Building autonomous agents that can reason, act, and adapt over multiple interaction steps remains one of the toughest challenges in applied large language model (LLM) research. Traditional fine-tuning or single-turn reinforcement learning (RL) methods often fail when agents must navigate unpredictable, feedback-rich environments—like web browsers, puzzle games, or simulated tool interfaces—where decisions compound over time and outcomes are non-deterministic.
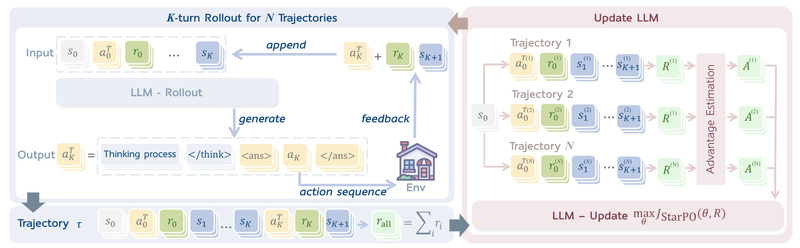
Enter RAGEN (Reasoning AGENt): a modular, research-ready framework designed specifically for training LLM agents via multi-turn reinforcement learning. Unlike approaches that treat reasoning as a static output, RAGEN treats it as an interactive process, jointly optimizing both the agent’s internal reasoning steps and its external actions across full trajectories. Built around the novel StarPO (State-Thinking-Actions-Reward Policy Optimization) algorithm, RAGEN provides the infrastructure to explore how LLMs can truly self-evolve as agents through structured RL in stochastic settings.
Why Multi-Turn Agent Training Is Hard (And Why RAGEN Solves It)
Most RL applications for LLMs focus on single-turn tasks: answer a math question, generate code, or summarize a paragraph. These have fixed inputs and deterministic rewards. But real-world agent tasks—like navigating an e-commerce site to buy a product or solving a Sokoban puzzle—require sequential decision-making, where each action changes the environment state, and identical actions may yield different results due to randomness.
This introduces three core problems:
- Long-horizon credit assignment: Which reasoning step led to eventual success or failure?
- Stochastic feedback: The environment may respond inconsistently, making learning unstable.
- Shallow strategies: Without fine-grained, reasoning-aware rewards, agents often develop shortcuts or hallucinate “thoughts” that look plausible but lack real reasoning.
RAGEN tackles these by optimizing entire trajectories—not individual tokens or steps. Its StarPO framework interleaves rollout (generating multi-turn reasoning-action sequences like <think>...<ans>action</ans>) and update (using trajectory-level rewards to adjust policy). Critically, RAGEN includes StarPO-S, a stabilized variant that filters low-quality rollouts, incorporates critics, and smooths gradient updates to avoid the “Echo Trap”—a training instability pattern where reward variance collapses and gradients spike.
Key Features That Make RAGEN Stand Out
Trajectory-Level Reinforcement Learning with StarPO
RAGEN doesn’t just apply PPO to LLMs. It rethinks RL for agents: rewards are assigned per full interaction trace, and optimization uses importance sampling over complete trajectories. This preserves long-range dependencies in reasoning chains and aligns updates with actual task outcomes—not intermediate guesses.
Modular, Extensible Architecture
RAGEN is built as three cleanly separated components:
- Environment State Manager: Handles environment resets, steps, and batched state tracking across seeds.
- Context Manager: Formats observations into prompts, parses LLM outputs into structured actions, and respects context window limits.
- Agent Proxy: Orchestrates rollouts, evaluation, and model updates.
This modularity makes it trivial to plug in new environments—just implement a Gym-compatible step(), reset(), and render(), register it in a YAML config, and RAGEN handles the rest.
Practical Training Optimizations
- LoRA support: Fine-tune large models efficiently (e.g., rank=64, α=64) with minimal VRAM.
- Flexible batching: Adjust
micro_batch_size,response_length, andmax_model_lento run on 24GB GPUs like RTX 4090. - Selective trajectory filtering: Retain only top-k% successful rollouts (e.g., top 25%) to stabilize training—no KL penalties needed.
- Optional dependencies: Install only what you need (e.g.,
. [webshop]or. [lean]).
Built for Real Stochastic Environments
RAGEN includes native support for environments like Sokoban, FrozenLake, Bandit, and WebShop—all featuring randomness, partial observability, or sequential constraints. It even demonstrates cross-domain generalization, e.g., training on 6×6 Sokoban and evaluating on 8×8 with 2 boxes.
Ideal Use Cases: When Should You Choose RAGEN?
RAGEN is not for static text generation or one-step reasoning. It shines when your agent must:
- Interact with an external, stateful environment (real or simulated).
- Make multiple sequential decisions based on evolving feedback.
- Generate explicit reasoning traces that influence actions (not just post-hoc explanations).
- Operate in settings where identical actions may yield different outcomes (stochasticity).
Example applications:
- Autonomous web navigators that shop or fill forms.
- Puzzle-solving agents in grid-world or logic games.
- Research platforms to study how reasoning emerges under multi-turn RL.
- Tool-using assistants in simulated APIs or robotics sandboxes.
If your task involves feedback loops, environment interaction, and multi-step planning, RAGEN provides the scaffolding to explore it rigorously.
Getting Started: From Setup to First Training Run
RAGEN is designed for rapid experimentation:
-
Install:
git clone https://github.com/RAGEN-AI/RAGEN cd RAGEN bash scripts/setup_ragen.sh # or follow manual instructions
-
Choose a config:
config/base.yamlfor full fine-tuning.config/base-lora.yamlfor parameter-efficient training.
-
Launch training:
python train.py --config-name base
On lower-memory GPUs, reduce batch size and context length:
python train.py micro_batch_size_per_gpu=1 ppo_mini_batch_size=8 actor_rollout_ref.rollout.max_model_len=2048 actor_rollout_ref.rollout.response_length=128
-
Evaluate:
python -m ragen.llm_agent.agent_proxy --config-name eval
Configure output paths, context windows, and saved fields directly in
eval.yaml.
For distributed training, RAGEN integrates with Ray and dstack, enabling cloud-scale experiments without Kubernetes.
Limitations and Practical Considerations
RAGEN is powerful but not magic. Keep these in mind:
- Reward design is critical: RAGEN requires reasoning-aware rewards. Binary task success/failure often leads to shallow strategies. Consider shaping rewards based on intermediate reasoning quality.
- Training stability needs care: Without trajectory filtering (StarPO-S), training can collapse into the “Echo Trap.” Always start with filtered rollouts.
- Parallel environments may reduce determinism: If
parallel_friendly=true, thread interleaving can affect reproducibility—even with fixed seeds. Use parallelism only for slow environments. - You provide the environment: RAGEN offers the RL engine, but you must define the task, states, actions, and reward logic.
Summary
RAGEN fills a crucial gap: it’s a practical, modular framework for training LLM agents that reason and act across multi-turn, stochastic interactions. By optimizing full trajectories with StarPO and offering researcher-friendly tooling—from LoRA support to easy environment integration—it enables systematic exploration of agent self-evolution through reinforcement learning. If your work involves building agents that must interact, adapt, and reason over time, RAGEN provides the foundation to do it right.