Large AI models—from language generators to video diffusion systems—are bottlenecked by the attention mechanism, whose computational cost scales quadratically with…

Large AI models—from language generators to video diffusion systems—are bottlenecked by the attention mechanism, whose computational cost scales quadratically with…
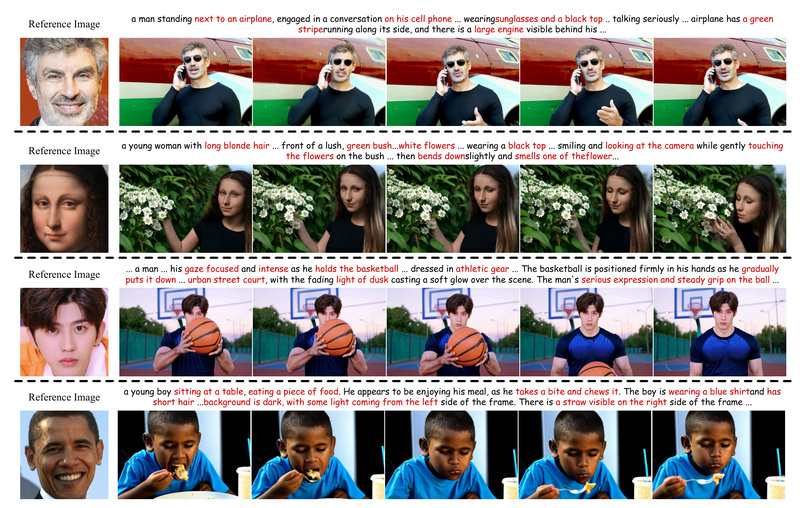
Creating videos that faithfully preserve a person’s identity from just a text prompt and a reference image has long been…
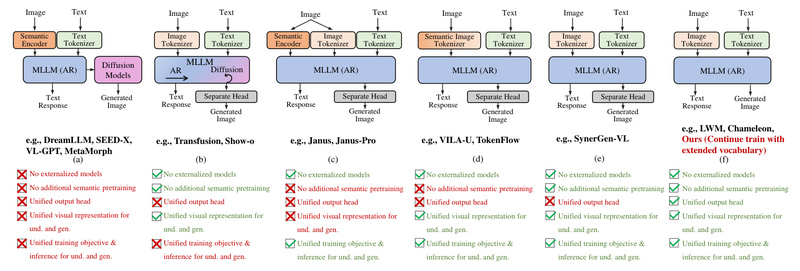
What if a single large language model (LLM) could both understand and generate high-quality images—without relying on external vision encoders…
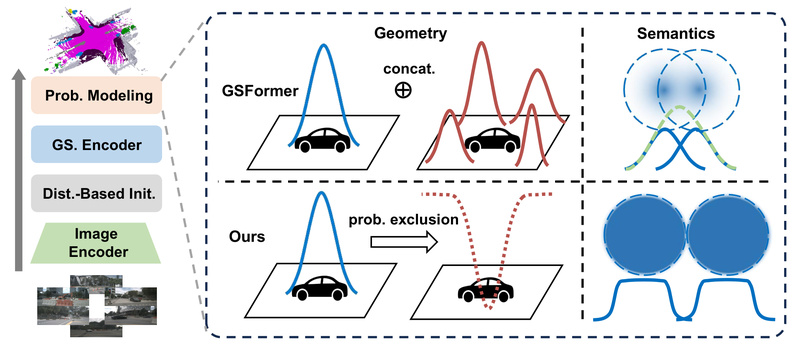
In autonomous driving systems that rely primarily on camera inputs—so-called vision-centric setups—accurately understanding the 3D structure and semantics of the…
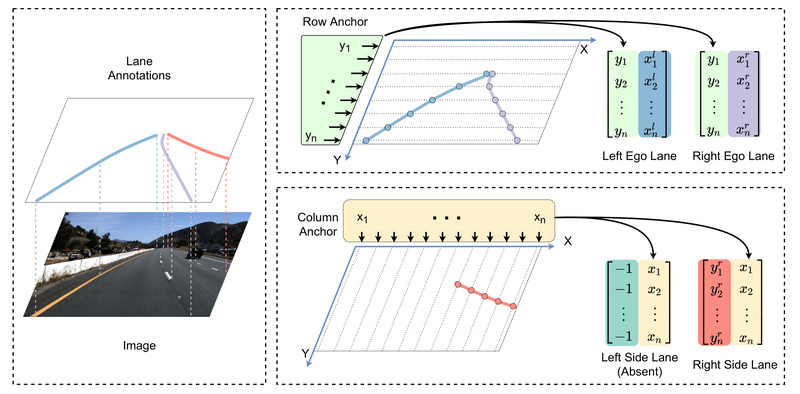
Lane detection is a foundational capability in autonomous driving and advanced driver-assistance systems (ADAS). Traditional approaches often rely on pixel-wise…
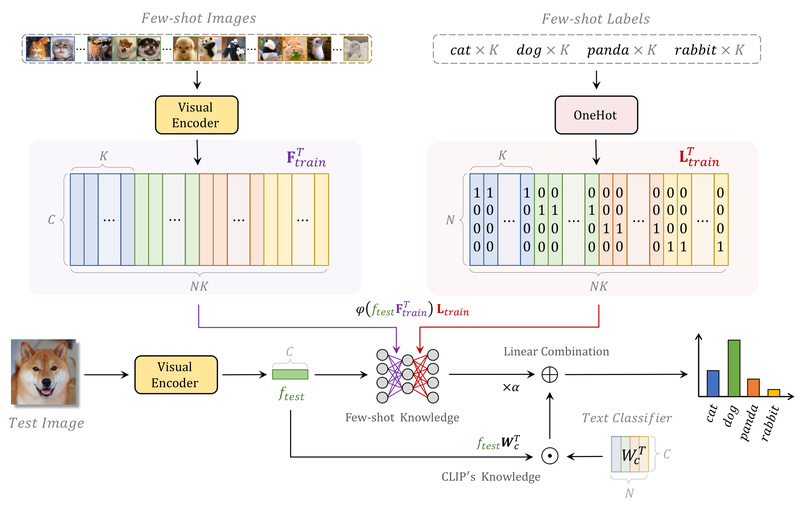
In the era of foundation models, CLIP (Contrastive Language–Image Pretraining) has revolutionized how we approach vision-language tasks—especially zero-shot image classification.…
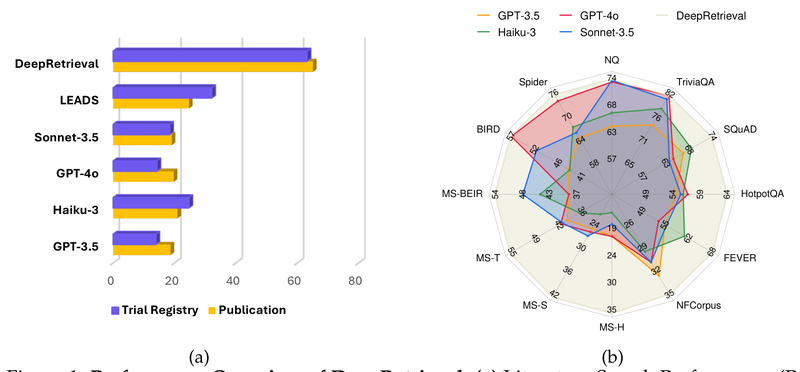
Imagine you’re building a retrieval-augmented generation (RAG) system, a scientific literature assistant, or a natural-language interface to a clinical trial…

For teams building AI-powered visual applications—whether in creative tools, digital content platforms, or rapid prototyping—the trade-off between image quality, speed,…

Keypoint detection—identifying specific, semantically meaningful points on objects like joints on a human body, facial landmarks on an animal, or…
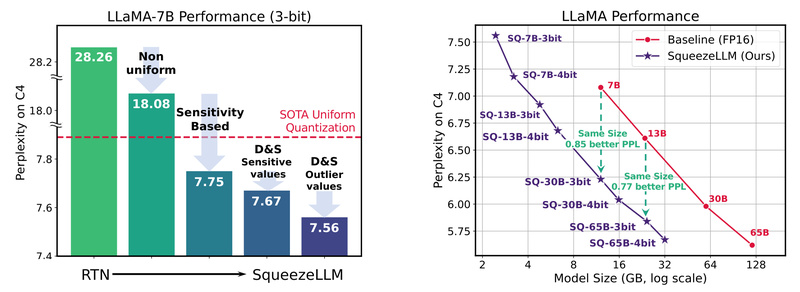
Deploying large language models (LLMs) like LLaMA, Mistral, or Vicuna often demands multiple high-end GPUs, complex inference pipelines, and substantial…