If you’re working to improve large language models (LLMs) on hard reasoning tasks—like math problem solving or competitive programming—you’ve likely hit a wall with standard reinforcement learning (RL) approaches. Traditional RL methods rely on sparse, outcome-only rewards (e.g., “correct” or “incorrect” at the end), which offer little guidance during multi-step reasoning. Meanwhile, dense process rewards—assigning feedback at every reasoning step—sound ideal, but require expensive, human-annotated intermediate labels that rarely exist at scale.
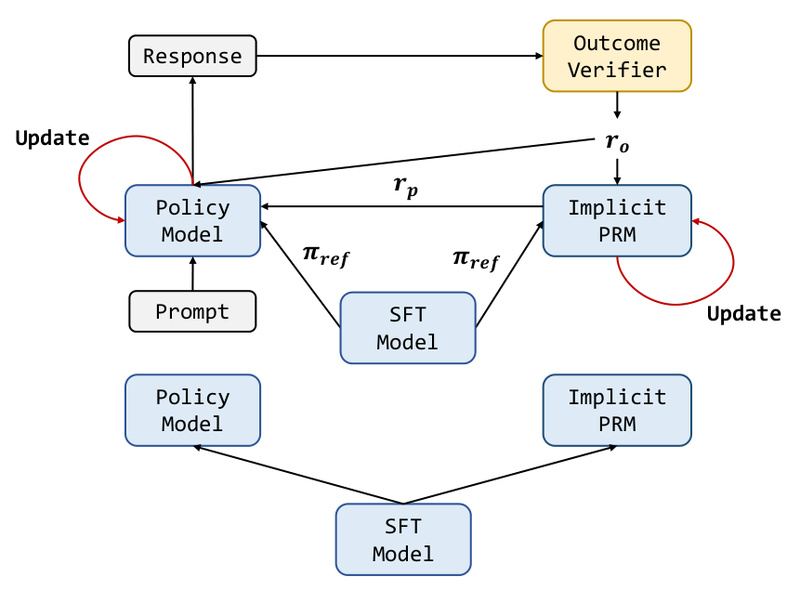
Enter PRIME (Process Reinforcement through Implicit Rewards): an open-source RL framework that sidesteps this bottleneck entirely. PRIME enables online, token-level reward signals using only final outcome labels—like whether a math answer is right or a code snippet passes unit tests—without any labeled reasoning steps. By treating the supervised fine-tuned (SFT) model itself as an implicit process reward model (PRM), PRIME delivers dense, scalable, and practical reinforcement learning for complex reasoning, all while cutting development overhead.
For project leads, researchers, and technical decision-makers, PRIME offers a rare combination: stronger reasoning performance, reduced data requirements, and simpler infrastructure—making advanced RL feasible even without massive annotation budgets.
How PRIME Solves the Reward Sparsity Problem
In conventional LLM RL pipelines, a separate reward model is trained to score model outputs—often only at the final step. This leads to two well-known issues:
- Sparse feedback: The model receives no signal about which reasoning steps were helpful or flawed.
- Credit assignment difficulty: It’s hard to know which tokens contributed to a correct (or incorrect) final answer.
PRIME tackles both by generating implicit process rewards directly from the language model. Here’s how it works:
- No dedicated reward model needed: The SFT model (e.g., Qwen2.5-Math-7B-Base) doubles as both the policy and the initial PRM.
- Token-level rewards from outcome labels: Given a rollout (a full model response) and a binary outcome label (e.g., “answer correct”), PRIME back-propagates implicit rewards to each token in the sequence—effectively learning a Q-function over the reasoning trajectory.
- Online updates: Both the PRM and the policy are updated iteratively using only on-policy rollouts and final verifiers—no offline reward modeling phase required.
This design eliminates the need for costly process-labeled datasets, which are often the biggest barrier to deploying process-based RL in real projects.
Key Technical Advantages
PRIME stands out for four practical reasons that matter to engineering and research teams:
1. Dense Feedback Without Extra Infrastructure
Unlike methods that require training a separate value network or reward model, PRIME leverages the SFT model’s own logits to derive per-token rewards. This means you get dense guidance across the entire reasoning chain—without adding new components to your training pipeline.
2. Scalable Online Learning
Because PRIME updates the implicit PRM using only outcome labels (which are cheap to obtain via automated verifiers), it scales naturally with more rollouts. This avoids the distribution shift that plagues offline reward models trained on static datasets.
3. Compatibility with Standard RL Algorithms
PRIME integrates smoothly with established techniques like PPO (Proximal Policy Optimization) and RLOO (Reward Leave-One-Out). Its advantage estimation combines both outcome and process rewards, enabling stable and efficient policy updates.
4. Strong Empirical Results with Less Data
Starting from Qwen2.5-Math-7B-Base, PRIME achieves a 16.7% average improvement over the SFT baseline across major reasoning benchmarks—including a 27.7-point jump on AMC and 23.3-point gain on AIME 2024. Remarkably, the final model Eurus-2-7B-PRIME outperforms Qwen2.5-Math-7B-Instruct—a model trained with 10× more SFT data and a 72B reward model—using only open-source data and zero process labels.
Ideal Use Cases for Technical Teams
PRIME is particularly well-suited for domains where:
- Tasks involve multi-step reasoning (e.g., deriving a proof, writing an algorithm).
- Final answers can be automatically verified (e.g., via unit tests for code, symbolic solvers for math).
- Step-by-step human annotations are unavailable or prohibitively expensive.
Examples include:
- Competitive programming platforms (e.g., Codeforces, LeetCode) where test cases serve as outcome verifiers.
- Mathematical reasoning systems that use solvers like SymPy to check final answers.
- Automated tutoring or homework-assist tools that need to guide models through structured problem-solving without gold intermediate steps.
If your project falls into these categories—and you already have a decent SFT model—PRIME offers a clear path to significant performance gains with minimal new data collection.
Getting Started: Practical Integration Steps
The PRIME codebase is fully open-source and includes everything needed for training, evaluation, and inference:
- Start with a capable base model: The authors used Qwen2.5-Math-7B-Base, but other reasoning-capable LLMs may work with adaptation.
- Format prompts consistently:
- For math: Append
"Present the answer in LaTeX format: boxed{Your answer}" - For coding: Append
"Write Python code to solve the problem. Present the code in n```pythonnYour coden```n at the end."
- For math: Append
- Run inference with vLLM: The provided example shows how to generate responses using
vLLMwith chat templating. - Launch RL training: Use the
training/anddata_preprocessing/scripts to run the PRIME loop—rollouts, implicit reward calculation, PRM update, and policy optimization. - Evaluate: Reproduce benchmark results using the
eval/scripts against standard datasets like MATH-500 or LiveCodeBench.
All models, code, and preprocessing tools are available on GitHub and Hugging Face, making replication straightforward for teams with basic LLM fine-tuning experience.
Limitations and Considerations
While powerful, PRIME isn’t a universal drop-in solution:
- Domain dependency: Its current success is concentrated in math and coding, where reliable automated verifiers exist. Applying it to open-ended domains (e.g., creative writing, dialogue) would require robust outcome reward mechanisms that may not be readily available.
- Verifier quality matters: PRIME’s performance hinges on accurate outcome labels. Noisy or incomplete verifiers (e.g., partial test coverage) can degrade training.
- Compute requirements: Although it reduces data overhead, PRIME still involves online RL with multiple rollouts per prompt—requiring GPU clusters for large-scale runs.
That said, for teams already operating in verifiable reasoning domains, these constraints are often already part of their workflow.
Summary
PRIME reimagines how we apply reinforcement learning to reasoning-intensive LLM tasks. By deriving dense, token-level rewards from final outcomes alone, it removes the biggest roadblock to process-based RL: the need for expensive step-labeled data. With strong results on math and coding benchmarks, seamless integration with standard RL algorithms, and a fully open implementation, PRIME offers a practical, scalable path to more capable reasoning models—without the usual data or infrastructure overhead.
If your project demands better multi-step reasoning from LLMs and you have access to automated answer verification, PRIME is a compelling next step to explore.