Searching for academic papers is a daily reality for researchers, engineers, and students—but traditional tools often fall short. Google Scholar returns fragmented results. ChatGPT and other LLMs struggle to deliver comprehensive coverage. Enter PaSa, an open-source LLM-powered agent developed by ByteDance that autonomously searches, reads, and selects relevant academic papers to answer complex scholarly queries with unprecedented recall and precision.
Unlike static keyword-based search engines, PaSa reasons like an expert researcher: it formulates targeted queries, fetches candidate papers, explores citation networks, and evaluates relevance based on your original request. Trained using reinforcement learning on high-quality synthetic data and evaluated on real-world queries from AI researchers, PaSa consistently outperforms Google, Google Scholar, ChatGPT (GPT-4o), and even a GPT-4o version of itself—by margins as large as 37.78% in recall@20.
If you’ve ever missed key papers in a literature review or spent hours chasing citations manually, PaSa was built to solve exactly those pain points.
How PaSa Works: A Two-Agent Architecture That Mimics Expert Research Behavior
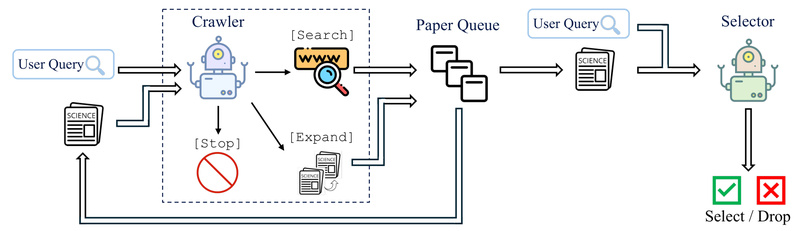
PaSa is not a single model—it’s a collaborative system of two specialized LLM agents: the Crawler and the Selector. This design mirrors how human researchers operate: one component explores the literature landscape, while the other judges relevance.
-
The Crawler takes your initial query and autonomously decides:
- When to invoke a web search with refined sub-queries,
- Which papers to fetch in full,
- Whether to expand into the reference list of a promising paper to uncover hidden gems.
All discovered papers are added to a shared queue.
-
The Selector then evaluates each paper in that queue—using only the title and abstract—to score its relevance to your original query. This filtering ensures high precision without requiring full-text reading of every candidate.
This iterative, agent-based workflow enables PaSa to go beyond keyword matching and capture nuanced, multi-faceted research needs.
Proven Performance on Real-World Academic Queries
PaSa was trained on AutoScholarQuery, a synthetic dataset of 35,000 fine-grained AI research questions paired with ground-truth papers from top conferences (e.g., NeurIPS, ACL, ICML). But its true test came with RealScholarQuery—a benchmark of 50 actual queries submitted by AI researchers.
The results are striking:
- PaSa-7B achieves 37.78% higher recall@20 and 39.90% higher recall@50 than "Google + GPT-4o" (where GPT-4o paraphrases the query for Google).
- It surpasses PaSa-GPT-4o (a version implemented purely by prompting GPT-4o within the same agent framework) by 30.36% in recall and 4.25% in precision—proving that a purpose-built, fine-tuned 7B model can outperform even the strongest commercial LLM when architected correctly.
- Using Crawler ensembles (running the Crawler twice) further boosts recall by over 3.5%, showing room for easy performance gains at inference time.
These metrics matter because recall directly correlates with how many relevant papers you actually find—a critical factor in literature reviews, grant writing, or avoiding redundant research.
Ideal Use Cases: When Should You Use PaSa?
PaSa excels in scenarios where comprehensiveness and accuracy are more important than speed or simplicity:
- Conducting systematic literature reviews on emerging or interdisciplinary AI topics.
- Exploring niche subfields where keyword searches return sparse or noisy results.
- Answering complex, multi-part research questions (e.g., “Find recent papers that combine diffusion models with reinforcement learning for robotics, and cite foundational works in both areas”).
- Discovering hidden gems through intelligent citation expansion—not just top-ranked search hits.
While PaSa is currently optimized for AI and computer science papers (due to its training data), its agent-based architecture is general and could be adapted to other domains with appropriate data.
Getting Started: Try PaSa in Seconds or Deploy Locally
You don’t need to write a single line of code to try PaSa. Simply:
- Visit https://pasa-agent.ai
- Describe your research need in plain English (e.g., “I’m looking for papers on efficient fine-tuning of large language models using low-rank adapters”)
- Let PaSa autonomously search, read, and rank results for you.
For advanced users, the full codebase, models (PaSa-7B Crawler and Selector), and datasets are open-sourced on GitHub (https://github.com/bytedance/pasa). Local deployment requires:
- A Google Search API key (from serper.dev) for web searches
- Access to arXiv/ar5iv APIs for paper retrieval
- Standard Python/PyTorch environment with FlashAttention support
The repo also includes scripts for supervised fine-tuning (SFT) and PPO-based reinforcement learning, enabling you to train your own domain-specific version.
Limitations and Practical Considerations
While powerful, PaSa has realistic boundaries:
- Domain focus: Trained primarily on AI conference papers; performance may degrade in biology, economics, or humanities.
- Query dependency: Like any LLM system, output quality depends on how clearly you articulate your needs. Vague prompts yield less precise results.
- API reliance: Local runs require external search APIs, which may incur costs or rate limits.
- No full-text indexing: The Selector currently uses only title and abstract, which is standard but may miss nuanced contributions in the body.
That said, these are trade-offs for a system that maximizes recall while maintaining deployability—a balance few academic search tools achieve.
Summary
PaSa redefines academic search by replacing passive keyword lookups with an autonomous, reasoning-capable agent that actively explores the scholarly landscape on your behalf. Backed by rigorous evaluation on real researcher queries and open-sourced for transparency and extension, it delivers significantly higher recall than Google Scholar, ChatGPT, or even GPT-4o-based agents—all with a compact 7B-parameter model.
For AI practitioners, graduate students, or research engineers tired of missing critical papers in their field, PaSa offers a smarter, more thorough alternative. Try it today at https://pasa-agent.ai—and consider integrating the agent framework into your own research pipelines via GitHub.