Imagine a single AI model that natively understands and generates responses across text, images, audio, and video—all in real time, in multiple languages, and without sacrificing performance in any modality. That’s Qwen3-Omni, a breakthrough omni-modal foundation model from Alibaba’s Qwen team. Unlike most “multimodal” systems that rely on separate models stitched together, Qwen3-Omni unifies perception and generation into one architecture, delivering state-of-the-art results across all four modalities while matching the performance of specialized single-modality models in the same size class.
Released under the Apache 2.0 license, Qwen3-Omni isn’t just a research curiosity—it’s a production-ready tool designed for real-world applications, from real-time voice assistants to open-source audio captioning, a capability previously missing from the ecosystem. With support for 119 text languages, 19 speech input languages, and 10 speech output languages, it’s built for global deployment.
Why Qwen3-Omni Stands Out: No Trade-Offs Across Modalities
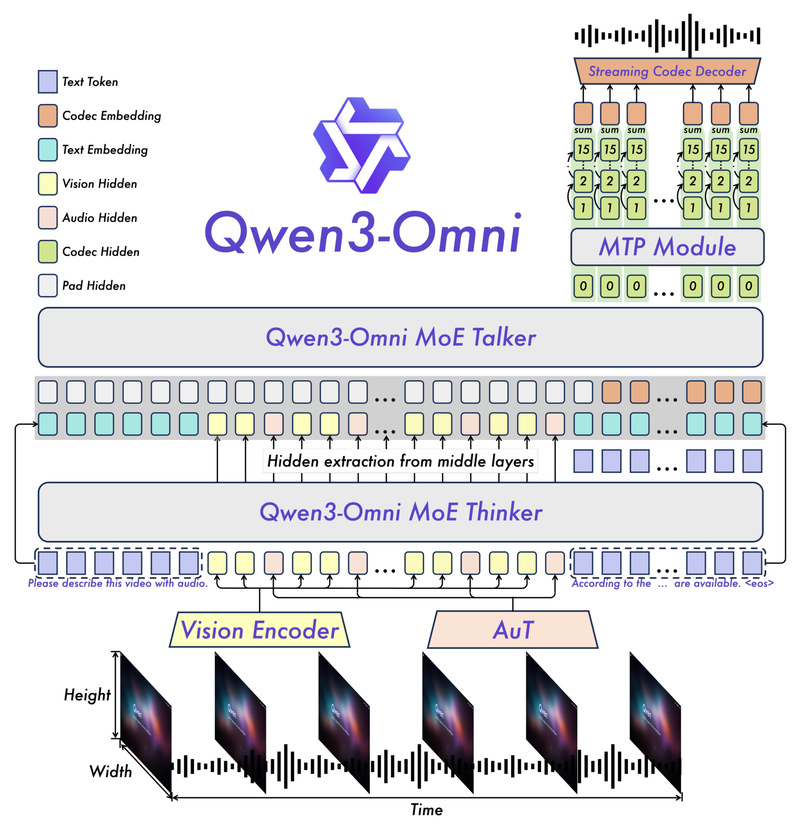
Most multimodal models suffer from “jack-of-all-trades, master of none” syndrome: adding support for audio or video often degrades text or vision performance. Qwen3-Omni breaks this pattern. Through a novel Thinker-Talker Mixture-of-Experts (MoE) architecture, it maintains top-tier performance in every domain:
- Text: Matches Qwen3’s strong language understanding and reasoning.
- Vision: Excels at OCR, object grounding, and image-based math.
- Audio: Sets new open-source records in speech recognition, translation, and audio comprehension.
- Video: Understands temporal dynamics, scene transitions, and first-person navigation.
The results speak for themselves: across 36 audio and audio-visual benchmarks, Qwen3-Omni achieves open-source SOTA on 32 and overall SOTA on 22, outperforming closed-source giants like Gemini-2.5-Pro, GPT-4o-Transcribe, and Seed-ASR.
For example:
- On LibriSpeech, it achieves a 1.22% word error rate (WER) on clean English speech—best among open models.
- On CV15-zh, it hits 4.28% WER, surpassing commercial systems.
- In multilingual speech-to-text translation, it leads across language pairs like French-to-English and Chinese-to-Japanese.
- For audio captioning, the fine-tuned Qwen3-Omni-30B-A3B-Captioner delivers detailed, low-hallucination descriptions of arbitrary sounds—filling a critical gap in open-source AI.
Real Problems Solved for Practitioners
Before Qwen3-Omni, building a multimodal application meant integrating separate models for ASR, TTS, vision, and language—each with its own API, latency profile, and failure modes. This led to:
- High system complexity
- Inconsistent user experiences
- Latency bottlenecks (especially in voice interaction)
- Costly infrastructure
Qwen3-Omni eliminates these pain points by handling everything end-to-end:
- Single inference pipeline for mixed inputs (e.g., a video with spoken questions + visual context).
- Real-time streaming speech synthesis with just 234 ms theoretical first-packet latency in cold-start scenarios, enabled by a lightweight causal ConvNet and multi-codebook discrete audio prediction—replacing slow diffusion models.
- Natural turn-taking in voice conversations, with fluent text and human-like speech output.
- Open-source audio captioning, finally giving researchers and developers a reliable tool to describe environmental sounds, music, or mixed audio.
This makes Qwen3-Omni ideal for teams building:
- Voice-enabled customer support agents
- Accessibility tools (e.g., real-time audio descriptions for the visually impaired)
- Multilingual meeting assistants that transcribe, translate, and summarize
- Smart home or automotive interfaces with multimodal input (voice + camera feed)
- Content moderation systems analyzing user-uploaded video+audio
Getting Started: Flexible Deployment for Every Team
Qwen3-Omni is designed for both experimentation and production. You have three main paths:
1. Open-Source Libraries (Full Control)
Use Hugging Face Transformers or vLLM for local inference:
- Transformers: Best for prototyping, with support for interleaved text, image, audio, and video inputs via the
qwen-omni-utilstoolkit. - vLLM: Recommended for low-latency, high-throughput deployment. It supports batched multimodal inference and scales across GPUs with tensor parallelism.
Tip: Disable the “Talker” component if you only need text output—this saves ~10 GB GPU memory.
2. Docker (Fast Local Setup)
A pre-built Docker image (qwenllm/qwen3-omni) includes all dependencies (FFmpeg, CUDA, vLLM, etc.), letting you launch a local Web UI demo in minutes:
docker run --gpus all -p 8901:80 qwenllm/qwen3-omni:3-cu124
3. DashScope API (Rapid Prototyping)
For teams without GPU infrastructure, Alibaba’s DashScope API offers both offline and real-time endpoints for Qwen3-Omni, including the Captioner variant—ideal for quick integration and testing.
Key Considerations and Limitations
While powerful, Qwen3-Omni has practical constraints:
- Hardware demands: The full Qwen3-Omni-30B-A3B-Instruct model requires 79–145 GB GPU memory (depending on video length) in BF16 precision. The Thinking-only variant reduces this by ~10 GB.
- Speech output: Limited to 10 languages (English, Chinese, French, German, Russian, Italian, Spanish, Portuguese, Japanese, Korean).
- Audio streaming: Real-time synthesis works best with the provided toolkit and assumes consistent
use_audio_in_videosettings across preprocessing and inference.
These aren’t flaws—they’re trade-offs for unprecedented capability. For many use cases, the Qwen3-Omni-Flash variants (lighter, faster) may offer a better balance.
Why This Matters Now
In an era where AI products demand seamless multimodal interaction, Qwen3-Omni offers a strategic advantage: one open, Apache 2.0-licensed model that replaces an entire stack of proprietary or fragmented tools. It’s not just “multimodal”—it’s cohesively intelligent across senses, languages, and tasks.
For product teams, this means faster iteration, lower integration costs, and richer user experiences. For researchers, it unlocks new directions in audio-visual reasoning and open audio understanding. And for the open-source community, it sets a new standard for what a truly unified AI model can achieve.
Summary
Qwen3-Omni redefines what’s possible in multimodal AI. By delivering SOTA performance across text, image, audio, and video in a single, open model, it solves real engineering challenges—complexity, latency, and capability gaps—while enabling new applications in voice interaction, accessibility, and global content understanding. Whether you deploy it via API, Docker, or bare-metal vLLM, Qwen3-Omni gives you a future-proof foundation to build the next generation of intelligent systems.