When building real-world computer vision systems—whether for autonomous drones, industrial inspection, or mobile apps—one of the toughest trade-offs is between detection accuracy and inference speed. Many state-of-the-art object detectors rely on deep, computationally expensive backbones like ResNet-101 or Inception, which deliver strong performance but are too slow for real-time use. On the other hand, lightweight models often sacrifice too much accuracy to be practical.
RFBNet (Receptive Field Block Net) offers a compelling middle ground. Introduced in the 2018 ECCV paper “Receptive Field Block Net for Accurate and Fast Object Detection,” it achieves accuracy comparable to very deep detectors while maintaining real-time inference speeds—thanks to a novel, biologically inspired module called the Receptive Field Block (RFB). Built on top of the SSD (Single Shot MultiBox Detector) framework, RFBNet enhances feature representation using lightweight CNN backbones like VGG16 or MobileNet, making it ideal for deployment in resource-constrained environments without compromising detection quality.
Why RFBNet Delivers Both Speed and Accuracy
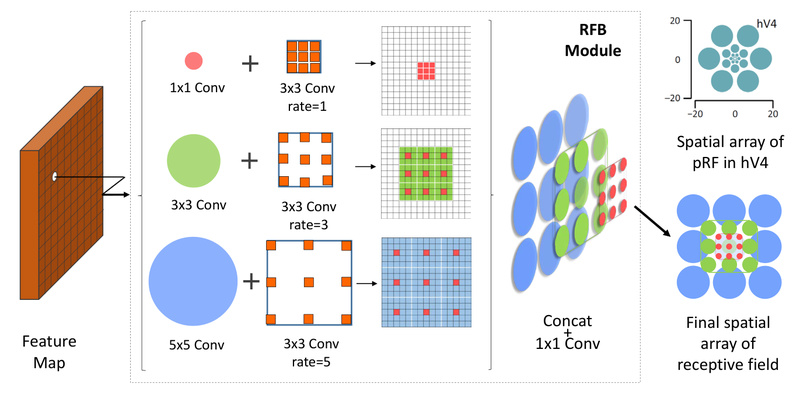
The RFB Module: Mimicking Human Vision for Better Features
The core innovation behind RFBNet is the Receptive Field Block (RFB). Inspired by the structure of receptive fields in the human visual system—where larger receptive fields occur farther from the fovea and respond to coarser visual cues—the RFB module explicitly models the relationship between receptive field size and eccentricity.
In practice, this means RFB combines multiple convolutional branches with varying kernel sizes and dilation rates to simulate multi-scale receptive fields within a single block. This design significantly boosts feature discriminability and robustness, especially for objects at different scales and positions, without adding excessive computational overhead.
Lightweight Backbone, High Performance
Unlike detectors that depend on heavy backbones (e.g., Faster R-CNN with ResNet-101), RFBNet integrates the RFB module into relatively lightweight architectures. The original implementation uses a reduced VGG16 backbone, and a MobileNet variant is also provided. Despite this, RFBNet outperforms deeper models:
- On PASCAL VOC2007, RFBNet512 achieves 82.2 mAP at 38 FPS (Titan X Maxwell)—surpassing R-FCN (80.5 mAP) and SSD512 (79.8 mAP) while running more than 4× faster than R-FCN.
- On COCO, RFBNet512-E reaches 34.4 mAP in just 33ms per image, matching RetinaNet’s accuracy but with dramatically lower latency.
This performance profile makes RFBNet especially valuable for applications where both precision and speed are non-negotiable.
Ideal Use Cases
RFBNet is well-suited for scenarios demanding real-time object detection with reliable accuracy:
- Video surveillance and analytics: Process high-frame-rate video streams with minimal latency.
- Autonomous robots and drones: Enable fast perception on edge hardware with limited compute.
- Mobile and embedded vision apps: Deploy accurate detectors on devices with constrained memory and power.
- Industrial automation: Perform real-time defect detection or object tracking on production lines.
Its compatibility with MobileNet further extends its reach to ultra-low-power devices, though with a modest accuracy trade-off (e.g., 20.7 mAP on COCO minival vs. 19.3 for standard SSD MobileNet).
Getting Started with RFBNet
RFBNet’s codebase is built on PyTorch (specifically v0.4.0) and is derived from the popular ssd.pytorch repository. While the dependency on an older PyTorch version may pose challenges for modern environments, the setup remains straightforward for reproducibility:
Environment Setup
- Python 3+
- PyTorch 0.4.0
- OpenCV (
conda install opencv) - Compile NMS and COCO tools via
./make.sh
Dataset Preparation
Support is provided for PASCAL VOC and MS COCO:
- Use included shell scripts (
VOC2007.sh,VOC2012.sh) to download VOC datasets. - For COCO, organize images and annotations in the standard directory structure under
~/data/COCO/.
Training & Evaluation
Pre-trained VGG16 and MobileNet backbones are available for download. To train:
python train_RFB.py -d VOC -v RFB_vgg -s 300
To evaluate a trained model:
python test_RFB.py -d VOC -v RFB_vgg -s 300 --trained_model /path/to/weights
Official pre-trained models are provided for VOC and COCO with input sizes of 300 and 512, allowing immediate benchmarking or fine-tuning.
Limitations and Practical Considerations
While RFBNet delivers impressive speed-accuracy balance, several constraints should be noted:
- Outdated PyTorch dependency: The codebase is tied to PyTorch 0.4.0 (2018), which may complicate integration into modern pipelines.
- Limited framework export support: Although the GitHub page mentions YOLOX with ONNX/TensorRT/ncnn/OpenVINO support in a 2021 update, the core RFBNet implementation does not include these export utilities, requiring manual adaptation for deployment on accelerators.
- Modest gains with MobileNet: The MobileNet variant offers only marginal mAP improvement over SSD MobileNet (+1.4 points) at the cost of slightly more parameters, which may not justify adoption in extremely resource-limited settings.
Nonetheless, for teams needing a proven, real-time detector that avoids the complexity of newer transformer-based or multi-stage architectures, RFBNet remains a practical and efficient choice.
Summary
RFBNet demonstrates that high object detection accuracy doesn’t require massive models. By incorporating a biologically inspired Receptive Field Block into a streamlined SSD pipeline, it delivers near state-of-the-art results at real-time speeds—even on modest hardware. For engineers and researchers prioritizing deployability, latency, and reliability in vision systems, RFBNet offers a balanced, well-documented solution that bridges the gap between academic performance and industrial practicality.