In today’s AI landscape, building systems that understand multiple types of data—text, images, audio, video, time series, and more—is increasingly…

In today’s AI landscape, building systems that understand multiple types of data—text, images, audio, video, time series, and more—is increasingly…
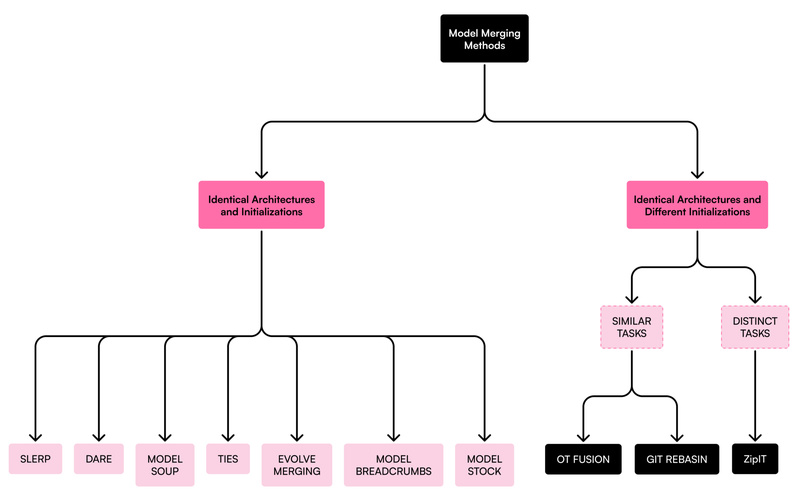
In today’s fast-moving landscape of open-source large language models (LLMs), developers and researchers are increasingly faced with a dilemma: dozens…

In clinical radiology, interpreting chest X-rays (CXRs) demands more than just identifying abnormalities—it requires synthesizing visual findings, clinical context, patient…
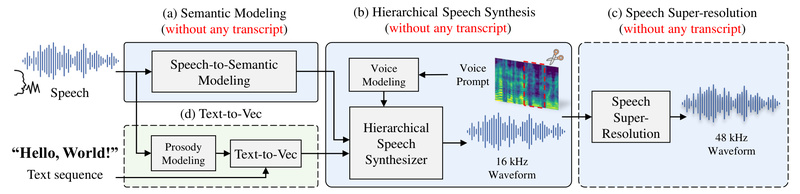
In the rapidly evolving field of speech synthesis, achieving natural-sounding, speaker-consistent voice generation without speaker-specific training data has long been…
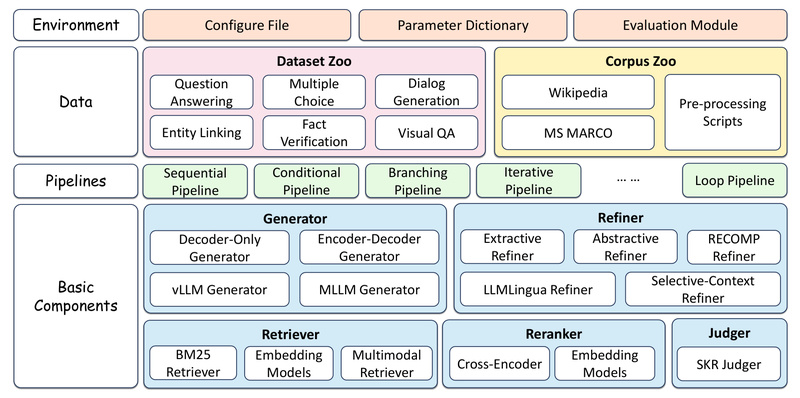
Retrieval-Augmented Generation (RAG) has emerged as a cornerstone technique for enhancing the factual grounding, knowledge scope, and reasoning capabilities of…

HunyuanVideo is a groundbreaking open-source video foundation model developed by Tencent, designed to deliver professional-grade video generation capabilities without the…
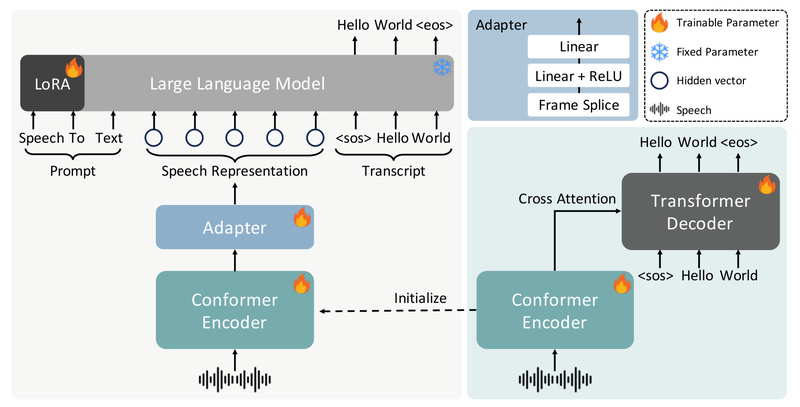
FireRedASR is an open-source, industrial-grade automatic speech recognition (ASR) system specifically engineered for Mandarin Chinese—but with strong capabilities in Chinese…
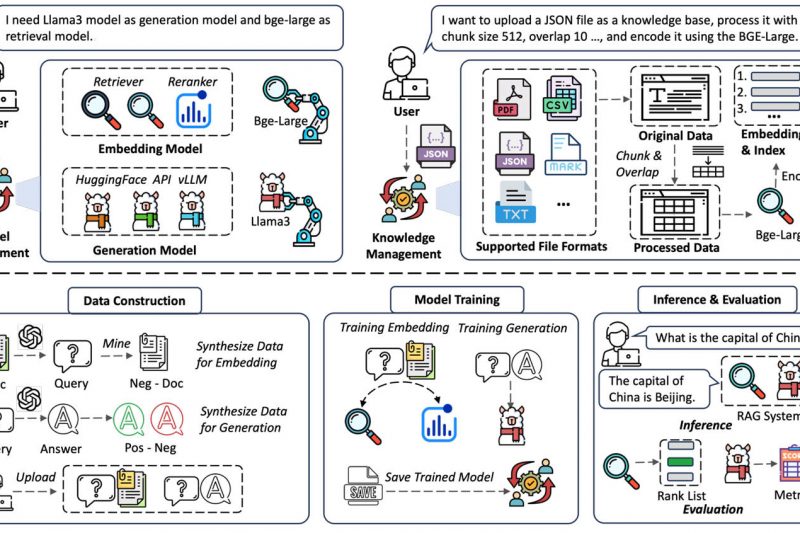
Retrieval-Augmented Generation (RAG) has become a cornerstone technique for grounding large language models (LLMs) in real-world knowledge. However, building effective…
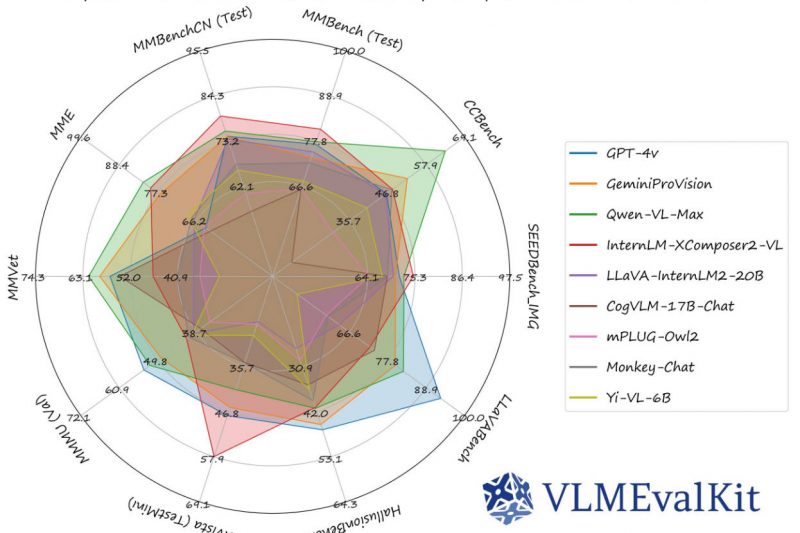
Evaluating large vision-language models (LVLMs) used to be a fragmented, time-consuming chore—juggling dozens of benchmark repositories, writing custom data loaders,…
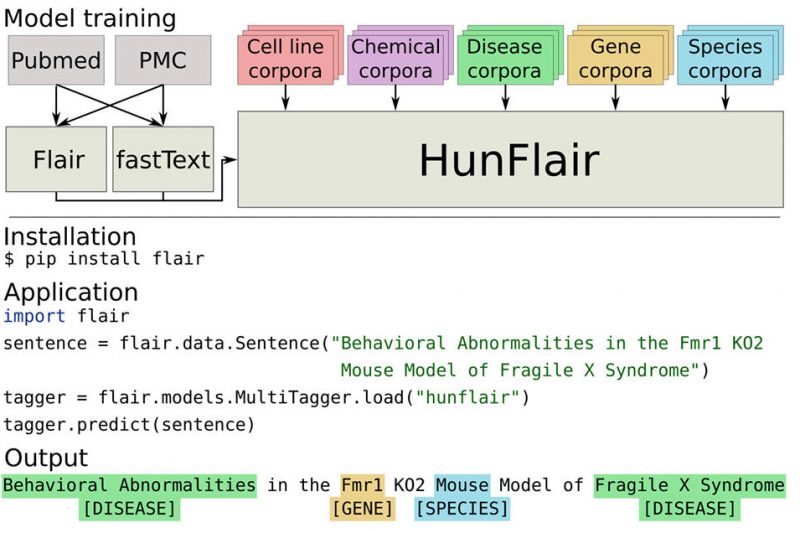
Biomedical text is dense with critical information—gene names, chemical compounds, diseases, species—but extracting that information manually is time-consuming and error-prone.…