Vision-language models (VLMs) are increasingly essential for tasks that require joint understanding of images, videos, and text—ranging from document parsing to visual assistants. However, many existing models struggle with input flexibility: they often force images into fixed resolutions, leading to information loss, distortion, or inefficient token usage.
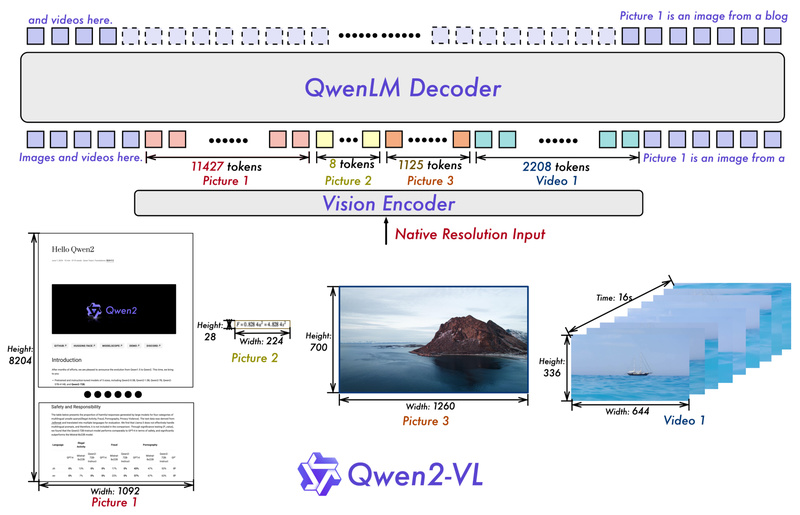
Qwen2-VL directly addresses this limitation. Developed by Alibaba’s Qwen team, it introduces a breakthrough approach called Naive Dynamic Resolution, enabling the model to natively handle visual inputs of any size without cropping, padding, or arbitrary resizing. This capability allows Qwen2-VL to preserve fine-grained details in high-resolution imagery while remaining efficient on smaller inputs—mimicking how humans naturally perceive visual scenes at varying scales.
Available in 2B, 8B, and 72B parameter sizes, Qwen2-VL achieves performance comparable to leading commercial models like GPT-4o and Claude 3.5 Sonnet across multimodal benchmarks, while remaining fully open-source. Its unified architecture for both images and videos, combined with robust OCR and spatial reasoning, makes it a compelling choice for real-world applications.
Why Fixed-Resolution Models Fall Short
Traditional vision-language models tokenize images using a rigid grid—e.g., 224×224 or 336×336 pixels—regardless of the original aspect ratio or content density. This leads to three key issues:
- Loss of detail: High-resolution images (e.g., medical scans, satellite photos, or dense documents) are downsampled, blurring critical features.
- Wasted computation: Small images are padded or upscaled, inflating token counts unnecessarily.
- Poor layout preservation: Cropping or squashing distorts spatial relationships, harming tasks like form understanding or object grounding.
These limitations make fixed-resolution models unreliable in production environments where input variability is the norm, not the exception.
How Qwen2-VL Solves This with Naive Dynamic Resolution
Qwen2-VL replaces fixed grids with Naive Dynamic Resolution, a simple yet powerful mechanism:
- The model dynamically adjusts the number of visual tokens based on the actual pixel count of the input image.
- For example, a 1024×1024 image may generate ~1,024 visual tokens, while a 256×256 thumbnail might use only ~64 tokens.
- This preserves aspect ratio and avoids artificial distortion, ensuring that visual semantics remain intact.
Crucially, this approach aligns with human perception: we don’t “resize” the world to fit a fixed mental canvas—we adapt our attention based on scale and relevance. Qwen2-VL replicates this adaptability computationally.
Unified Vision Encoding for Images and Videos
Unlike many VLMs that treat images and videos as separate modalities, Qwen2-VL uses a single, unified processing pipeline. Both images and videos are encoded using the same vision transformer backbone and tokenization strategy.
This simplifies system design and enables consistent representation learning. For videos, Qwen2-VL samples frames dynamically (configurable via FPS or total frame count) and applies the same dynamic resolution logic per frame, ensuring temporal coherence without excessive token bloat.
Precise Multimodal Alignment with M-RoPE
To fuse visual and textual information accurately—especially in complex scenes with multiple objects, text boxes, or video actions—Qwen2-VL employs Multimodal Rotary Position Embedding (M-RoPE).
M-RoPE extends standard RoPE by encoding 2D spatial coordinates (for images) and 3D spatiotemporal coordinates (for videos) into attention mechanisms. This allows the model to:
- Understand that a caption refers to a specific region in an image.
- Track moving objects across video frames.
- Ground answers like “the red car on the left” with high spatial fidelity.
This capability is foundational for tasks requiring precise localization, such as GUI automation, accessibility tools, or visual question answering.
Real-World Applications Where Qwen2-VL Excels
Document Intelligence
Qwen2-VL’s strong OCR—supporting 32 languages, including degraded text in low-light or tilted photos—makes it ideal for extracting structured data from invoices, receipts, forms, and handwritten notes. Its layout-aware processing retains positional relationships, enabling accurate parsing of tables and multi-column documents.
Visual Assistants and Agents
Thanks to its spatial reasoning and object grounding, Qwen2-VL can power early-stage visual agents that:
- Identify UI elements on mobile or desktop screens.
- Generate HTML/CSS from wireframe images.
- Navigate apps by understanding visual affordances.
Content Moderation & Accessibility
The model can describe images for visually impaired users, detect inappropriate content, or verify product authenticity—leveraging its broad pretraining on diverse visual domains (celebrities, landmarks, flora, anime, etc.).
Long Video Understanding
With native support for long-context processing (up to 256K tokens, expandable to 1M with YaRN), Qwen2-VL can analyze hours-long videos while maintaining temporal awareness—useful for surveillance, lecture transcription, or sports analytics.
Getting Started: Simple Inference in Minutes
Qwen2-VL is available on Hugging Face and ModelScope. Here’s how to run inference with just a few lines of code:
from transformers import AutoModelForImageTextToText, AutoProcessor
model = AutoModelForImageTextToText.from_pretrained("Qwen/Qwen2-VL-72B-Instruct", device_map="auto", trust_remote_code=True
)
processor = AutoProcessor.from_pretrained("Qwen/Qwen2-VL-72B-Instruct")
messages = [{"role": "user","content": [{"type": "image", "image": "https://example.com/photo.jpg"},{"type": "text", "text": "Describe this image."}]
}]
inputs = processor.apply_chat_template(messages, return_tensors="pt", add_generation_prompt=True)
inputs = inputs.to(model.device)
generated_ids = model.generate(**inputs, max_new_tokens=256)
output = processor.batch_decode(generated_ids[:, inputs.shape[1]:], skip_special_tokens=True)
print(output[0])
The same interface works for local files, base64-encoded images, video URLs, or multiple images. For fine-grained control over resolution and token budget, use the qwen-vl-utils toolkit to set min_pixels and max_pixels per input.
Batch processing, FlashAttention-2 acceleration, and FP8 quantization are also supported for high-throughput scenarios.
Practical Considerations and Limitations
- Hardware requirements: The 72B model typically requires multiple high-end GPUs (e.g., 2×80GB A100/H100) for full-precision inference. Smaller variants (2B, 8B) run efficiently on consumer hardware.
- Token budget tuning: For ultra-high-resolution inputs or long videos, explicitly setting pixel limits (
min_pixels,max_pixels,total_pixels) prevents excessive memory usage. - Language support: While OCR covers 32 languages, reasoning and instruction-following quality may vary across non-English prompts.
- Licensing: Qwen2-VL is open for both research and commercial use under the Tongyi Qianwen license—review terms before deployment.
Summary
Qwen2-VL redefines how vision-language models handle real-world visual inputs by eliminating the constraint of fixed resolutions. Its Naive Dynamic Resolution, unified image/video processing, and M-RoPE-based alignment deliver human-like flexibility and precision—making it uniquely suited for applications demanding robustness across diverse, uncurated visual data. With open weights, strong benchmarks, and developer-friendly tooling, Qwen2-VL empowers practitioners to build next-generation multimodal systems without compromising on quality or scalability.