Processing unstructured data—like free-form text, documents, or multimodal inputs—with large language models (LLMs) has become essential across industries, from biomedical research to fact-checking and AI agent evaluation. Yet current approaches often rely on brittle, ad-hoc pipelines: custom scripts stitched together with manual prompts, lacking performance guarantees, expressiveness, or robustness.
Enter Semantic Operators, a declarative programming model introduced by the LOTUS framework that reimagines AI-based data processing. By extending the familiar relational algebra used in structured databases to unstructured data through natural language specifications, Semantic Operators let you express complex data transformations—filtering, joining, grouping, ranking—with simple, high-level commands.
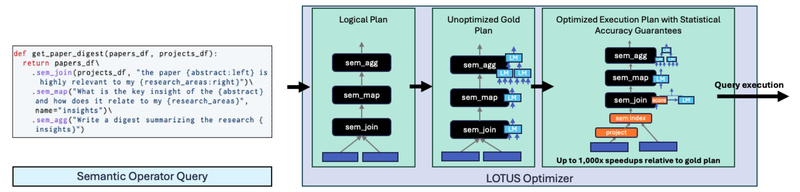
LOTUS (LLMs Over Text, Unstructured and Structured Data) implements this model with a Pandas-like API, enabling data practitioners to write concise, readable code while automatically optimizing execution for speed and accuracy. It delivers up to 1,000× speedups over naive LLM usage and provides accuracy guarantees relative to high-quality reference implementations. For technical decision-makers evaluating tools for scalable, reliable LLM-powered analytics, Semantic Operators offer a compelling alternative to fragmented, error-prone workflows.
Why Semantic Operators Matter
Traditional LLM pipelines treat each operation as a one-off: you write a prompt, call an API, parse the output, and hope it works consistently. This approach is hard to scale, debug, or optimize. Worse, it offers no formal contract about what the operation should do—leading to silent failures or inconsistent results.
Semantic Operators solve this by introducing a declarative abstraction: you specify what you want (e.g., “Join courses with skills they teach”) using natural language, not how to do it. The system then selects the best execution strategy—using LLMs, embeddings, rerankers, or hybrid methods—while ensuring the output meets defined quality standards.
This model mirrors how SQL revolutionized structured data: instead of writing loops to match records, you declare a JOIN condition. Now, with Semantic Operators, you can do the same for fuzzy, semantic relationships in unstructured data.
Key Strengths of LOTUS
Familiar, Pandas-Like Syntax
If you know Pandas, you can use LOTUS immediately. Operations like sem_filter, sem_join, and sem_topk behave like their structured counterparts—but accept natural language expressions (called langex) to define logic:
df.sem_filter("This article discusses climate policy in the EU")
This lowers the barrier to entry for data engineers and analysts who want to leverage LLMs without becoming prompt engineers.
Built-In Optimizations for Speed and Cost
LOTUS doesn’t just call LLMs blindly. Its optimization framework explores multiple execution plans—caching, batching, switching to embedding-based similarity when appropriate, or pruning irrelevant records early. These techniques yield up to 1,000× speedups over naive implementations while preserving result quality.
Accuracy Guarantees
Every Semantic Operator is defined against a “gold algorithm”—a high-quality reference implementation. LOTUS ensures that optimized executions stay within acceptable error bounds of this reference, giving you confidence in results even when using faster, approximate methods.
Unified Support for LLMs, Embeddings, and Rerankers
LOTUS integrates seamlessly with models from OpenAI, Ollama, vLLM (via LiteLLM), Sentence Transformers, and CrossEncoders. You can mix modalities—e.g., use embeddings for candidate generation and an LLM for final verification—without leaving the same API.
Real-World Use Cases
Semantic Operators excel in scenarios where traditional structured queries fall short:
- Fact-checking: Filter claims from news articles based on verifiability statements.
- Biomedical multi-label classification: Assign multiple disease tags to clinical notes using natural criteria.
- Semantic search: Retrieve relevant documents using expressive, contextual queries.
- Topic analysis: Group and summarize large corpora by emergent themes.
- AI agent evaluation: Analyze agent interaction logs to identify failure patterns or assess reasoning quality.
In each case, what once required custom parsing, brittle regex, or manual LLM orchestration can now be expressed in 1–2 lines of LOTUS code—with better performance and reliability.
Getting Started Is Straightforward
To begin, install LOTUS via uv or pip, configure your preferred language model (e.g., GPT-4o, Llama 3, or any LiteLLM-supported model), and start chaining Semantic Operators on Pandas DataFrames.
Natural language expressions use column placeholders like {text} or {title}, making them intuitive:
df.sem_join(ref_df, "{Document} provides evidence for {Claim}")
Tutorials walk you through multimodal processing, agent trace analysis, and system prompt debugging—all using the same core API.
Practical Limits and Considerations
While powerful, Semantic Operators depend on external models, so LLM costs can accumulate with large datasets—though LOTUS’s optimizations mitigate this significantly.
On macOS, installing FAISS (for embedding-based operations) requires Conda if using pip, though the uv installer handles this automatically.
Finally, while the framework guarantees accuracy relative to a gold algorithm, the absolute quality still depends on your chosen model and prompt clarity. Thoughtful langex design remains important.
Summary
Semantic Operators represent a paradigm shift in AI-powered data processing: declarative, robust, and optimized. By unifying LLMs, embeddings, and traditional data operations under a single, expressive model, LOTUS enables technical teams to build scalable, maintainable pipelines for unstructured data—without sacrificing speed or correctness.
For project leads, researchers, and data practitioners tired of stitching together fragile LLM scripts, Semantic Operators offer a principled, productive, and performant alternative that just works.