Building speech language models (SpeechLMs)—systems that jointly understand and generate both speech and text—is rapidly becoming essential for next-generation voice…
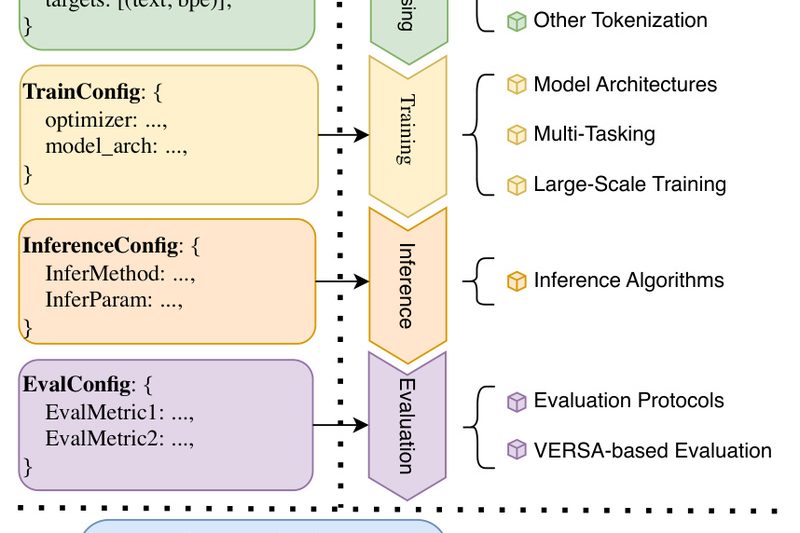
Building speech language models (SpeechLMs)—systems that jointly understand and generate both speech and text—is rapidly becoming essential for next-generation voice…
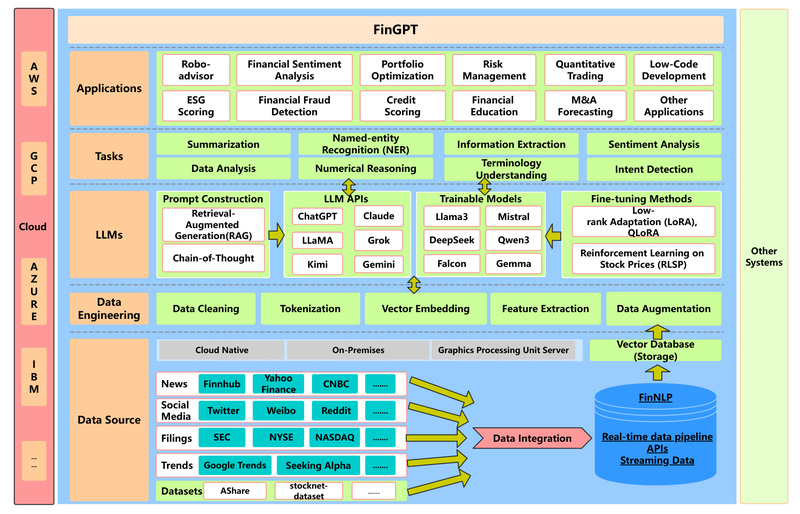
Large language models (LLMs) are transforming how we interact with data—but in finance, high-quality, domain-specific language models have largely remained…
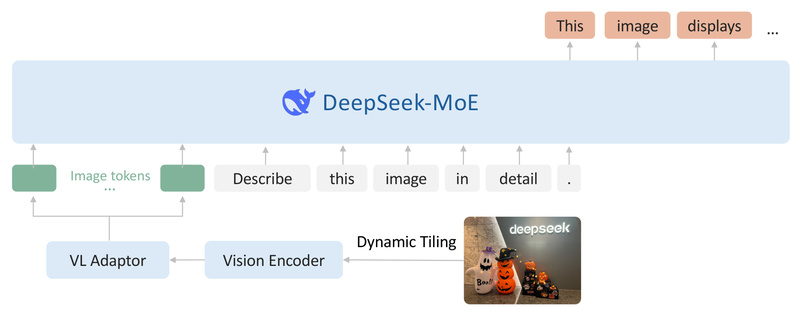
DeepSeek-VL2 is an open-source, advanced vision-language model (VLM) built on a Mixture-of-Experts (MoE) architecture, engineered for robust multimodal understanding across…
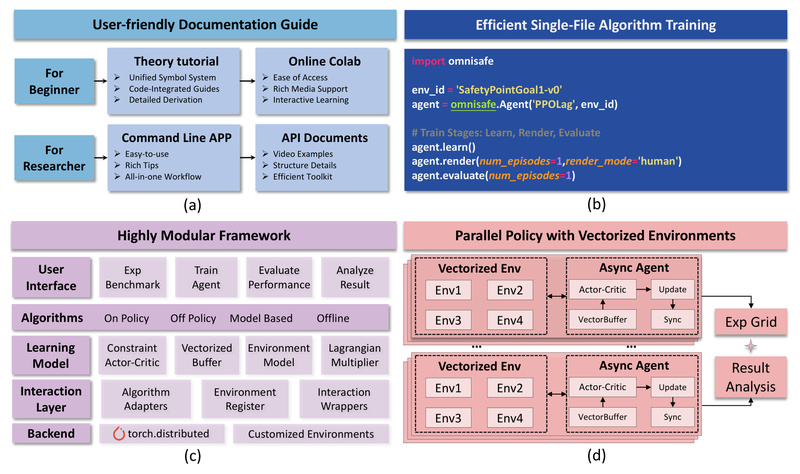
Reinforcement learning (RL) holds transformative potential for real-world applications—from autonomous vehicles and surgical robots to industrial control systems. Yet, one…

Text-to-image diffusion models have revolutionized creative workflows, but they still struggle with a fundamental limitation: global prompts alone often fail…
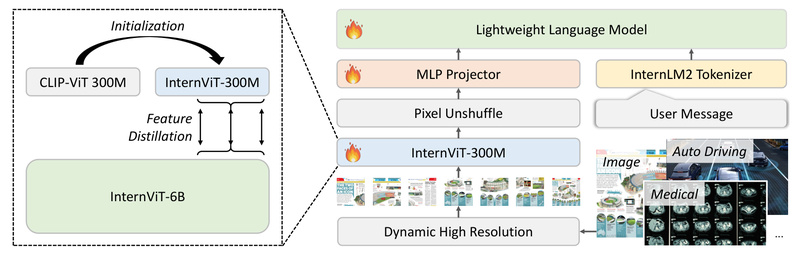
In an era where multimodal large language models (MLLMs) are rapidly advancing, a critical barrier remains: most high-performing vision-language models…

If you’ve spent time fine-tuning a Stable Diffusion model—perhaps with DreamBooth or LoRA—to generate your ideal character, product mockup, or…
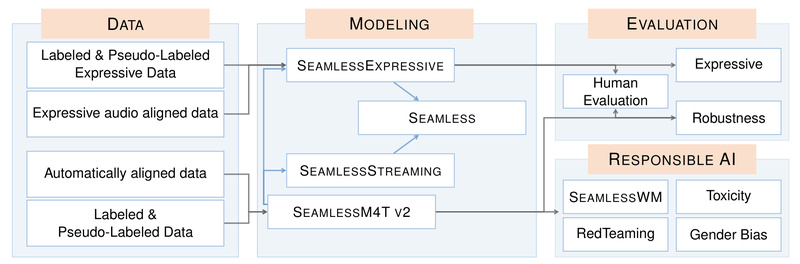
In today’s globalized world, real-time communication across languages remains a major bottleneck. Traditional speech translation systems often fall short—they output…

Creating videos with predictable, controllable motion has long been a major challenge in generative AI. While recent diffusion models produce…
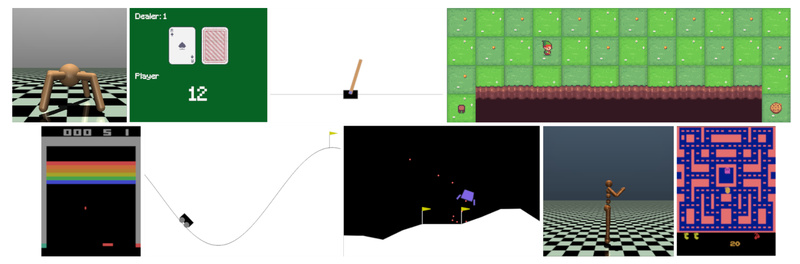
Reinforcement learning (RL) holds immense promise for solving complex decision-making problems—from robotics and game playing to resource optimization and autonomous…