Managing complex tasks with large language models (LLMs) often hits a ceiling: while single models excel at narrow tasks, scaling to multi-step reasoning, external tool use, or dynamic decision-making quickly exposes limitations in coordination, efficiency, and adaptability. Traditional multi-agent systems attempt to overcome this by assigning static roles to agents—yet they struggle when tasks evolve or require flexible re-prioritization.
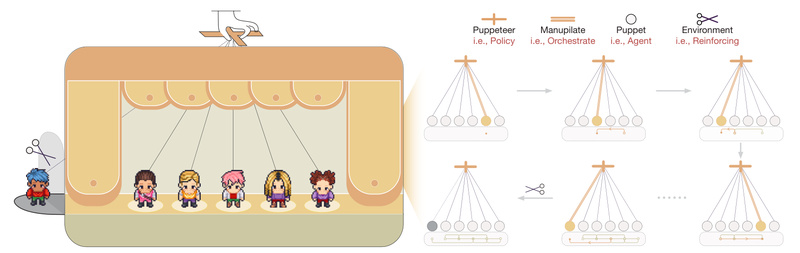
Enter Puppeteer, a novel framework from OpenBMB that reimagines multi-agent collaboration through a centralized, learnable orchestrator—an intelligent “puppeteer” that dynamically directs a team of specialized agents (“puppets”) in real time. Trained via reinforcement learning, this orchestrator doesn’t follow rigid scripts. Instead, it adapts the sequence, priority, and type of agents based on the current state of the task, enabling compact, cyclic, and cost-efficient reasoning pathways.
Puppeteer isn’t just another multi-agent wrapper—it’s a paradigm shift toward evolvable, scalable, and resource-conscious LLM collaboration, designed specifically for technical decision-makers who need reliable automation for complex, real-world workflows.
Why Static Multi-Agent Systems Fall Short
Most existing multi-agent frameworks assume fixed team structures: one agent plans, another critiques, a third executes code, and so on. While functional for simple pipelines, this rigidity becomes a bottleneck as task complexity grows. Coordination overhead increases, redundant reasoning loops emerge, and the system can’t gracefully adapt when new information arrives or when certain agents become irrelevant.
Worse, these systems often lack intelligent termination logic—leading to over-processing or premature conclusions. They also treat all actions equally, failing to penalize costly operations (like web searches) or reward concise, high-value reasoning steps. The result? Higher latency, increased API costs, and unpredictable performance on open-domain problems.
How Puppeteer Solves Real Coordination Problems
Puppeteer addresses these pain points through four key innovations:
1. A Reinforcement-Learned Orchestrator That Evolves with the Task
At the heart of Puppeteer is a centralized orchestrator trained using reinforcement learning. Rather than hardcoding agent workflows, the orchestrator learns to:
- Select which agent acts next,
- Determine whether to spawn new agents or reuse existing ones,
- Decide when to terminate the process based on progress signals.
This dynamic sequencing reduces redundant steps and fosters the emergence of compact reasoning cycles—a pattern observed in experiments where Puppeteer outperforms static baselines while using fewer computational resources.
2. Dual Agent Types: Tool Users and Pure Reasoners
Puppeteer cleanly separates agents into two categories:
-
Tool-using agents can perform external actions like:
- Searching Bing or arXiv,
- Accessing websites,
- Executing Python code,
- Reading local files.
-
Reasoning-only agents focus on internal cognitive tasks:
- Logical reasoning,
- Critique and reflection,
- Question decomposition,
- Planning and summarization.
This separation ensures that expensive external calls are only made when necessary, while internal reasoning remains lightweight and focused.
3. Built-In Termination Logic
A dedicated termination agent evaluates whether the current state warrants ending the task. This prevents infinite loops or unnecessary continuation—critical for production-grade reliability. The orchestrator is explicitly rewarded for correct termination (via a +0.5 reward factor), ensuring the system learns to conclude efficiently.
4. Cost-Aware Reward Design
Puppeteer’s training incorporates explicit cost modeling:
- Web search actions incur a penalty (−1.5), discouraging frivolous queries,
- Each reasoning step carries a small base cost (scaled by 0.1),
- Future rewards are discounted (γ = 0.99), prioritizing near-term progress.
This design aligns agent behavior with real-world constraints like API budgets and latency targets.
Ideal Use Cases for Technical Decision-Makers
Puppeteer shines in scenarios that demand adaptability, tool integration, and structured reasoning:
- Complex QA and Benchmarking: Tasks like MMLU-Pro, which require multi-hop reasoning, benefit from Puppeteer’s dynamic agent sequencing. In evaluations, Puppeteer achieves higher accuracy with fewer steps.
- Research Automation: Automating literature reviews, data extraction, or hypothesis validation—where agents can search arXiv, run analysis scripts, and synthesize findings—without manual workflow scripting.
- Dynamic Problem-Solving Pipelines: Situations where the solution path isn’t known in advance (e.g., debugging a novel system failure) benefit from Puppeteer’s ability to pivot strategies on the fly.
- Cost-Sensitive Deployments: Teams managing LLM API budgets can leverage Puppeteer’s cost-aware orchestration to minimize expensive operations while maintaining performance.
Engineering leads, R&D teams, and AI product managers will find Puppeteer particularly valuable for building autonomous, self-optimizing agent systems that evolve with task demands.
Getting Started: From Zero to Running in Minutes
Puppeteer is designed for rapid adoption:
-
Clone and set up
git clone -b puppeteer https://github.com/OpenBMB/ChatDev cd ChatDev/puppeteer conda create -n puppeteer_env python=3.11 && conda activate puppeteer_env pip install -r requirements.txt
-
Configure API access
Editconfig/global.yamlto add your OpenAI API key, Bing key (optional), and file paths. -
Run a task
python main.py MMLU-Pro validation --data_limit 10
This executes a validation run on 10 MMLU-Pro questions using the default GPT-4o backend and preconfigured agent personas.
Customization Without Overhead
Need a new action? Extend the system by:
- Adding a new tool or reasoning prompt,
- Modifying
reasoning_agent.pyto integrate it, - Or creating a multi-action agent by subclassing
agent.py.
New base models? Just update model_config.py. Puppeteer balances structure with flexibility—so you prototype fast without sacrificing control.
Limitations and Practical Considerations
While powerful, Puppeteer has current constraints to consider:
- Base model size: The default orchestrator uses
nvidia/Llama-3.1-Nemotron-70B-Reward, a 70B-parameter reward model. While inference can run via API, local deployment demands significant GPU memory. - API dependency: Agent reasoning currently relies on external LLM providers (e.g., OpenAI). Offline-only use requires swapping in self-hosted models and adjusting configs.
- Training requirements: Fine-tuning the orchestrator policy benefits from a CUDA-compatible GPU, though inference works on CPU via API calls.
- Tool cost awareness: The framework penalizes web searches, but users must still monitor real-world API usage to avoid unexpected charges.
These factors make Puppeteer best suited for teams with access to cloud LLM APIs or strong local inference infrastructure.
Summary
Puppeteer redefines multi-agent LLM collaboration by replacing static workflows with an adaptive, reinforcement-learned orchestrator. It directly tackles coordination overhead, computational waste, and inflexibility—common pitfalls in traditional agent systems—while enabling efficient, tool-aware, and cost-conscious reasoning.
For technical decision-makers building complex automation pipelines, research assistants, or dynamic AI workflows, Puppeteer offers a scalable, customizable, and performance-optimized foundation. With straightforward setup and deep extensibility, it empowers teams to deploy evolvable agent systems that grow smarter as tasks evolve.