Video generation has long been bottlenecked by two stubborn realities: astronomical training costs and rigid temporal modeling. Most state-of-the-art image-to-video (I2V) or text-to-video (T2V) systems require millions of training samples and six-figure GPU budgets—putting them out of reach for researchers, startups, and indie developers. Enter PUSA (Pusa-VidGen): a breakthrough video diffusion framework that delivers better performance than leading alternatives at less than 1/200th the cost—just (500 in training expenses and only 4,000 training samples.
At the heart of PUSA lies Vectorized Timestep Adaptation (VTA), a novel technique that replaces the traditional scalar timestep (a single number controlling noise level across all frames) with a vector—one noise value per frame. This enables fine-grained, frame-level temporal control without altering or damaging the base model’s original capabilities. The result? A single, unified model that excels at multiple video generation tasks—all while preserving the powerful priors of its foundation model (e.g., Wan-T2V-14B).
Crucially, PUSA is non-destructive: it uses lightweight LoRA-style adaptations, so the base model’s text-to-video functionality remains fully intact. You get more capabilities—not trade-offs.
Why PUSA Changes the Game for Video Generation
Ultra-Low Cost, High Performance
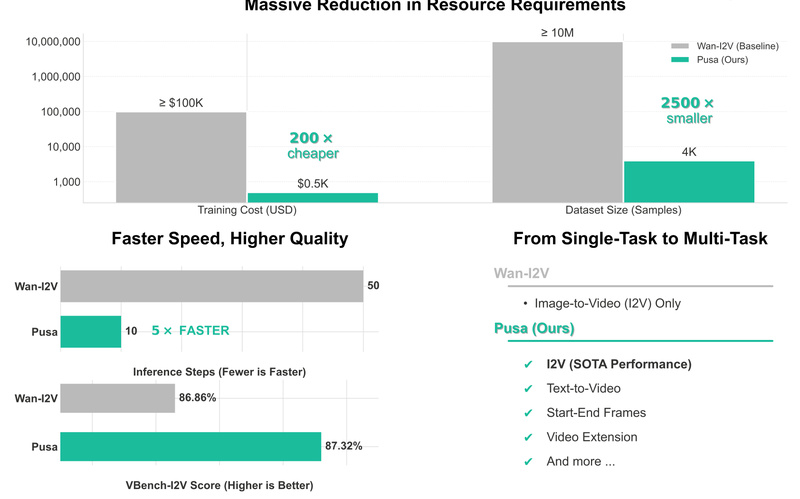
PUSA V1.0 outperforms Wan-I2V-14B—a top-tier I2V model—on the VBench-I2V benchmark with a score of 87.32% vs. 86.86%, despite using:
- ≤ 1/200th the training cost ()500 vs. ≥(100,000)
- ≤ 1/2500th the dataset size (4K samples vs. ≥10M)
This efficiency stems from VTA’s surgical precision: instead of retraining the entire model, PUSA only adapts the timestep mechanism, injecting temporal dynamics where they matter most.
One Model, Many Tasks—Zero Retraining Needed
Unlike conventional approaches that require separate models or fine-tuning per task, PUSA handles diverse video generation scenarios out of the box:
- Text-to-Video (T2V)
- Image-to-Video (I2V)
- Start-End Frame Generation (generate a video given only the first and last frames)
- Video Extension (continue a video beyond its original length)
- Video Completion & Transitions (blend or bridge between clips)
All of these work zero-shot—no additional training required. This universality dramatically reduces operational complexity and storage overhead for teams managing video pipelines.
Lightning-Fast Inference with LightX2V
Speed matters in real-world applications. PUSA integrates LightX2V acceleration, enabling high-quality video generation in just 4 diffusion steps—compared to 10, 20, or even 30 steps in standard models. This doesn’t just cut latency; it slashes compute costs during inference, making interactive or batch applications far more viable.
Recent support for Wan2.2’s MoE DiT architecture (separate high-noise and low-noise diffusion transformers) further boosts visual fidelity without sacrificing speed.
Ideal Use Cases for Teams and Practitioners
PUSA is tailor-made for scenarios where resources are limited but flexibility is essential:
- AI Startups & Indie Developers: Build video features without a )100K training budget or access to massive datasets.
- Research Labs: Experiment with multi-task video generation using a single, open-source model that’s easy to adapt.
- Creative Tools & Editors: Power applications like automatic video extension, scene interpolation, or AI-assisted editing—tasks that previously required custom pipelines.
- Educational Projects: Teach advanced diffusion concepts using a model that demonstrates efficiency, modularity, and temporal control.
Because PUSA preserves base-model capabilities and supports ComfyUI (thanks to community contributions), it integrates smoothly into existing generative workflows.
Getting Started with PUSA
PUSA is fully open-source and designed for practical use. Here’s how to begin:
-
Clone the repository:
git clone https://github.com/Yaofang-Liu/Pusa-VidGen
-
Download pre-trained weights:
Model checkpoints (including Pusa-Wan2.2-V1) are available on Hugging Face. The codebase includes scripts for both Wan2.1 and Wan2.2 architectures. -
Run inference via CLI or ComfyUI:
For example, image-to-video generation with LightX2V acceleration:python pusa_v1_script.py --prompt "A surfer riding a wave at sunset" --image input.jpg --lightx2v --steps 4
Similar scripts exist for video extension, start-end frame generation, and transitions—all configurable via simple parameters like
noise_multiplierandcond_position.
The project provides ready-to-use shell scripts, detailed READMEs, and training code, making it accessible even to those new to video diffusion.
Current Limitations and Realistic Expectations
While PUSA is a major leap forward, it’s important to understand its boundaries:
- Quality is capped by the base model: PUSA V1.0 builds on Wan-T2V-14B, so its output fidelity reflects that foundation. Future versions on stronger bases (e.g., Hunyuan Video) could unlock even higher quality.
- Sim2real gaps may appear: In I2V tasks, slight color or style shifts between the input image and generated frames can occur—a known challenge in diffusion-based conditioning.
- Video length is limited: PUSA currently targets short clips (e.g., 2–4 seconds at 16–30 fps). Long-form video generation isn’t supported yet.
These are active areas for community improvement, and the project maintainers welcome contributions.
Summary
PUSA redefines what’s possible in efficient, flexible video generation. By introducing Vectorized Timestep Adaptation, it achieves state-of-the-art I2V performance at a fraction of the cost, while unlocking zero-shot multi-task capabilities in a single model. With 4-step inference via LightX2V, open weights, and full compatibility with modern frameworks like ComfyUI, PUSA is not just a research novelty—it’s a practical tool for builders, creators, and researchers ready to democratize high-quality video AI.
If you need a video generation solution that’s affordable, versatile, and fast, PUSA is worth your immediate attention.