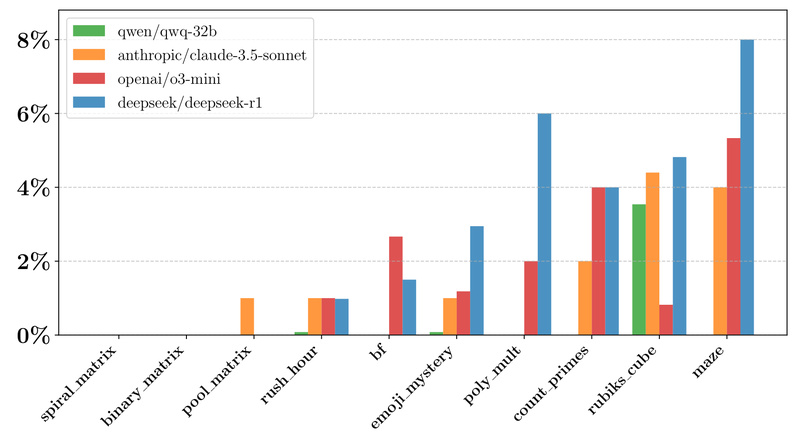
If you’re building or evaluating reasoning-capable AI systems—especially large language models (LLMs)—you’ve likely hit a wall with static benchmarks. Traditional datasets offer fixed questions, making them poor tools for training via reinforcement learning (RL) or for stress-testing a model’s ability to generalize across complexity levels. Enter Reasoning Gym (RG): an open-source Python library that dynamically generates virtually unlimited reasoning tasks with algorithmically verifiable answers, enabling robust RL training and continuous evaluation.
Unlike curated datasets that quickly become saturated during training, Reasoning Gym procedurally constructs tasks across diverse domains—including algebra, logic, geometry, graph theory, arithmetic, cognition, and even classic games like Rubik’s Cube and Countdown. Each generated problem comes with a scoring function that automatically validates answers, turning correctness into a reliable reward signal for RL pipelines. This makes RG uniquely suited for teams aiming to push the boundaries of model reasoning through scalable, curriculum-aware training.
Why Reasoning Gym Solves a Critical Pain Point
Static datasets limit both training and evaluation. Once a model memorizes a fixed set of problems, performance metrics plateau, and it’s unclear whether the model truly reasons or merely recalls patterns. Reasoning Gym addresses this by offering infinite, on-demand data generation with tunable difficulty—ensuring models are always challenged and evaluated under fresh, unseen conditions.
For project leaders and researchers, this means:
- No data exhaustion: Train for longer without overfitting to a fixed set.
- Controlled difficulty scaling: Systematically increase problem complexity to build robust reasoning skills.
- Automated reward signals: Built-in verifiers eliminate the need for manual labeling or heuristic rewards, a major bottleneck in RL for reasoning.
Key Features That Set Reasoning Gym Apart
1. Over 100 Procedural Task Generators Across Domains
Reasoning Gym ships with more than 100 task types spanning mathematical, logical, and game-based reasoning. Examples include:
- Leg counting: “How many legs are there in total if you have 2 crabs, 1 human, and 3 bees?”
- Graph connectivity: Determine if two nodes are connected in a randomly generated graph.
- Arithmetic puzzles: Solve multi-step equations with variable complexity.
- Classic games: Solve Countdown number puzzles or scramble states of a Rubik’s Cube.
Each task is implemented as a data generator that produces not just questions and answers, but also rich metadata enabling programmatic verification.
2. Algorithmic Answer Verification = Reliable RL Rewards
Every dataset in Reasoning Gym includes a score_answer method (or equivalent) that takes a model’s response and the original task entry, then returns a correctness score (typically 1.0 for correct, 0.0 otherwise). This deterministic verification allows RL frameworks to use the score directly as a reward—no human annotation or fuzzy heuristics required.
3. Adjustable Complexity and Composite Datasets
You can fine-tune task parameters (e.g., max_animals=20 in leg counting) to control difficulty. Moreover, RG supports composite datasets, letting you blend multiple task types with custom weighting—ideal for creating balanced curricula or domain-specific benchmarks.
For instance:
from reasoning_gym.composite import DatasetSpec
specs = [DatasetSpec(name='leg_counting', weight=2, config={}),DatasetSpec(name='figlet_font', weight=1, config={"min_word_len": 4}),
]
dataset = reasoning_gym.create_dataset('composite', size=100, datasets=specs)
4. Seamless Integration with Modern ML Workflows
While designed for RL, Reasoning Gym data can be used anywhere structured reasoning tasks are needed:
- Convert to Hugging Face datasets using the provided
save_hf_dataset.pyscript. - Plug into the
verifierslibrary for turnkey RL training with LLMs. - Use generated data for fine-tuning, post-training, or zero-shot evaluation.
Getting Started Without Deep RL Expertise
You don’t need to be an RL expert to benefit from Reasoning Gym. Here’s how to generate and verify tasks in minutes:
Install:
pip install reasoning-gym
Generate and verify:
import reasoning_gym
data = reasoning_gym.create_dataset('leg_counting', size=5, seed=42)
for entry in data:print(f"Q: {entry['question']}")print(f"A: {entry['answer']}")# Verify the official answerassert data.score_answer(answer=entry['answer'], entry=entry) == 1.0
To evaluate a model’s response:
from reasoning_gym import get_score_answer_fn score_fn = get_score_answer_fn(entry["metadata"]["source_dataset"]) model_answer = your_llm(entry["question"]) score = score_fn(model_answer, entry) # Returns 0.0 or 1.0
This simplicity lowers the barrier to entry for teams exploring reasoning-focused training or evaluation.
Practical Limitations and Considerations
Reasoning Gym is powerful but not a magic bullet:
- Python ≥3.10 required: Ensure your environment meets this dependency.
- Actively developed: The PyPI version may lag behind the GitHub
mainbranch, so check release notes if you need the latest features. - Task coverage is broad but not exhaustive: While RG spans many reasoning domains, it doesn’t cover every possible problem type. However, its modular design encourages community contributions—new task generators are welcome.
- RL pipeline knowledge still needed: While data generation is simple, integrating RG into a full RL loop (e.g., with PPO or DPO) requires familiarity with training frameworks. Thankfully, examples in the
verifierslibrary andtraining/directory provide solid starting points.
Real-World Adoption by Leading AI Labs
Reasoning Gym isn’t just academic—it’s already in use by top research groups:
- NVIDIA uses it in ProRL and BroRL to scale reasoning through prolonged RL.
- Meta’s FAIR lab integrates RG into OptimalThinkingBench to study over- and underthinking in LLMs.
- MILA leverages it for Self-Evolving Curriculum and Recursive Self-Aggregation frameworks.
- Nous Research, Gensyn, and Axon RL have built full RL gyms or synthetic datasets on top of RG.
This ecosystem validation confirms RG’s robustness and flexibility in production-grade research.
Summary
Reasoning Gym fills a critical gap in the AI development toolkit: it provides an extensible, verifiable, and infinitely scalable source of reasoning tasks tailored for reinforcement learning and dynamic evaluation. For project and technology decision-makers, it offers a path to move beyond brittle, static benchmarks and toward adaptive, reward-driven training that genuinely improves model reasoning. Whether you’re fine-tuning an LLM, designing an RL curriculum, or building a new reasoning benchmark, Reasoning Gym gives you the infrastructure to do it rigorously—and indefinitely.