MobileSAM is a streamlined, high-performance variant of Meta’s groundbreaking Segment Anything Model (SAM), engineered to deliver the same powerful segmentation…

MobileSAM is a streamlined, high-performance variant of Meta’s groundbreaking Segment Anything Model (SAM), engineered to deliver the same powerful segmentation…

In today’s AI landscape, developers and researchers often juggle separate models for vision, language, and video—each with its own architecture,…
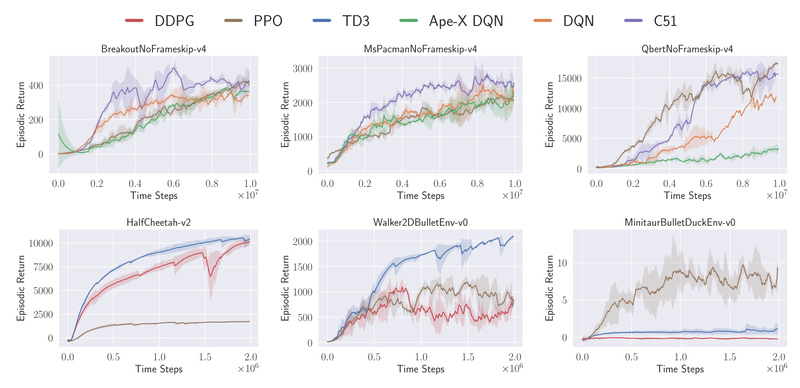
If you’ve ever tried to understand how a deep reinforcement learning (DRL) algorithm truly works—only to get lost in layers…
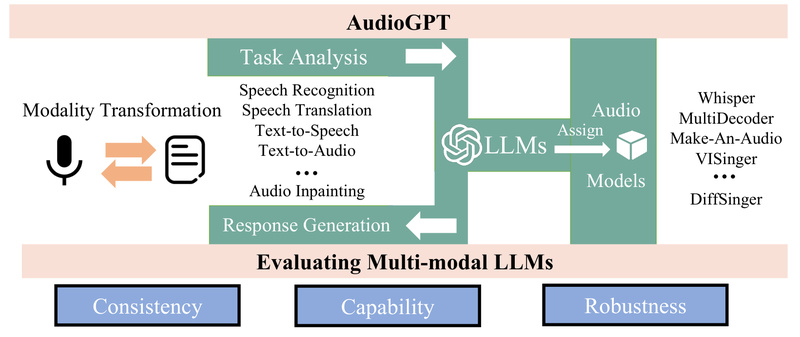
AudioGPT is a multimodal AI system that bridges the gap between large language models (LLMs) like ChatGPT and the rich…
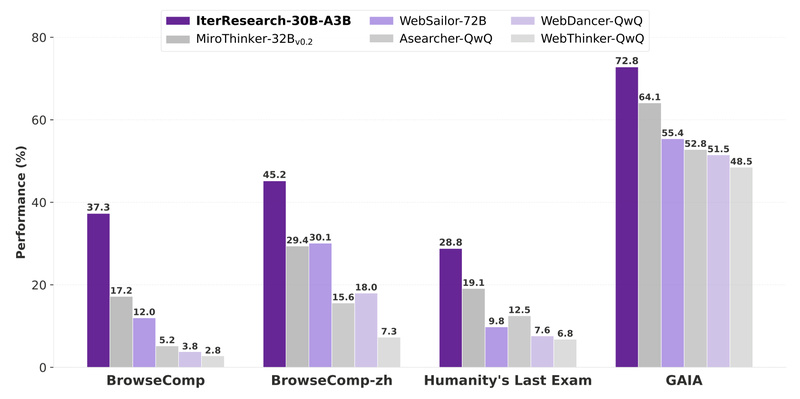
Long-horizon reasoning is one of the toughest challenges in current AI agent development. Traditional agentic systems, which rely on steadily…
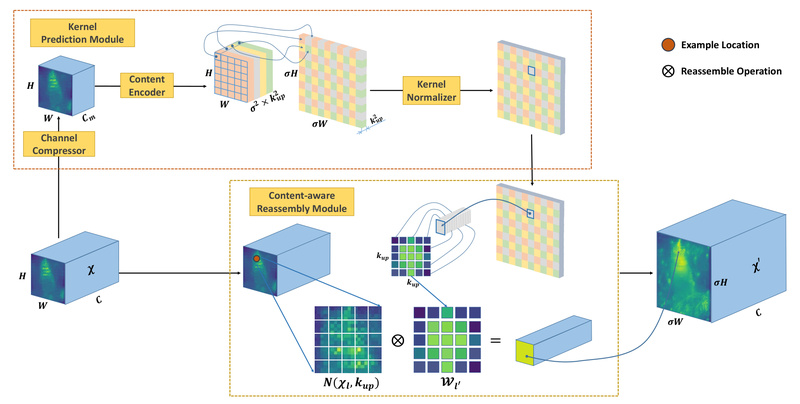
Feature upsampling is a critical but often overlooked component in modern computer vision pipelines. Whether you’re building an object detector,…
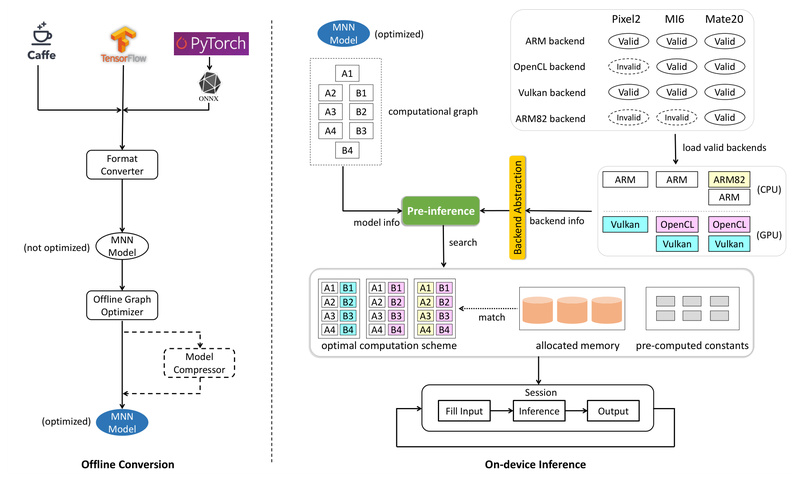
Mobile Neural Network (MNN) is an open-source, lightweight deep learning inference engine developed by Alibaba Group to bring powerful AI…
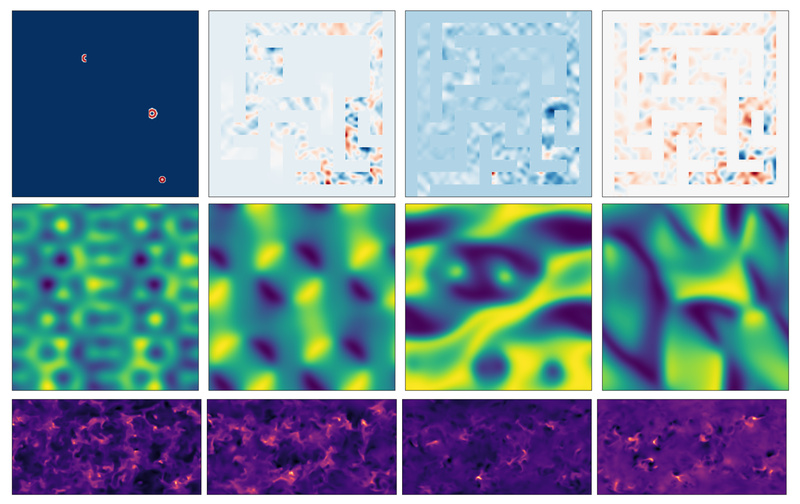
If you’re working on machine learning models that aim to emulate or accelerate physics-based simulations—whether in fluid dynamics, astrophysics, or…
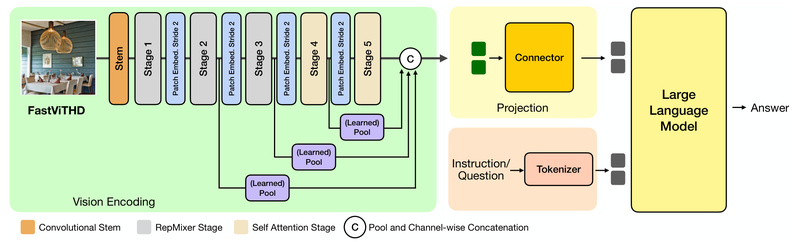
Vision Language Models (VLMs) are increasingly central to real-world applications—from mobile assistants that read documents to AI systems that interpret…
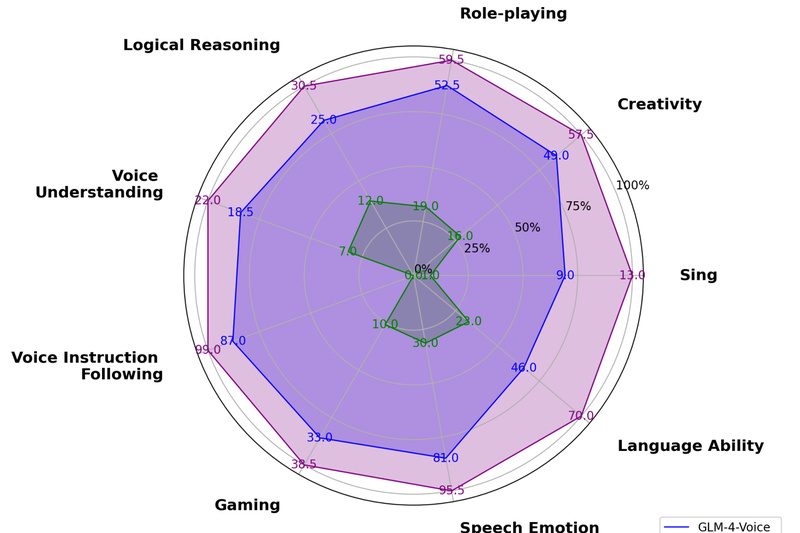
Building intelligent voice interfaces used to mean stitching together separate speech recognition (ASR), text generation, and text-to-speech (TTS) systems—each with…