Modern LLM applications increasingly rely on complex, structured prompts—especially in scenarios like Retrieval-Augmented Generation (RAG), instruction-based tasks, and data labeling pipelines. Yet, optimizing these prompts remains a manual, costly, and often inconsistent process. Enter SAMMO, an open-source Python library from Microsoft that treats prompts not as static strings, but as symbolic programs that can be systematically analyzed, transformed, and optimized—at compile time, before deployment.
Unlike traditional prompt engineering that tweaks surface-level wording, SAMMO operates on a structured representation of prompts, enabling richer, more intelligent transformations. This approach dramatically improves performance across diverse tasks—while reducing token usage, latency, and the need for repeated LLM calls during tuning.
What Makes SAMMO Different?
Symbolic Prompt Programs, Not Just Strings
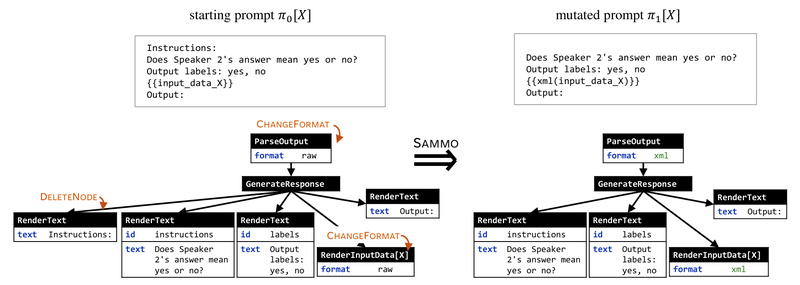
SAMMO’s core innovation lies in its symbolic representation of prompts. Instead of viewing a prompt as a flat text blob, SAMMO parses it into a programmable structure—complete with labeled sections, placeholders, and semantic components. This allows for precise, targeted edits: you can mutate just the instruction block, rewrite only the context section, or compress redundant parts without breaking the overall logic.
This structure-aware design enables compile-time optimization, meaning prompt improvements are baked in before the prompt ever hits an LLM—saving inference costs and ensuring consistent behavior across runs.
Built-In Optimizations That Deliver Real Value
SAMMO ships with a flexible suite of mutation operators—such as paraphrasing, instruction rewriting, and output formatting—that can be combined and searched over. The framework uses search strategies like BeamSearch to automatically find the best-performing variant of your prompt based on a validation metric (e.g., accuracy or F1 score).
Critically, SAMMO supports prompt compression: it can shrink long prompts while preserving—or even improving—task performance. This is especially valuable in RAG systems, where context windows quickly fill up with retrieved documents.
Scalable, Production-Ready Execution
Beyond optimization, SAMMO handles the operational realities of running LLMs at scale:
- Parallel execution of prompts across multiple data points
- Automatic rate-limiting to avoid overwhelming LLM APIs
- Structured output parsing, ensuring reliable extraction of JSON, SQL, or other formats
These features let teams run large-scale evaluations or labeling jobs without building custom orchestration layers.
Where SAMMO Delivers the Most Impact
1. RAG Pipeline Tuning
In RAG systems, prompt structure directly affects retrieval relevance and generation quality. SAMMO enables end-to-end tuning of instruction clarity, context formatting, and output constraints—leading to measurable gains in answer correctness across models like GPT-3.5, Llama 3, or Claude.
2. Instruction Optimization for Task Accuracy
Need your model to follow instructions more reliably? SAMMO can automatically refine vague or ambiguous directions (“Summarize this”) into precise, task-specific ones (“Generate a 2-sentence executive summary highlighting risks and opportunities”). This is particularly useful for domain-specific applications in finance, legal, or healthcare.
3. Prompt Compression Without Quality Loss
Long prompts = high cost + high latency. SAMMO’s compression strategies reduce token count by eliminating redundancy, simplifying language, or reordering components—while maintaining or boosting performance. One study showed up to 30% token reduction with no drop in accuracy.
4. Efficient Data Labeling at Scale
SAMMO supports minibatch prompting: packing multiple inputs into a single LLM call and parsing structured outputs in bulk. This slashes labeling costs and speeds up dataset creation for fine-tuning or evaluation.
Getting Started Is Surprisingly Simple
SAMMO is designed for rapid adoption:
- Install with
pip install sammo - Write prompts in Markdown—using familiar syntax with optional HTML-style comments for section labels (e.g.,
<!-- #instr -->) - Parse into a SAMMO program using
MarkdownParser - Define mutators like
Paraphrase("#instr")orRewrite(...) - Run optimization via
BeamSearchwith your own training data
For example:
PROMPT_IN_MARKDOWN = """
# Instructions <!-- #instr -->
Convert user queries to SQL.
# Table
Users: user_id (INT), name (TEXT)
# Input: {{{input}}}
"""
spp = MarkdownParser(PROMPT_IN_MARKDOWN).get_sammo_program()
mutators = BagOfMutators(Paraphrase("#instr"), Rewrite("#instr", "Be more explicit..."))
optimizer = BeamSearch(runner, mutators, accuracy)
optimizer.fit(d_train)
Tutorials and a live Binder demo are available in the GitHub repository, making experimentation frictionless—even for those new to programmatic prompting.
When Not to Use SAMMO
SAMMO excels at static, compile-time prompt optimization—not dynamic, interactive systems. If you’re building:
- Agent-based workflows (e.g., multi-turn reasoning with tool use), consider AutoGen
- Full-stack LLM applications with routing, memory, and tool integration, look at LangChain or LlamaIndex
SAMMO is purpose-built for teams who treat prompts as programs to be engineered, not just messages to be sent.
Summary
SAMMO redefines prompt engineering by treating prompts as symbolic, structured programs that can be optimized like software. With support for instruction tuning, RAG pipeline refinement, prompt compression, and scalable execution, it solves real pain points: inconsistent outputs, high token costs, and manual tuning cycles. For technical teams seeking reliable, efficient, and automated prompt optimization—without sacrificing control—SAMMO offers a powerful, open-source solution backed by Microsoft research.