SkyThought is an open-source framework built around S*—a breakthrough test-time scaling approach designed specifically to elevate code generation performance in large language models (LLMs). Unlike traditional methods that require costly retraining or larger model sizes, SkyThought leverages smarter inference-time computation to dramatically improve both the coverage and correctness of generated code.
What makes SkyThought stand out is its ability to help even modestly sized models—like a 3B-parameter variant—outperform powerful closed-source models such as GPT-4o-mini on rigorous coding benchmarks like LiveCodeBench. This is achieved not through architectural changes or massive data pipelines, but through an elegant, execution-aware scaling strategy that anyone can plug into their existing workflow.
Fully open-source and easy to integrate, SkyThought empowers researchers, engineers, and students to push the limits of code generation without sacrificing transparency or reproducibility.
Why Code Generation Needs Better Test-Time Strategies
Code generation remains a uniquely challenging domain for LLMs. While models can produce syntactically valid programs, ensuring logical correctness—especially under edge cases or complex constraints—is notoriously difficult. Traditional approaches often sample multiple candidates in parallel (parallel scaling) but struggle to distinguish between plausible yet incorrect solutions and truly correct ones.
This leads to two key problems:
- Low coverage: Correct programs are rarely generated, even with many samples.
- Poor selection: Existing scoring mechanisms (e.g., log-likelihood or heuristics) fail to reliably pick the right solution from a set of candidates.
SkyThought’s S* framework directly addresses both issues—not by changing the model, but by making inference smarter.
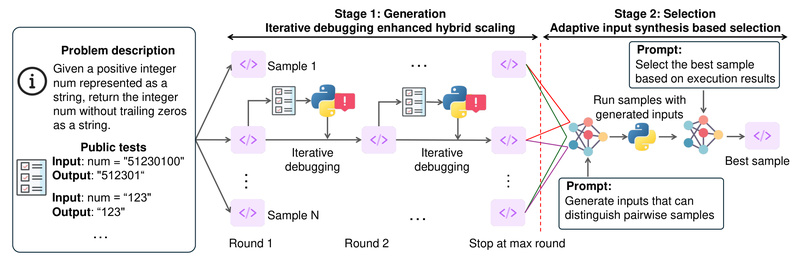
How S* Works: Hybrid Scaling Meets Execution-Grounded Validation
At the core of SkyThought is S***, the first **hybrid test-time scaling framework for code generation. It combines two powerful ideas:
Parallel + Sequential Scaling
Most scaling methods only generate multiple candidates in parallel. S* goes further by introducing sequential refinement: after initial candidates are generated, the system adaptively explores additional variations based on early signals, effectively expanding the search space in a directed way. This boosts the chance that a correct program appears among the outputs.
Adaptive Input Generation for Pairwise Comparison
Instead of relying on static tests or likelihood scores, S* dynamically generates distinguishing inputs—small test cases designed to expose behavioral differences between two candidate programs. If one program passes and the other fails, S* uses that evidence to guide its selection.
Execution-Grounded Scoring
Every candidate is validated against real program executions. This ground-truth feedback loop ensures that only functionally correct programs are promoted, dramatically increasing selection accuracy.
The result? S* consistently improves performance across model families, sizes, and coding difficulty levels—without a single parameter update.
Real Gains: From Benchmarks to Practical Impact
Empirical results speak volumes:
- GPT-4o-mini + S*** outperforms **o1-preview by 3.7% on LiveCodeBench.
- DeepSeek-R1-Distill-Qwen-32B + S*** reaches **85.7% on LiveCodeBench—closing in on o1 (high) at 88.5%.
- A **3B-parameter model with S*** beats GPT-4o-mini in code correctness.
These aren’t incremental improvements—they represent a paradigm shift in how we think about inference-time compute: not as a cost to minimize, but as a lever to strategically amplify correctness.
Getting Started Is Simple
SkyThought is designed for frictionless adoption:
-
Install via PyPI or from source:
pip install skythought
or
git clone https://github.com/NovaSky-AI/SkyThought.git cd SkyThought uv pip install -e .
-
Run evaluations with one command:
skythought evaluate --model NovaSky-AI/Sky-T1-32B-Preview --task LiveCodeBench
-
Use the Scorer API to integrate S*-style validation into your own pipelines during data curation or evaluation.
SkyThought natively supports major coding and reasoning benchmarks, including LiveCodeBench, APPS, TACO, and more—making it ideal for research, competitive programming prep, or automated code assessment systems.
Ideal Use Cases
SkyThought shines in scenarios where code correctness is non-negotiable:
- Automated software engineering (e.g., AI-assisted coding tools)
- Programming competition training (e.g., AIME, OlympiadBench)
- Research on test-time scaling and code LLM robustness
- Model evaluation pipelines that demand execution-based validation
It works across diverse model architectures and sizes, from 3B to 32B parameters, and integrates seamlessly with open-source models like those in the Sky-T1 series.
Limitations to Consider
While powerful, SkyThought isn’t a universal fix:
- It’s optimized for code and reasoning-heavy tasks—it may not add value for general QA or non-executable text generation.
- Test-time compute increases due to parallel/sequential sampling and execution—users should balance accuracy gains against latency or cost budgets.
- Requires a sandboxed execution environment to safely run generated code during evaluation.
That said, for code-focused applications, the trade-off is often worth it.
Why SkyThought Stands Out in the Open Ecosystem
In an era where many top-performing models (like o1-preview or QwQ) remain closed, SkyThought is fully open: model weights, training data, recipes, and evaluation code are all available. This enables:
- Full reproducibility of results
- Community-driven improvements and extensions
- Transparent benchmarking without black-box assumptions
By open-sourcing everything—from RL training scripts to data curation logic—SkyThought lowers the barrier for anyone to build, validate, and deploy state-of-the-art code generation systems.
Summary
SkyThought redefines what’s possible at test time for code-generating LLMs. With its S* framework, it turns inference into an active, adaptive process that prioritizes functional correctness over superficial fluency. Whether you’re a researcher pushing the boundaries of AI reasoning, an engineer building coding assistants, or a student exploring LLM capabilities, SkyThought offers a practical, open, and highly effective toolkit to generate better code—without retraining a single model.