MegActor represents a significant leap forward in portrait animation by directly leveraging raw driving videos—rather than simplified proxies like facial…

MegActor represents a significant leap forward in portrait animation by directly leveraging raw driving videos—rather than simplified proxies like facial…
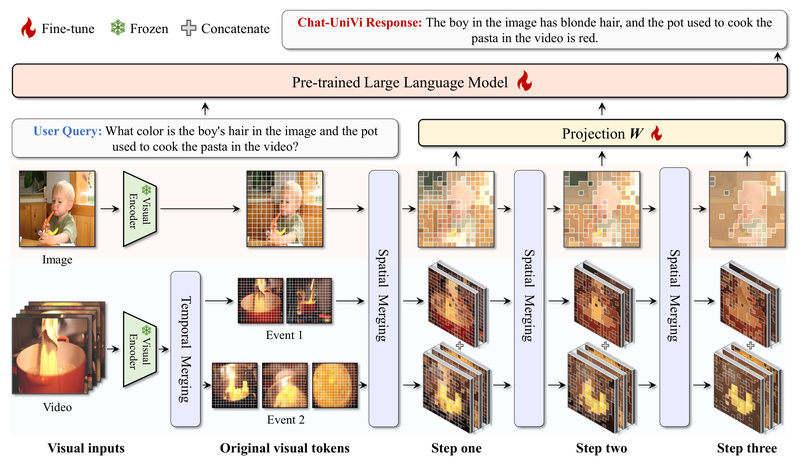
In today’s AI landscape, multimodal systems that understand both images and videos are increasingly essential—but most solutions force you to…
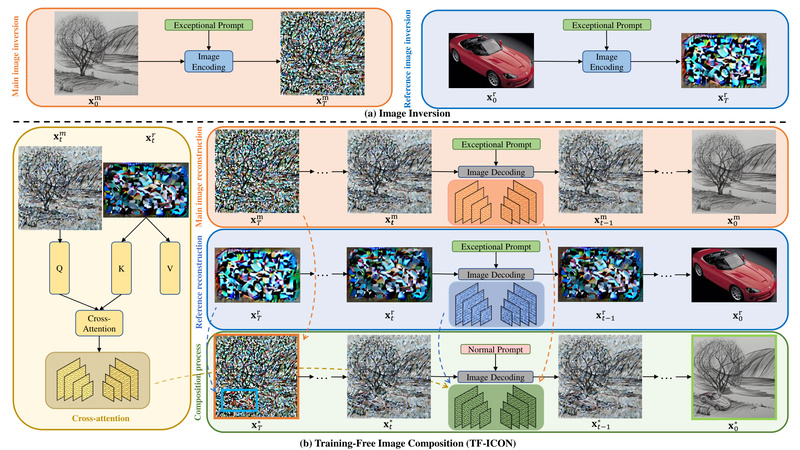
Image composition—seamlessly inserting a user-provided object into a new visual context—is a long-standing challenge in computer vision and generative AI.…
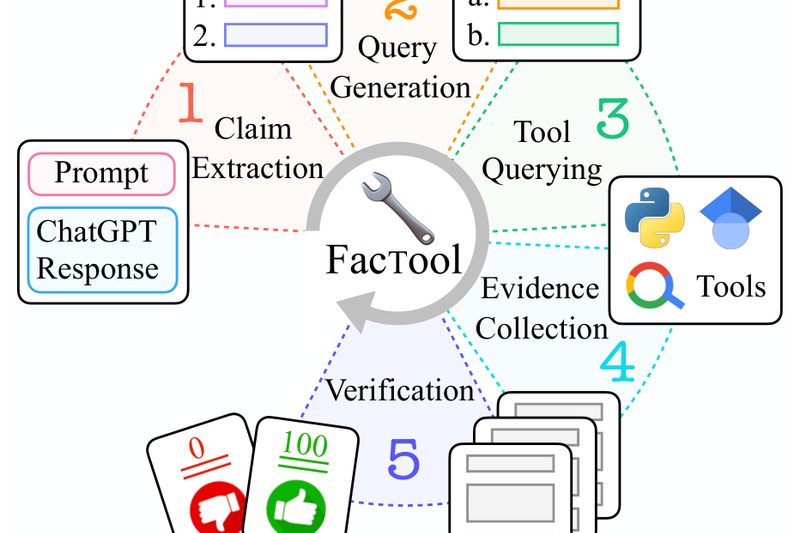
Large language models (LLMs) like ChatGPT and GPT-4 have transformed how we generate text, write code, solve math problems, and…
HQTrack is a powerful and practical framework designed to solve a persistent challenge in computer vision: accurately tracking and segmenting…
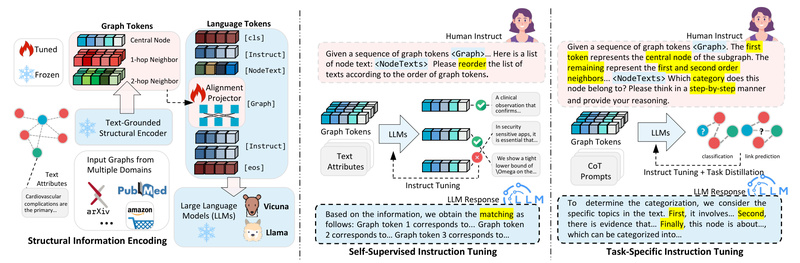
In today’s data-driven world, much of the most valuable information isn’t stored in tables or plain text—it lives in relationships.…

If you’re building AI-powered tools for the Chinese financial sector—whether for banking, fintech, investment research, or regulatory compliance—you’ve likely run…
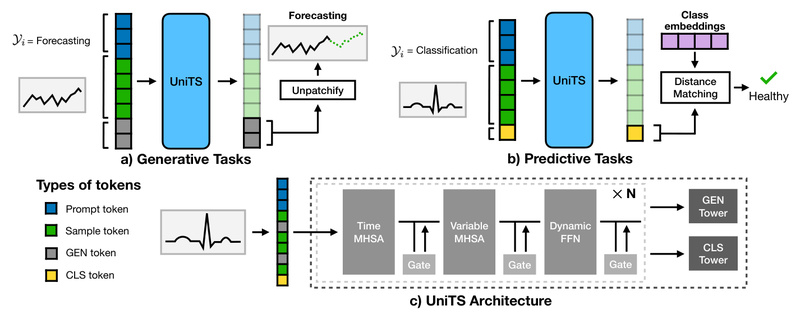
Time series data is everywhere—in financial markets, wearable health monitors, industrial sensors, and smart infrastructure. Yet, despite its ubiquity, building…
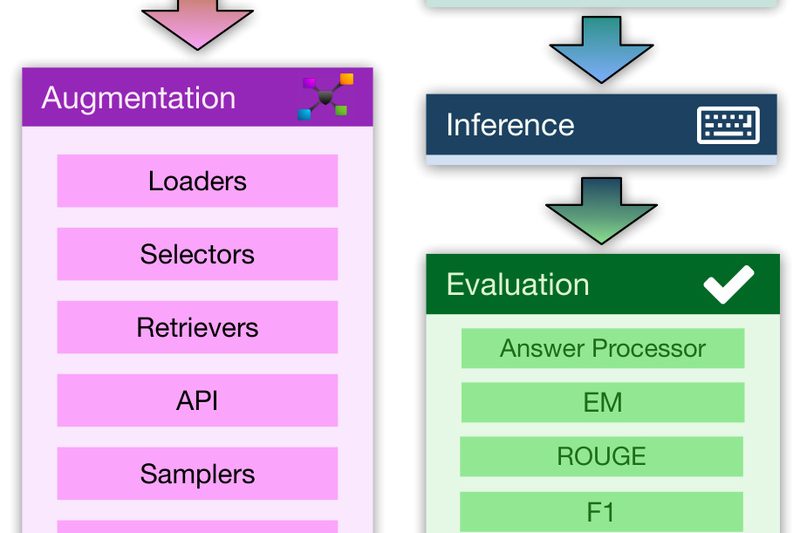
Building effective Retrieval-Augmented Generation (RAG) systems is notoriously difficult. Practitioners must juggle data preparation, retrieval integration, prompt engineering, model fine-tuning,…
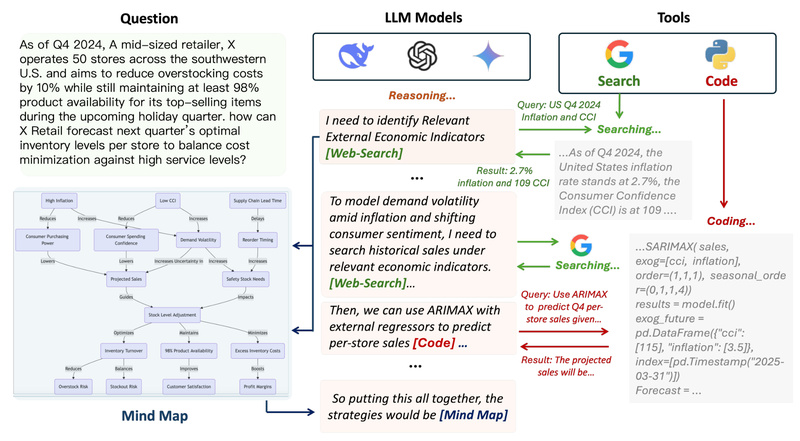
Large language models (LLMs) have made remarkable strides in generating coherent, context-aware responses. Yet, when it comes to complex, multi-step…