Retrieval-Augmented Generation (RAG) has revolutionized how we use large language models by grounding their responses in external knowledge. But here’s the problem: most RAG systems only understand text. In the real world—whether you’re reviewing a scientific paper, a financial report, or a technical manual—information lives across multiple modalities: figures, charts, tables, mathematical equations, and structured layouts. Traditional RAG pipelines break down when faced with this reality, often ignoring or misrepresenting non-textual content.
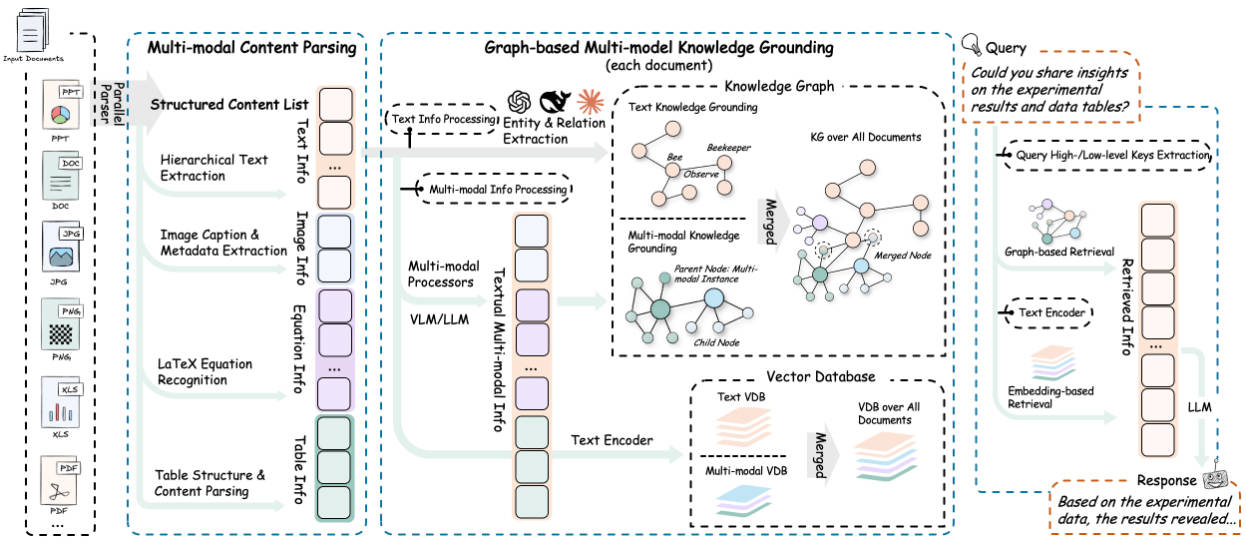
Enter RAG-Anything, an open-source, unified RAG framework designed from the ground up to process any document, in any format, with any modality. Built on top of LightRAG but extended far beyond it, RAG-Anything treats multimodal documents not as a collection of disjointed elements, but as interconnected knowledge entities. This enables seamless querying across text, images, tables, and LaTeX formulas—through a single interface, with no need to stitch together separate tools or pipelines.
If your work involves complex, mixed-content documents, RAG-Anything isn’t just an incremental improvement—it’s a paradigm shift.
Why Text-Only RAG Falls Short in Real-World Scenarios
Most existing RAG systems assume documents are plain text. Even when they ingest PDFs or Word files, they extract only textual streams, discarding spatial layout, visual semantics, tabular structure, and mathematical meaning. The result?
- A chart showing performance trends becomes an unreadable block of axis labels.
- A table comparing model accuracy turns into a jumbled sequence of numbers and headers.
- A key equation like P(d|q) = P(q|d)P(d)/P(q) is either lost or rendered as garbled symbols.
This isn’t a minor inconvenience—it’s a critical failure in domains where evidence spans modalities. In academic research, engineering documentation, or business intelligence, the most important insights often emerge from the relationship between a figure, its caption, and the surrounding analysis. Text-only RAG simply can’t capture that.
How RAG-Anything Unifies Multimodal Knowledge
RAG-Anything reimagines document processing by integrating five core stages into one cohesive pipeline:
- Document Parsing – Using either MinerU or Docling, it extracts text, images, tables, and equations while preserving page-level context and document hierarchy.
- Multimodal Content Understanding – Specialized processors handle each modality:
- Visual Content Analyzer: Generates descriptive captions and captures spatial relationships.
- Structured Data Interpreter: Parses tables and infers statistical patterns.
- Mathematical Expression Parser: Accurately reads LaTeX and maps equations to domain concepts.
- Multimodal Knowledge Graph Construction – Entities from all modalities are linked via cross-modal relationships (e.g., “Figure 3 illustrates the method described in Section 2.1″) and scored for relevance.
- Hybrid Retrieval – Combines vector-based semantic search with graph traversal to retrieve not just relevant text, but the full context—including associated images, tables, or formulas.
- Modality-Aware Querying – Supports three interaction modes:
- Pure text queries (e.g., “What were the main results?”)
- VLM-enhanced queries (automatically sends retrieved images to a vision-language model like GPT-4o for analysis)
- Explicit multimodal queries (e.g., “Compare this user-provided table with the one in the document”)
This architecture ensures that when you ask, “What does Figure 2 show?”, the system doesn’t just return a caption—it retrieves the actual image, analyzes it with a VLM, and grounds its answer in both visual and textual context.
Standout Features for Real-World Usability
RAG-Anything isn’t just theoretically powerful—it’s engineered for practical adoption:
- Universal Format Support: Handles PDFs, DOCX, PPTX, XLSX, JPG, PNG, and more out of the box.
- Flexible Ingestion: You can either parse raw documents automatically or insert pre-extracted content lists (ideal for integrating with existing data pipelines).
- No Toolchain Fragmentation: Eliminates the need for separate OCR engines, table extractors, or equation parsers—everything runs in one framework.
- Extensible Modality Handlers: Add support for new content types (e.g., audio snippets, chemical structures) via a plugin interface.
- Batch Processing: Ingest entire folders of documents with a single command.
Ideal Use Cases
RAG-Anything excels wherever documents are rich and heterogeneous:
- Academic researchers analyzing papers with interleaved theory, experiments, figures, and tables.
- Enterprise knowledge managers building Q&A systems over technical manuals or financial reports.
- AI developers creating domain-specific assistants that must understand diagrams or data visualizations.
- Long-document analysts working with 100+ page regulatory filings where evidence is scattered across modalities.
In benchmarks on multimodal documents, RAG-Anything significantly outperforms text-only RAG systems—especially as document length and complexity increase.
Getting Started Is Straightforward
Installation is simple:
pip install raganything[all] # Includes support for images, text, and more
For Office documents, you’ll need LibreOffice installed (a one-time system requirement).
Then, with just a few lines of Python, you can:
- Parse a PDF and build a multimodal knowledge base
- Query it with text, images, or structured data
- Receive answers that synthesize information across modalities
The framework supports any OpenAI-compatible LLM and VLM, making it easy to integrate with your preferred model provider.
Practical Considerations
While powerful, RAG-Anything does have requirements to keep in mind:
- LibreOffice is needed for reliable Office document parsing.
- Vision-language models (e.g., GPT-4o, LLaVA) are required for full VLM-enhanced querying.
- Performance gains are most pronounced on multimodal documents—if your data is purely textual, standard RAG may suffice.
However, for mixed-content use cases, these are reasonable trade-offs for a system that finally handles real-world documents as they actually exist.
Summary
RAG-Anything solves a fundamental mismatch in the RAG ecosystem: the gap between the multimodal nature of real-world documents and the text-only limitations of current systems. By unifying parsing, representation, retrieval, and generation across text, images, tables, and equations, it delivers accurate, contextually grounded answers where other systems fail.
Best of all, it’s open-source, modular, and designed for real-world integration—no PhD in multimodal AI required. If you work with complex documents and need trustworthy answers, RAG-Anything is the first RAG framework that truly understands the full spectrum of your data.