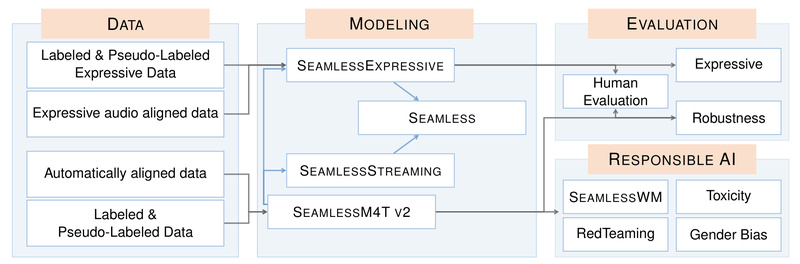
In today’s globalized world, real-time communication across languages remains a major bottleneck. Traditional speech translation systems often fall short—they output robotic, emotionless voices, support only a handful of languages, and introduce significant delays that break the flow of conversation. Enter Seamless, a breakthrough AI system from Meta that redefines what’s possible in cross-lingual communication. Built as a unified framework combining expressive voice preservation and streaming translation capabilities, Seamless enables natural-sounding, low-latency, and massively multilingual speech-to-speech and speech-to-text translation for nearly 100 languages.
Unlike conventional pipelines that treat translation as a purely textual or static task, Seamless understands that human communication is dynamic, expressive, and multimodal. Whether you’re running an international customer support line, facilitating a multilingual team meeting, or localizing media for global audiences, Seamless brings the nuance, speed, and linguistic breadth needed to make interactions feel truly human—even when mediated by AI.
What Makes Seamless Unique?
Seamless isn’t just another machine translation model. It’s a family of purpose-built systems that address three critical gaps in current translation technology:
1. Expressive Translation That Preserves Human Prosody
Most speech translation systems flatten vocal delivery into a monotone output—losing speech rate, pauses, and emotional tone. SeamlessExpressive solves this by preserving key prosodic elements across languages. It doesn’t just translate what you say—it captures how you say it. This includes subtle timing cues like natural pauses and variable speech rates, which are essential for conveying intent, emphasis, and emotion in real conversations.
2. Streaming Translation with Minimal Latency
Waiting for a speaker to finish before translating creates awkward delays. SeamlessStreaming uses Efficient Monotonic Multihead Attention to generate translations incrementally, as speech arrives—enabling simultaneous speech-to-speech and speech-to-text translation without full-utterance buffering. This is the first publicly available system to support streaming multimodal translation across dozens of language pairs in real time.
3. Massive Multilingual Coverage from a Single Foundation
All Seamless models are built on SeamlessM4T v2, a massively multilingual and multimodal foundation model trained on significantly more low-resource language data than its predecessor. It supports five core tasks:
- Speech-to-Speech Translation (S2ST)
- Speech-to-Text Translation (S2TT)
- Text-to-Speech Translation (T2ST)
- Text-to-Text Translation (T2TT)
- Automatic Speech Recognition (ASR)
This unified architecture ensures consistent performance across modalities and languages—eliminating the need to stitch together separate ASR, MT, and TTS systems.
Real-World Applications
Seamless shines in scenarios where speed, naturalness, and language inclusivity matter:
- Global Customer Support: Agents can assist callers in real time with expressive, non-robotic translated responses, improving user satisfaction.
- Multilingual Meetings: Participants speak in their native language while receiving immediate, prosodically faithful translations—preserving conversational flow.
- Media Localization: Dubbing or subtitling can retain the original speaker’s vocal style, making localized content feel more authentic.
- Cross-Border Collaboration: Researchers, developers, or field workers can communicate seamlessly across language barriers without scheduling interpreters or sacrificing nuance.
Getting Started with Seamless
Seamless is open-source and designed for practical adoption. Here’s how to begin:
Installation
Seamless runs on Linux (x86-64) and Apple Silicon Macs. Install via pip:
pip install .
Note: Ensure
ffmpegis installed for audio processing (required by Whisper, used internally for evaluation).
Running Inference
The CLI offers intuitive commands for common tasks:
-
Speech-to-Speech Translation:
m4t_predict input.wav --task s2st --tgt_lang fra --output_path output_french.wav
-
Text-to-Text Translation:
m4t_predict "Hello, how are you?" --task t2tt --src_lang eng --tgt_lang spa
-
Expressive S2ST:
expressivity_predict input.wav --tgt_lang deu --model_name seamless_expressivity --vocoder_name vocoder_pretssel --output_path output_expressive.wav
For interactive exploration, the NeurIPS 2023 Seamless EXPO tutorial notebook provides end-to-end examples. Hugging Face Spaces also host live demos for SeamlessM4T v2, SeamlessExpressive, and SeamlessStreaming.
Model Access
- SeamlessM4T v2 and SeamlessStreaming are publicly available under CC-BY-NC 4.0.
- SeamlessExpressive requires a request form due to its expressive vocoder; access is granted under a custom license with an Acceptable Use Policy.
- The W2v-BERT 2.0 speech encoder (core to all models) is MIT-licensed and usable independently.
Limitations and Practical Notes
While powerful, Seamless has constraints to consider:
- Hardware: Only supports Linux and Apple Silicon; Windows is not officially supported.
- Dependencies: Relies on
fairseq2andffmpeg; installation may require system-level setup. - Licensing: Different components carry different licenses—review carefully for commercial use.
- Expressive Model Access: SeamlessExpressive isn’t immediately downloadable; approval is needed.
- Evaluation: Metrics like BLASER 2.0 (used for speech translation quality) depend on Meta’s SONAR embeddings, which are included but add complexity.
These considerations don’t diminish Seamless’s innovation—they simply reflect the state-of-the-art trade-offs in deploying cutting-edge multimodal AI responsibly.
Summary
Seamless sets a new standard for real-time multilingual communication by unifying expressivity, streaming capability, and broad language coverage in a single, open system. It directly tackles the robotic tone, high latency, and narrow language support that plague existing tools—making it uniquely suited for applications where authenticity and immediacy are non-negotiable. With publicly available code, models, and tutorials, Seamless empowers developers, researchers, and organizations to build more natural, inclusive, and responsive cross-language experiences—today.