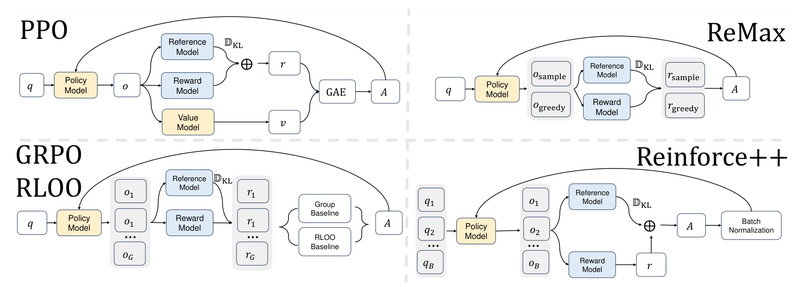
Aligning large language models (LLMs) with human preferences is essential for building safe, helpful, and reliable AI systems. Reinforcement Learning from Human Feedback (RLHF) has become the de facto approach for this alignment, with Proximal Policy Optimization (PPO) as the industry standard. However, PPO’s reliance on a separate critic network introduces significant computational overhead, complicates training pipelines, and increases infrastructure costs—especially at scale.
Enter REINFORCE++, a novel, critic-free RLHF algorithm introduced in the paper “REINFORCE++: An Efficient RLhf Algorithm with Robustness to Both Prompt and Reward Models”. Built into the OpenRLHF framework, REINFORCE++ eliminates the critic entirely while improving training stability, generalization, and robustness to reward model variations. It achieves this through a simple but powerful technique: global advantage normalization.
For teams managing LLM alignment under tight compute budgets or complex reward landscapes, REINFORCE++ offers a compelling alternative—delivering PPO-level performance without the critic bottleneck, and outperforming other critic-free methods like RLOO and GRPO in both speed and reliability.
Why Existing RLHF Methods Fall Short
The Critic Bottleneck in PPO
PPO has dominated RLHF thanks to its stability, but that stability comes at a cost. The algorithm requires training and maintaining a separate critic model to estimate state values and compute advantages. This doubles the number of models in the training loop (actor + critic), increases memory usage, and slows down sampling—particularly when scaling to 70B+ parameter models. In practice, up to 80% of RLHF training time is spent on generation, and the critic adds non-trivial overhead to both forward and backward passes.
Instability in Critic-Free Alternatives
Recent methods like RLOO, ReMax, and GRPO aim to simplify RLHF by removing the critic. While this reduces compute, they estimate advantages independently per prompt, using only responses from the same prompt to compute baselines. This leads to several issues:
- Overfitting on simple prompts: Easy prompts dominate the signal, while complex ones get drowned out.
- Reward hacking: Models exploit biases in reward models by generating responses that score well but lack substance.
- Sensitivity to reward scale: Performance degrades if reward models output values like {0, 1} vs. {-1, 1}, requiring manual prompt filtering or reward normalization.
These limitations make critic-free methods unpredictable in real-world settings where reward models vary and prompt quality is mixed.
How REINFORCE++ Solves These Problems
REINFORCE++ retains the simplicity of critic-free training but introduces global advantage normalization—normalizing advantages across all prompts and responses in a batch, not just within each prompt group. This subtle change has major benefits:
- Unbiased advantage estimation: By leveraging global statistics, REINFORCE++ avoids overfitting to easy prompts.
- Robustness to reward model design: It performs consistently whether rewards are binary, continuous, or include formatting penalties (e.g., -0.5 for bad JSON).
- No prompt truncation needed: Unlike GRPO or RLOO, it doesn’t require filtering out “hard” prompts to stabilize training.
Importantly, REINFORCE++ achieves this without adding any new models or complex machinery. It’s a drop-in replacement for existing REINFORCE variants, making it easy to adopt.
Key Advantages for Practitioners
- Faster Training: Eliminating the critic reduces model count and memory footprint. Combined with vLLM-accelerated generation in OpenRLHF, end-to-end training becomes significantly faster.
- Stable Across Reward Models: Works out-of-the-box with diverse reward signals—ideal for teams experimenting with multiple reward models or external evaluators.
- Better Generalization: Demonstrates superior performance in both standard RLHF and long chain-of-thought (CoT) reasoning tasks, where stable reward propagation over many steps is critical.
- Simpler Pipelines: Fewer models mean fewer failure points, easier debugging, and lower operational overhead.
Ideal Use Cases
REINFORCE++ is particularly well-suited for:
- Resource-constrained teams aligning 7B–70B models without dedicated critic infrastructure.
- Reasoning-focused LLMs that require stable training over long answer trajectories (e.g., math, code, or multi-step planning).
- Rapid RLHF prototyping, where switching reward models shouldn’t require re-tuning the RL algorithm.
- Integration with external environments, such as agent-based RLHF via NeMo Gym, where reward signals come from simulators or human-in-the-loop systems.
If your priority is reproducibility, simplicity, and compatibility with Hugging Face workflows, REINFORCE++ in OpenRLHF is a strong fit.
Getting Started with REINFORCE++ in OpenRLHF
Using REINFORCE++ is straightforward with the OpenRLHF framework:
-
Install OpenRLHF (preferably in a Docker container with vLLM support):
pip install openrlhf[vllm]
-
Prepare your prompt dataset in standard JSON format. OpenRLHF supports Hugging Face chat templates via
--apply_chat_templateor custom formatting with--input_template. -
Launch training with REINFORCE++:
In thetrain_ppo_raycommand, set:--advantage_estimator reinforce_baseline
This activates the REINFORCE++-baseline variant, which uses global normalization and is the recommended configuration.
-
(Optional) Plug in custom rewards:
For programmatic rewards (e.g., code execution, rule checks), implement areward_funcand pass its path via--remote_rm_url.
OpenRLHF’s Hybrid Engine mode (--colocate_all_models) further optimizes GPU utilization by sharing memory across actor, reward, and vLLM engines—ideal for mid-scale deployments.
Limitations and Practical Considerations
While REINFORCE++ simplifies RLHF, it’s not a silver bullet:
- It still requires multiple response samples per prompt (typically 1–4) to compute meaningful advantages.
- In highly dynamic environments with sparse rewards, PPO’s fine-grained advantage estimates may still offer better control.
- For 70B+ models, distributed training via Ray is recommended—REINFORCE++ removes the critic but doesn’t eliminate the need for scale-aware infrastructure.
That said, when combined with OpenRLHF’s optimizations (vLLM, ZeRO-3, AutoTP), REINFORCE++ delivers near-optimal efficiency with minimal complexity.
Summary
REINFORCE++ redefines what’s possible in critic-free RLHF. By replacing per-prompt advantage estimation with global normalization, it achieves remarkable robustness and generalization—without sacrificing speed or simplicity. Integrated into the open-source OpenRLHF framework, it’s ready for production use today, with support from leading AI labs and proven performance in reasoning benchmarks.
If you’re evaluating RLHF algorithms for your next LLM alignment project, REINFORCE++ offers a rare combination: lower infrastructure costs, faster iteration, and resilience to real-world reward noise. In an era where efficiency and reliability are paramount, it’s an option worth serious consideration.