Reproducing results from machine learning (ML) research papers is often a frustrating experience. Despite the surge in published work, a significant portion of papers lack official code—forcing practitioners, students, and researchers to manually reverse-engineer implementations from equations, pseudocode, or vague descriptions. This slows down validation, adoption, and innovation across the ML ecosystem.
Enter Paper2Code, an open-source framework that bridges this gap by automatically generating complete, runnable code repositories directly from scientific papers in machine learning. Built around a novel multi-agent LLM architecture called PaperCoder, it doesn’t just spit out isolated code snippets—it produces structured, modular, and dependency-aware repositories that mirror real-world software engineering practices. Whether you’re a developer prototyping a new architecture or a professor preparing teaching materials, Paper2Code dramatically reduces the time and effort needed to go from paper to executable code.
How Paper2Code Solves the Reproducibility Crisis
Machine learning papers frequently omit implementation details critical for faithful reproduction—things like hyperparameter choices, data preprocessing steps, or module interdependencies. Even when code is eventually released, it’s often unstructured, undocumented, or tailored to a specific experiment setup.
Paper2Code tackles this head-on by interpreting the full context of a paper—its methodology, architecture diagrams, algorithm descriptions, and experimental setup—and translating it into a coherent software project. The system supports both PDFs (converted to structured JSON via S2ORC’s doc2json) and raw LaTeX source files, making it flexible for different input formats commonly used in academic publishing.
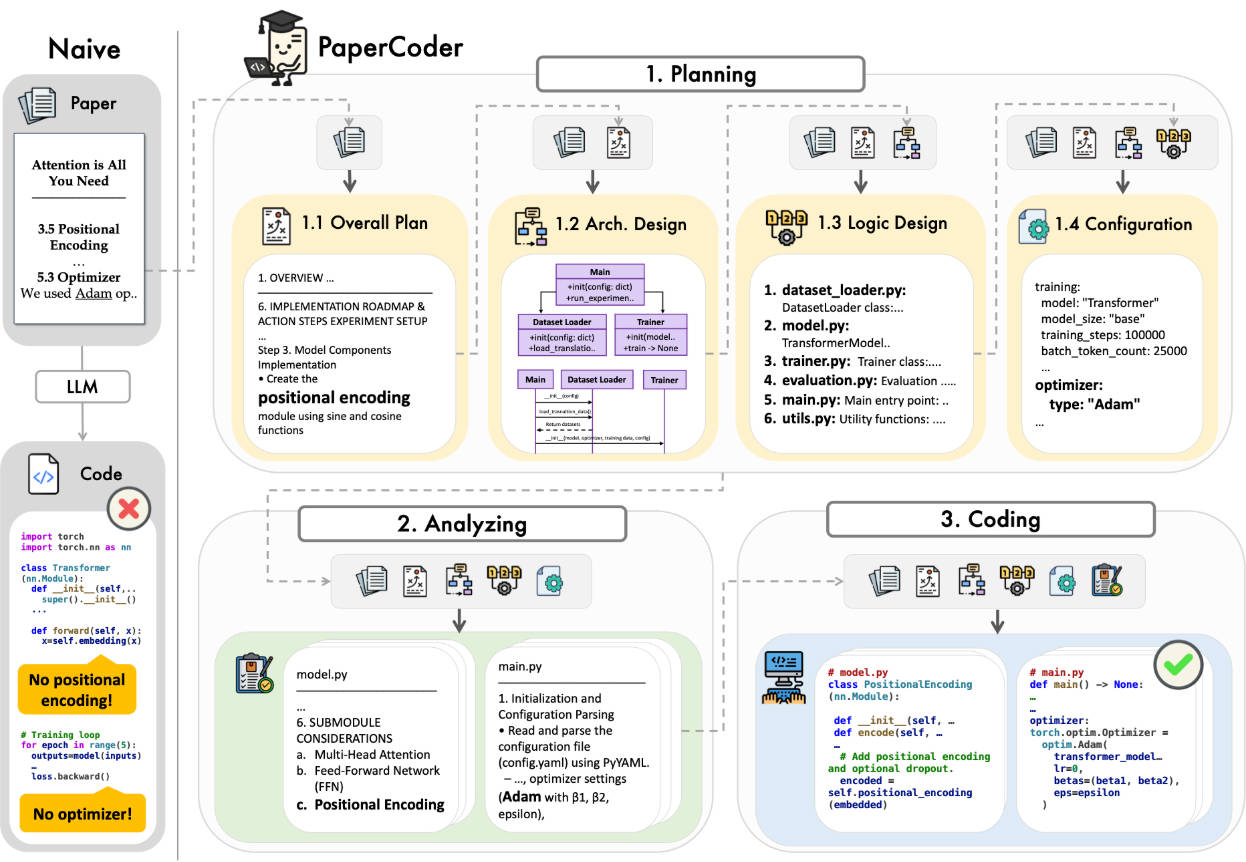
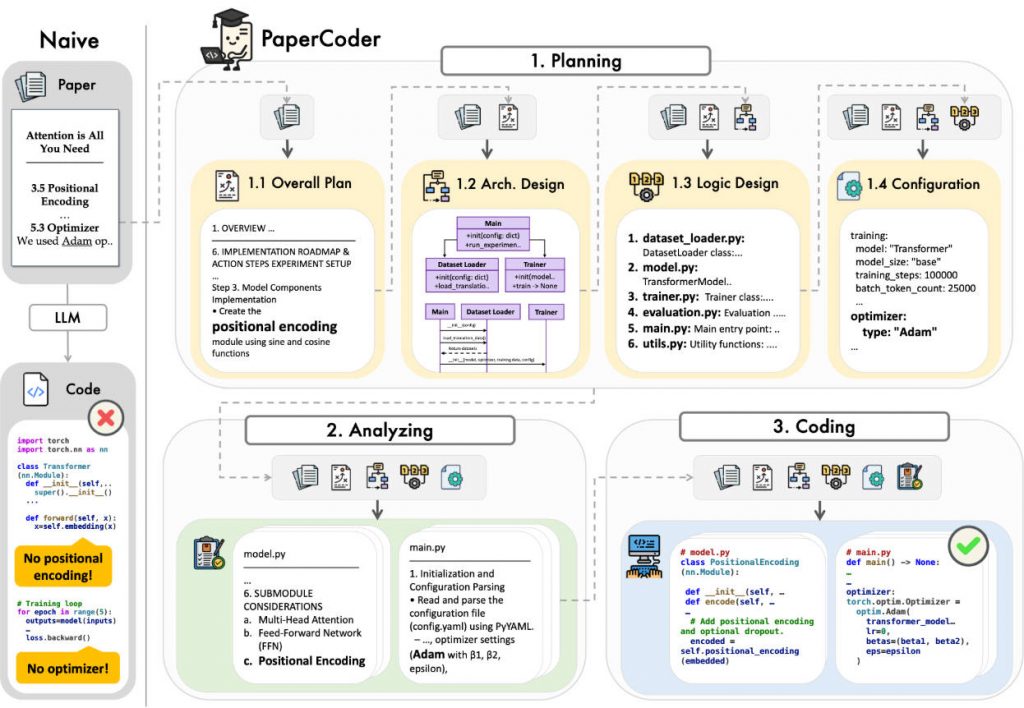
The Three-Stage Workflow: Planning, Analysis, Generation
At the heart of Paper2Code lies a human-like software development pipeline, executed collaboratively by specialized LLM agents:
Planning Stage
Before writing a single line of code, Paper2Code constructs a high-level system roadmap. This includes:
- Designing the overall architecture (e.g., encoder-decoder structure for Transformers)
- Mapping out file dependencies
- Generating configuration files (e.g.,
requirements.txt,setup.py) - Creating structural diagrams that guide later implementation
This stage ensures the final repository isn’t just functional but also well-organized—mirroring how a team of engineers would approach the task.
Analysis Stage
Here, the system dives into the paper’s implementation-critical details:
- Interpreting mathematical formulations and pseudocode
- Resolving ambiguities in layer definitions or training procedures
- Identifying required libraries and external dependencies
By focusing on semantics rather than surface-level text, Paper2Code captures the intent behind the research.
Code Generation Stage
Finally, modular, readable, and executable code is produced—complete with proper module separation, docstrings, and consistent naming. The output isn’t a monolithic script but a full Git-ready repository, ready for cloning, testing, and extension.
Why Paper2Code Stands Out
Several features distinguish Paper2Code from simpler code-generation tools:
- Multi-agent collaboration: Each stage uses purpose-built LLM agents that communicate and refine outputs iteratively, improving coherence and correctness.
- Repository-level generation: Unlike tools that output isolated functions, Paper2Code builds entire project structures—
models/,data/,train.py,eval.py, etc. - Benchmark-proven performance: It significantly outperforms strong baselines on both the Paper2Code and PaperBench benchmarks, with results validated not only by automated metrics but also by original paper authors when official code is available.
- Dual evaluation modes: Users can assess output quality via reference-based (against ground-truth author code) or reference-free (standalone critique) evaluation using built-in scripts.
Practical Use Cases
Paper2Code shines in real-world scenarios where speed, accuracy, and structure matter:
- Rapid prototyping: Test a novel attention mechanism or loss function within hours, not weeks.
- Research reproduction: Validate claims from recent NeurIPS or ICML papers without waiting for authors to release code.
- Education: Provide students with runnable implementations of classic papers like “Attention Is All You Need” to deepen understanding.
- Industrial R&D: Integrate cutting-edge academic ideas into internal pipelines when official implementations are missing or poorly maintained.
Getting Started in Minutes
You don’t need deep ML expertise to use Paper2Code. The setup is streamlined:
- Install dependencies: Choose either OpenAI’s API (
pip install openai) or open-source models via vLLM (pip install vllm). - Run a sample: Execute
bash scripts/run.sh(for OpenAI) orbash scripts/run_llm.sh(for DeepSeek-Coder) to generate a Transformer implementation from the seminal 2017 paper. - Explore the output: Find your complete repository in
outputs/Transformer_repo/, ready to run or modify.
Using OpenAI’s o3-mini model costs roughly \(0.50–\)0.70 per paper, while open-source models eliminate API fees at the cost of local GPU resources.
Limitations and Realistic Expectations
Paper2Code is powerful but not infallible:
- Ambiguous or underspecified papers may lead to incomplete or incorrect implementations.
- Generated code may require minor debugging or tuning—especially for papers that omit hyperparameters or dataset specifics.
- Open-source model runs demand sufficient local compute (e.g., 24GB+ VRAM for DeepSeek-Coder-V2-Lite-Instruct).
The system works best when the source paper includes clear algorithmic descriptions, architecture diagrams, or pseudocode—common in top-tier ML conferences.
How to Evaluate the Generated Code
Paper2Code includes built-in evaluation scripts to help you judge output quality:
- In reference-based mode, it compares your generated repo against the author’s official code (if available) and returns a 1–5 correctness score based on implementation fidelity.
- In reference-free mode, it uses LLM-based critique to assess logic, structure, and completeness without ground truth.
For example, running evaluation on the generated Transformer repo yields scores like 4.5/5, indicating high faithfulness to the original paper.
Summary
Paper2Code transforms the traditionally manual, error-prone process of turning ML research into code into an automated, structured, and scalable workflow. By leveraging collaborative LLM agents and a three-stage engineering-inspired pipeline, it delivers repositories that are not only functional but also maintainable and extensible. For practitioners tired of waiting for official code—or worse, reverse-engineering from blurry PDF equations—Paper2Code offers a reliable, open-source path from paper to production.