Building capable robotic systems that understand vision, language, and action—commonly referred to as Vision-Language-Action (VLA) models—has become a central goal in robotics research. However, practical deployment remains bottlenecked by two persistent challenges: the scarcity of large-scale human-collected robot trajectories needed for supervised fine-tuning (SFT), and poor generalization when tasks shift even slightly in object arrangement, spatial layout, or goal description.
Enter SimpleVLA-RL, a lightweight yet powerful reinforcement learning (RL) framework specifically designed to overcome these limitations. By leveraging only binary (0/1) success/failure rewards from simulation environments, SimpleVLA-RL dramatically enhances long-horizon action planning in VLA models—without requiring massive labeled datasets. Remarkably, it not only matches but surpasses traditional SFT methods, even in real-world settings, while uncovering entirely new robotic behaviors during training.
Why SimpleVLA-RL Solves Real Problems in Robotics
Most current VLA systems rely heavily on SFT, which demands extensive demonstration data collected by human operators—a process that is expensive, time-consuming, and often impractical for scaling across diverse tasks. Worse still, SFT-trained policies frequently fail when faced with minor environmental changes, limiting their usefulness in dynamic or unstructured real-world scenarios.
SimpleVLA-RL directly addresses these pain points:
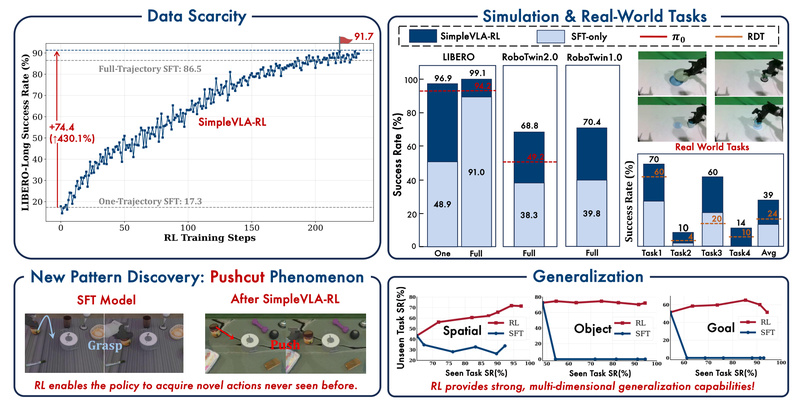
- Data efficiency: It starts from a minimally trained SFT model—even one fine-tuned on just a single trajectory per task—and uses online RL to iteratively refine policy performance.
- Robust generalization: It demonstrates strong transfer across spatial configurations, object identities, and goal variations, as validated on the LIBERO benchmark suite.
- Real-world readiness: Despite using only simulation-based rewards, policies trained with SimpleVLA-RL outperform SFT baselines not just in simulation but also in physical robot experiments.
This makes SimpleVLA-RL particularly valuable for research labs, robotics startups, and industrial automation teams that need high-performing policies but lack the resources to collect thousands of expert demonstrations.
Key Technical Advantages
SimpleVLA-RL isn’t just another RL wrapper—it’s purpose-built for VLA models, with several innovations that enable scalable and stable training:
Minimal Reward Design
Unlike complex reward shaping, SimpleVLA-RL uses only outcome-level 0/1 rewards—did the robot complete the task or not? This simplifies reward engineering and aligns with real-world scenarios where only task success is observable.
Massive Performance Gains
On the LIBERO-Long benchmark, SimpleVLA-RL boosts OpenVLA-OFT’s success rate from 17.3 to 91.7 when starting from a one-trajectory SFT model—an improvement of 74.4 points (430.1%). It achieves a new state-of-the-art score of 97.6, even outperforming the (p_0) baseline on RoboTwin 1.0 & 2.0.
Emergence of Novel Behaviors
During RL training, the policy discovered a previously unseen action pattern dubbed “pushcut”—a coordinated pushing-and-cutting motion not present in any training demonstrations. This highlights RL’s ability to explore and exploit action sequences beyond human-provided examples.
Scalable Infrastructure
Built on veRL, SimpleVLA-RL supports:
- VLA-specific trajectory sampling
- Multi-environment parallel rendering
- Optimized loss computation
- Seamless scaling from single-node (8 GPUs) to multi-node clusters
This infrastructure ensures efficient use of hardware and rapid iteration—critical for practical deployment.
Getting Started: From Setup to Training
SimpleVLA-RL is designed for practitioners who want to enhance existing VLA models with minimal overhead:
- Environment Setup: Install the veRL framework and OpenVLA-OFT, following their respective guides.
- Load an SFT Model: Use a pre-trained SFT checkpoint—even one trained on only one trajectory per task (e.g.,
libero-10 traj1 SFT). - Configure Training: Edit the provided
run_openvla_oft_rl.shscript to set:- Your Weights & Biases (WandB) API key
- Experiment name and checkpoint paths
- Target dataset (
libero_10,libero_spatial, etc.) - GPU and node counts (tested on 8×A800 per node)
- Launch Training: Run the script to begin online RL training.
- Evaluate: Set
trainer.val_only=Truein the same script to run evaluation without training.
The entire pipeline is script-driven, reproducible, and designed for cluster deployment—making it accessible to both individual researchers and engineering teams.
Limitations and Current Scope
While powerful, SimpleVLA-RL has boundaries that users should consider:
- Benchmark support is currently limited to LIBERO and RoboTwin. Integration with other robotic environments requires extension.
- An initial SFT model is required, though it can be trained on extremely sparse data (as little as one trajectory per task).
- The framework has been validated on specific hardware (NVIDIA A800 GPUs, CUDA 12.4), though it may work on similar setups.
- It remains in preview stage, with ongoing development for features like Pi0 fast tokenizer support and broader model compatibility.
These limitations don’t undermine its core value but help set realistic expectations for integration into existing workflows.
Summary
SimpleVLA-RL redefines how we scale and generalize VLA models in robotics. By replacing data-hungry SFT with efficient, reward-sparse RL, it enables dramatic performance improvements with minimal human demonstration data—while unlocking novel behaviors and strong cross-task generalization. For teams building next-generation robotic agents, SimpleVLA-RL offers a practical, scalable path from simulation to real-world success.