If you’ve ever struggled with diffusion models failing to follow detailed prompts—like “a golden retriever sitting to the left of…
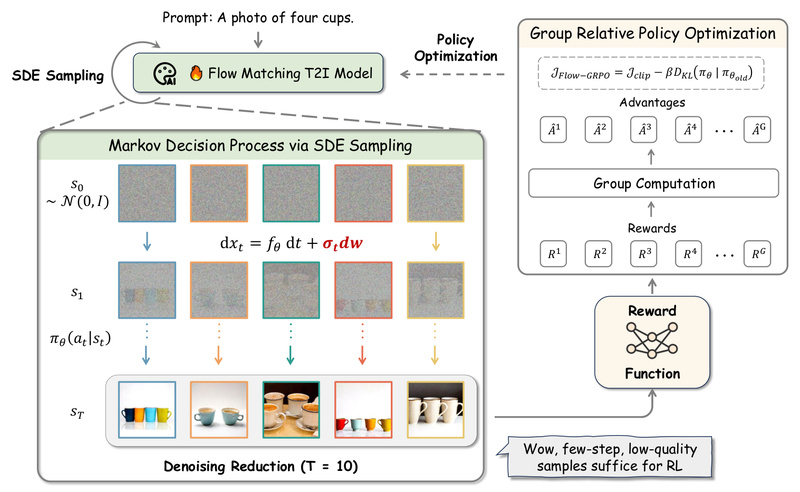
If you’ve ever struggled with diffusion models failing to follow detailed prompts—like “a golden retriever sitting to the left of…
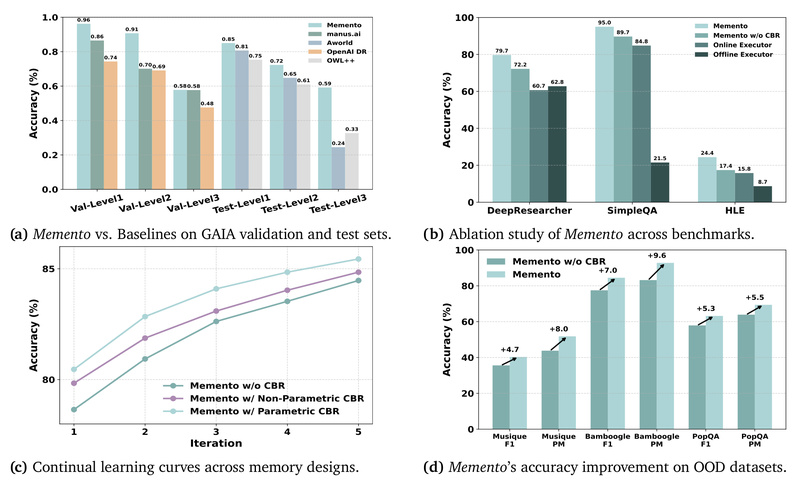
In today’s fast-paced AI landscape, teams building intelligent agents face a persistent dilemma: how to make large language models (LLMs)…
Matrix-Game is an open-source interactive world foundation model developed by Skywork AI, specifically designed for real-time, controllable generation of game…

FlowTok reimagines cross-modal generation by collapsing the traditionally complex boundary between text and images into a streamlined, efficient process. Unlike…

Decompiling machine code back into human-readable source remains one of the most challenging and valuable tasks in software engineering, cybersecurity,…
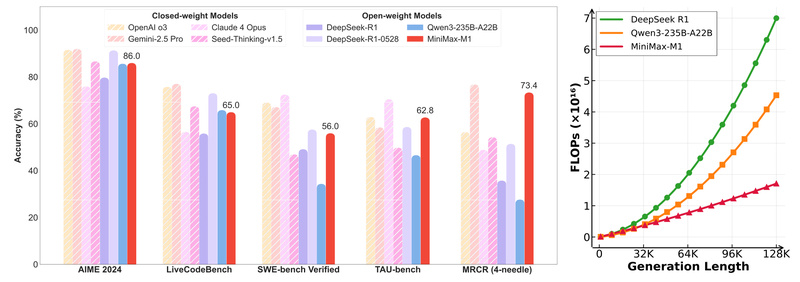
MiniMax-M1 is a breakthrough in open large language models: it’s the world’s first open-weight, large-scale hybrid-attention reasoning model. Designed for…

Creating high-quality 3D assets has long been a bottleneck in industries like gaming, virtual reality, industrial design, and digital content…
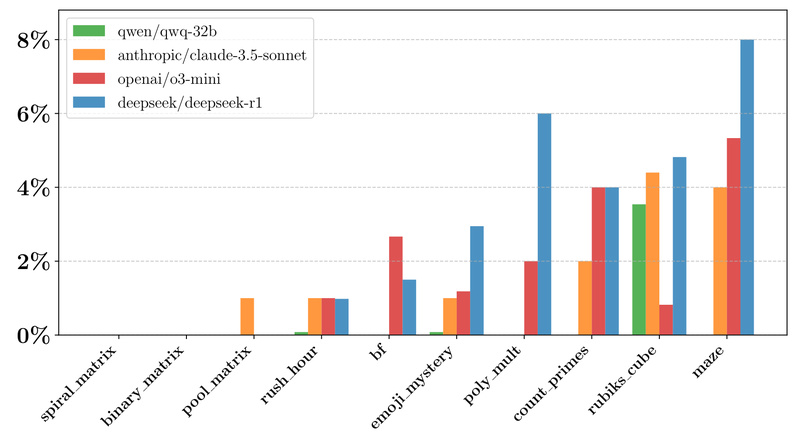
If you’re building or evaluating reasoning-capable AI systems—especially large language models (LLMs)—you’ve likely hit a wall with static benchmarks. Traditional…

Attention mechanisms lie at the heart of modern large language models (LLMs) and multimodal architectures—but their quadratic computational complexity remains…
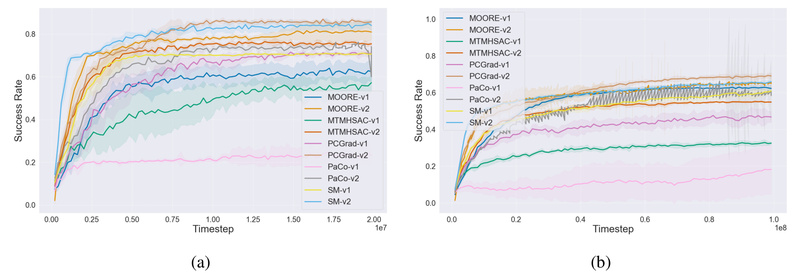
Evaluating reinforcement learning (RL) agents—especially those designed for multi-task or meta-learning scenarios—requires benchmarks that are consistent, well-documented, and technically accessible.…