Editing objects in existing videos while preserving their appearance across time has long been a challenge for diffusion-based models. While…
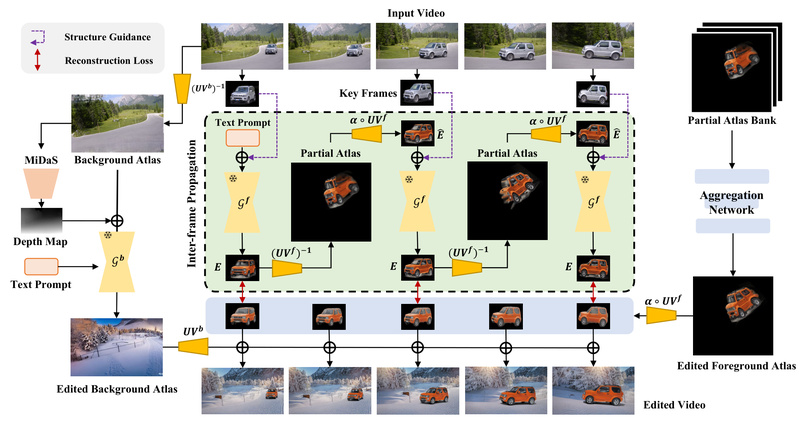
Editing objects in existing videos while preserving their appearance across time has long been a challenge for diffusion-based models. While…
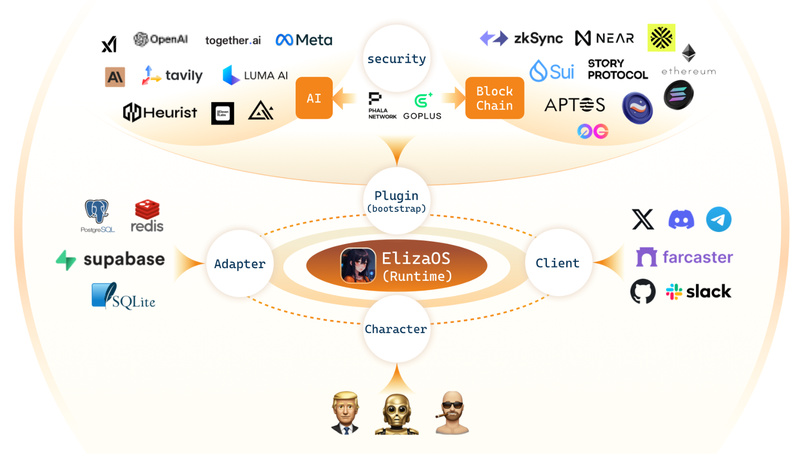
In today’s fast-evolving landscape of artificial intelligence and decentralized systems, developers increasingly need tools that bridge the gap between large…
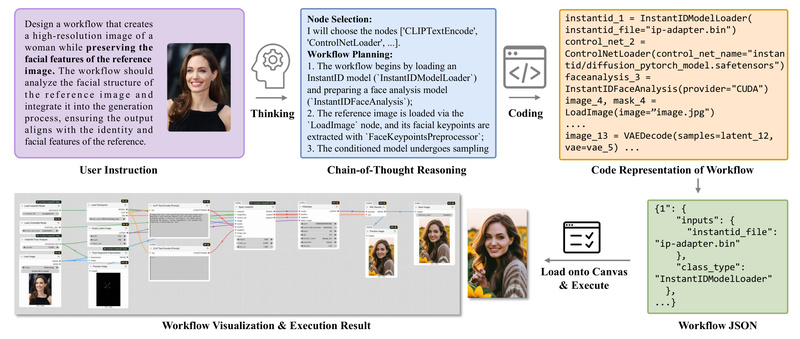
Building visual AI workflows in ComfyUI offers immense creative flexibility—but mastering its node-based interface demands significant expertise. Users often struggle…
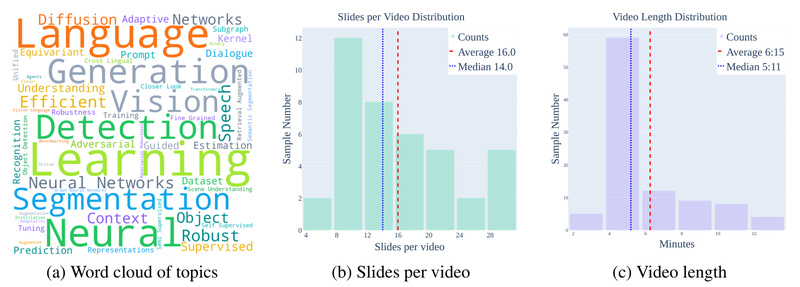
Creating high-quality academic presentation videos is notoriously time-consuming. Researchers often spend hours designing slides, recording voiceovers, editing footage, and syncing…
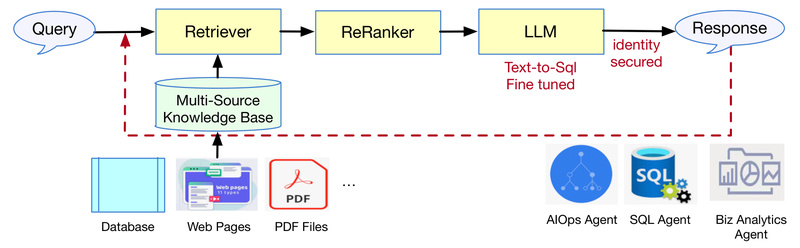
In today’s data-driven world, organizations are drowning in information—but starving for insights. Traditional database interfaces demand technical SQL knowledge, creating…
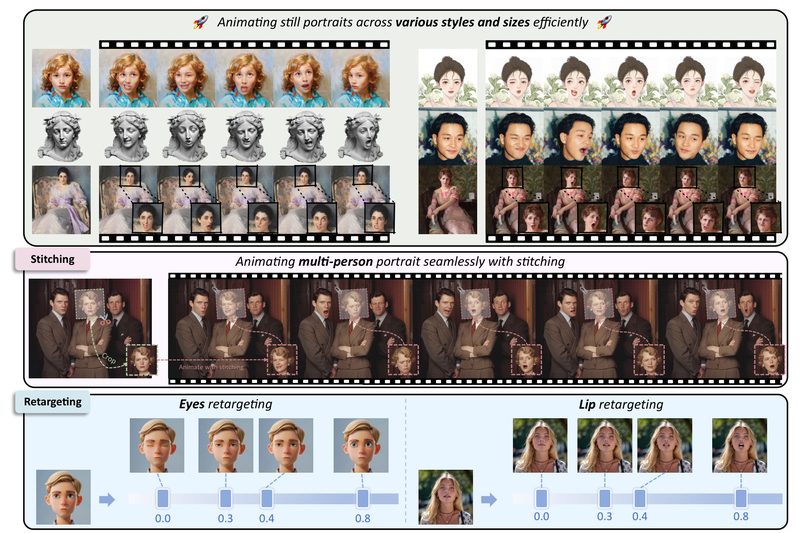
Animating a static portrait—whether a photo of a person or a pet—into a lifelike, expressive video has long been a…
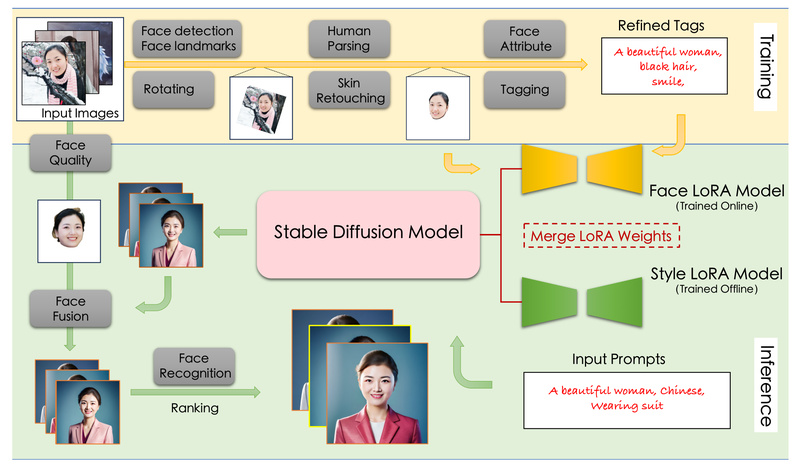
Creating realistic, personalized human portraits with AI has long been plagued by distorted features, poor identity retention, and complex workflows…

Transforming visual UI designs into functional front-end code has long been a bottleneck in software development. Designers craft mockups in…
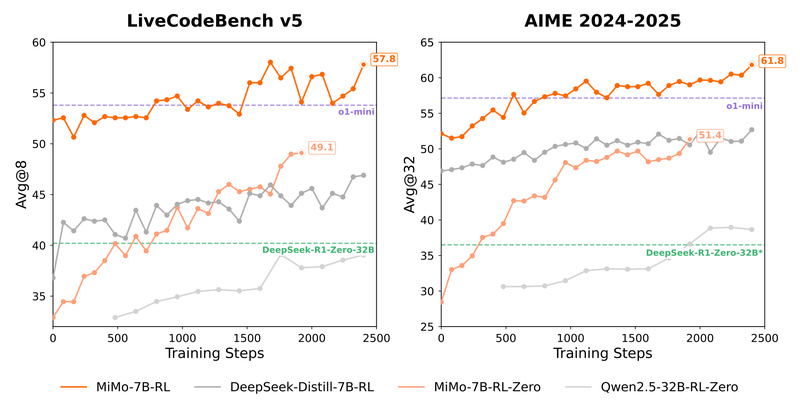
MiMo is a 7-billion-parameter language model purpose-built for reasoning-intensive tasks—spanning mathematics, code generation, and STEM problem solving—without the computational overhead…

OmniGen2 is an open-source, unified generative model that seamlessly bridges text and vision in a single architecture. Unlike many multimodal…