Building effective Retrieval-Augmented Generation (RAG) systems is notoriously difficult. Practitioners must juggle data preparation, retrieval integration, prompt engineering, model fine-tuning, and nuanced evaluation—all while ensuring the final system reliably uses external knowledge. Enter RAG Foundry, now rebranded as RAG-FiT (RAG Fine-tuning), an open-source framework from Intel Labs that streamlines this entire workflow. Designed for engineers, researchers, and technical decision-makers, RAG-FiT provides a modular, end-to-end pipeline to create, train, and evaluate LLMs enhanced with domain-specific knowledge—without drowning in implementation details.
RAG-FiT isn’t just another RAG toolkit. It’s a unified framework that treats the entire RAG lifecycle as a reproducible, configurable workflow. From synthesizing training data that captures retrieval context to evaluating outputs using RAG-aware metrics, RAG-FiT reduces the gap between prototyping and production-ready experimentation.
Why RAG-FiT Stands Out
Four Integrated Modules for Full RAG Lifecycle Control
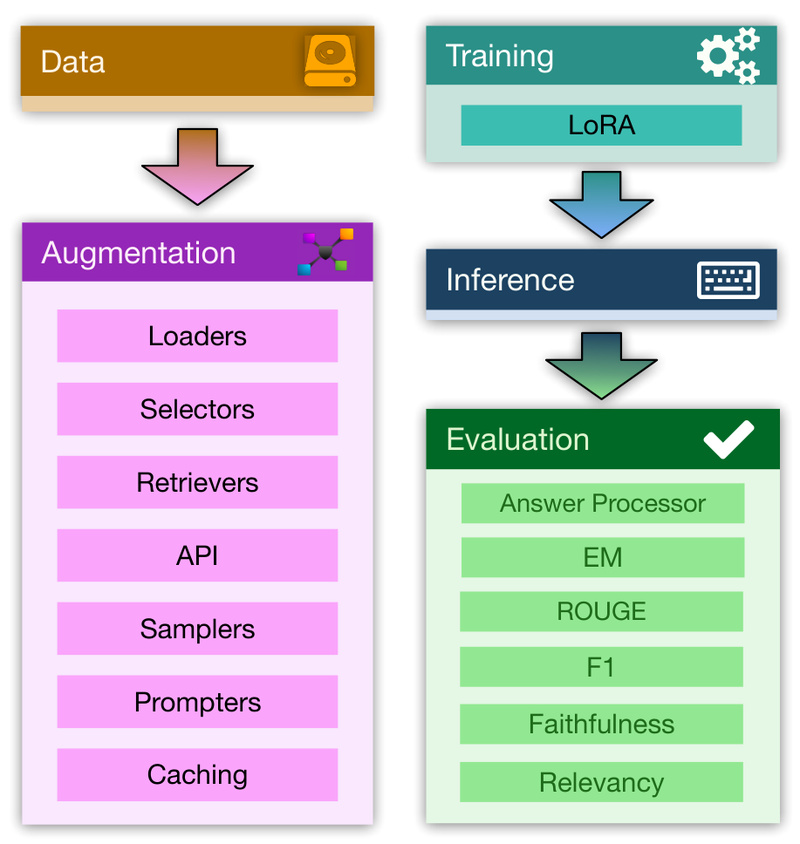
RAG-FiT breaks down the RAG development process into four composable modules:
- Dataset Creation: Automatically generates RAG-augmented datasets by simulating full RAG interactions—including query formulation, document retrieval, prompt templating, and completion generation. The output is a structured, model-agnostic dataset that preserves metadata like retrieved passages, citations, and reasoning traces.
- Training: Supports parameter-efficient fine-tuning (PEFT) via libraries like TRL, enabling efficient adaptation of models such as Llama-3 and Phi-3 on your custom RAG datasets. Trained models can be pushed directly to the Hugging Face Hub.
- Inference: Generates predictions using either fine-tuned models or off-the-shelf LLMs, applying the same RAG context used during training for consistent evaluation.
- Evaluation: Goes beyond basic accuracy by supporting RAG-specific metrics—including EM, F1, ROUGE, BERTScore, RAGAS, and DeepEval. Crucially, metrics can leverage the full dataset structure, evaluating not just final answers but also retrieval relevance, citation quality, and reasoning fidelity.
Configuration-Driven Experimentation with Hydra
RAG-FiT uses Hydra, a powerful configuration management system, to enable reproducible and scalable experimentation. Users define workflows via YAML files and can override parameters directly from the command line—ideal for A/B testing different retrieval strategies, prompt templates, or fine-tuning settings. Pre-configured setups from the original research paper (e.g., on ASQA) are included, allowing users to reproduce published results out of the box.
Solving Real-World RAG Challenges
Traditional RAG implementations often suffer from three core pain points—RAG-FiT addresses each systematically:
- Lack of high-quality RAG training data: Most fine-tuning datasets ignore retrieval context. RAG-FiT explicitly captures the full interaction—query, retrieved documents, and model response—enabling the model to learn how to use retrieved information, not just what to say.
- Oversimplified evaluation: Standard LLM metrics don’t assess whether an answer is grounded in retrieved evidence. RAG-FiT’s evaluation module supports local (per-sample) and global (dataset-wide) metrics that consider retrieval quality, attribution accuracy, and semantic faithfulness.
- Pipeline fragmentation: Retrieval, prompting, and generation are often stitched together with brittle scripts. RAG-FiT unifies them into a single, versionable workflow driven by configuration—not ad hoc code.
Ideal Use Cases
RAG-FiT excels in scenarios where generic LLM responses fall short and domain expertise matters:
- Enterprise knowledge bases: Fine-tune a compact model like Phi-3 on internal documentation to power accurate, up-to-date chatbots or support agents.
- Domain-specific QA systems: Build medical, legal, or technical Q&A engines using proprietary or curated datasets (e.g., PubMed, case law, or engineering manuals).
- Rapid RAG prototyping: Test multiple retrieval-augmentation strategies—such as re-ranking, query expansion, or few-shot prompting—within hours, not weeks.
The framework’s support for PEFT makes it especially cost-effective for organizations with limited GPU resources, as it avoids full-model retraining.
Getting Started
Getting up and running with RAG-FiT is straightforward:
- Clone the repository:
git clone https://github.com/IntelLabs/RAGFoundry cd RAGFoundry pip install -e .
- Install optional integrations (e.g., for Haystack or DeepEval):
pip install -e .[haystack]
- Run any module using its corresponding script and configuration:
python processing.py -cp configs/paper -cn processing-asqa-retrieval
The PubmedQA Tutorial provides a complete end-to-end example, while the configs/paper directory offers ready-to-use setups that replicate the framework’s published results.
Limitations and Considerations
While RAG-FiT significantly lowers the barrier to effective RAG development, it’s not a plug-and-play SaaS solution. Users should:
- Have access to relevant, high-quality knowledge sources (e.g., internal databases or domain corpora).
- Possess basic familiarity with LLM fine-tuning concepts and retrieval systems.
- Be prepared to invest engineering effort if deploying to production—RAG-FiT is research-oriented and released under the Apache 2.0 license, not as an official Intel product.
That said, its modularity and configurability make it an excellent foundation for building custom, scalable RAG pipelines.
Summary
RAG-FiT (formerly RAG Foundry) solves the core complexity of building reliable, knowledge-grounded LLM applications by unifying data creation, training, inference, and evaluation into a single, open-source framework. For technical teams looking to move beyond naive RAG implementations and toward measurable, domain-specific performance gains, it offers a structured, reproducible, and efficient path forward. Whether you’re fine-tuning a small model on internal docs or researching next-generation RAG architectures, RAG-FiT provides the tools to do it right—without reinventing the wheel.