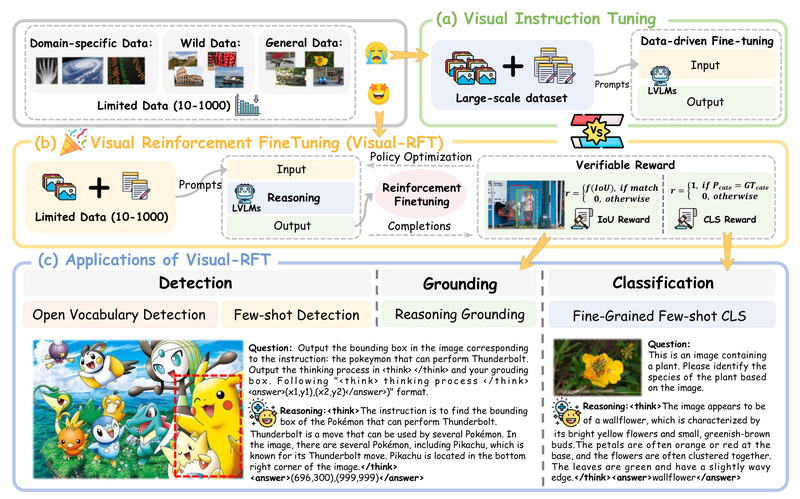
When labeled visual data is scarce—think dozens or hundreds of examples per category—traditional supervised fine-tuning (SFT) often falls short. Enter…
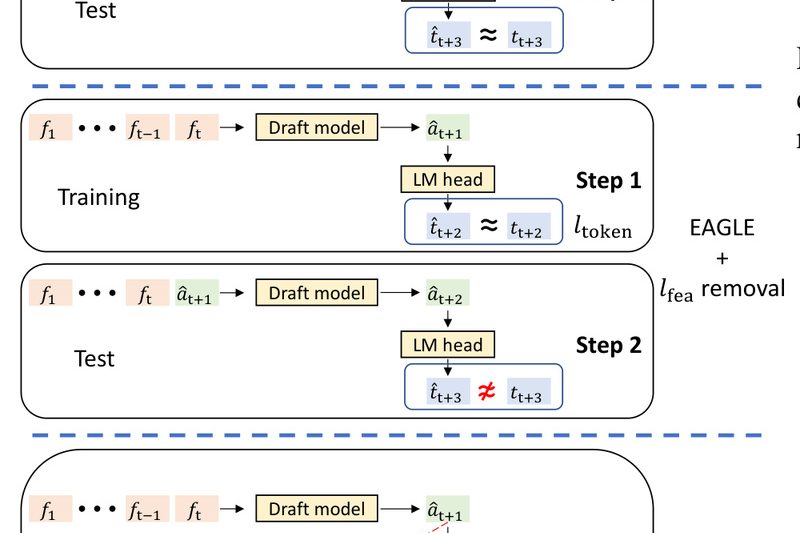
For teams deploying large language models (LLMs) in production—whether for chatbots, reasoning APIs, or batch processing—latency and inference cost are…

Scientific research in artificial intelligence is increasingly complex, time-consuming, and resource-intensive. From synthesizing hundreds of papers to prototyping novel algorithms…

Subject-driven image generation—where users provide one or more reference images of specific objects to guide the creation of new scenes—is…