Deploying large language models (LLMs) in production is expensive—not just in dollars, but in compute and memory. While models like Llama-3, Mistral, and Falcon deliver remarkable performance, their full-precision (FP16 or FP32) inference demands multiple high-end GPUs, inflating cloud bills and limiting accessibility.
SmoothQuant solves this bottleneck with a training-free, post-training quantization (PTQ) technique that enables accurate 8-bit weight and 8-bit activation (W8A8) quantization for LLMs—without sacrificing model quality. Developed by MIT and NVIDIA researchers, it’s not just a research curiosity: it’s already integrated into TensorRT-LLM, ONNX Runtime, Amazon SageMaker, and Intel Neural Compressor, proving its readiness for real-world deployment.
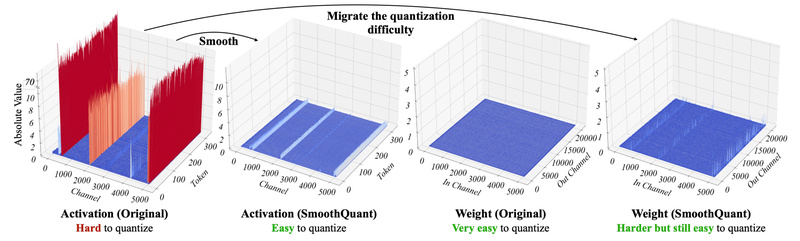
By mathematically shifting quantization difficulty from hard-to-quantize activations to easier-to-quantize weights, SmoothQuant smooths out activation outliers and unlocks INT8 inference across major LLM architectures—including Llama-1/2/3, Falcon, Mistral, Mixtral, OPT, BLOOM, and even massive 530B-parameter models. The result? Up to 1.56× faster inference and 2× memory reduction with negligible accuracy loss.
Why SmoothQuant Matters: Turning LLM Deployment from “Possible” to “Practical”
Technical decision-makers face a stark trade-off: either run expensive full-precision models or risk accuracy collapse with naive quantization. Traditional PTQ methods fail on LLMs because activations contain extreme outliers that distort quantization error, leading to severe performance degradation.
SmoothQuant eliminates this dilemma. Instead of applying quantization naively, it performs an offline, mathematically equivalent transformation that “smooths” activation distributions by rescaling channels and compensating in the weights. This preserves the model’s input-output behavior while making both weights and activations amenable to INT8 representation.
Critically, no retraining or fine-tuning is required. This turn-key approach lets teams quantize and deploy models in hours—not weeks—making SmoothQuant ideal for rapid production rollout under tight timelines.
Key Strengths: Accuracy, Speed, and Simplicity
Near-FP16 Accuracy with W8A8 Quantization
SmoothQuant’s perplexity results speak volumes. On Llama-2-70B, FP16 achieves 3.320 PPL, while SmoothQuant W8A8 reaches 3.359—a difference of just 0.039. Similar fidelity is observed across Mistral-7B (5.253 → 5.277), Mixtral-8x7B (3.842 → 3.893), and Falcon-40B (5.228 → 5.255). For most real-world applications, this gap is negligible.
Real Hardware Acceleration—Not Just Theoretical
Unlike earlier methods like LLM.int8(), which preserved accuracy but slowed inference due to mixed-precision overhead, SmoothQuant delivers actual speedups. When deployed in optimized backends like TensorRT-LLM or FasterTransformer, it achieves up to 1.56× faster inference and halves GPU memory usage.
For example, OPT-66B runs on 1 GPU with SmoothQuant instead of 2 in FP16; OPT-175B runs on 4 instead of 8. Most impressively, the 530B MT-NLG model can be served on a single node—a feat previously unattainable without extreme resource allocation.
Training-Free and Framework-Agnostic
SmoothQuant operates entirely post-training. You don’t need access to original training pipelines, labeled data, or compute clusters for fine-tuning. Just calibrate on a small unlabeled dataset (e.g., 512 samples from The Pile), apply smoothing, and quantize. Precomputed activation scales are provided for all major models, enabling immediate adoption.
Ideal Use Cases: Where SmoothQuant Shines
SmoothQuant is purpose-built for production LLM deployment scenarios:
- Cost-Constrained Inference: Reduce cloud GPU bills by 30–50% through halved memory footprint and faster throughput.
- Edge or On-Premise Serving: Deploy 7B–70B models on fewer GPUs, making on-device or private-cloud LLM serving feasible.
- Massive-Model Accessibility: Serve 100B+ parameter models (e.g., Falcon-180B, MT-NLG-530B) on a single server node.
- Integration into Existing Pipelines: Leverage native support in TensorRT-LLM, ONNX Runtime, SageMaker, and Intel Neural Compressor—no framework overhaul needed.
If your goal is to ship a high-quality LLM with minimal latency, memory, and cost overhead, SmoothQuant is among the most reliable PTQ options available today.
Getting Started: A Practical Workflow
Adopting SmoothQuant is straightforward:
- Obtain Activation Scales: Precomputed scales for Llama, Mistral, Mixtral, Falcon, OPT, and BLOOM are included in the repository under
act_scales/. - Apply Smoothing: Use the provided scripts (
export_int8_model.py) to transform the model by migrating quantization difficulty from activations to weights. - Run Inference: Load a pre-quantized model from Hugging Face (e.g.,
mit-han-lab/opt-30b-smoothquant) or deploy via TensorRT-LLM for maximum speed. - Custom Models? Use
generate_act_scales.pyto collect activation statistics from your own calibration data (e.g., internal logs or public datasets).
For quick validation, the smoothquant_opt_demo.ipynb and smoothquant_llama_demo.ipynb notebooks demonstrate accuracy parity and memory savings using fake quantization—no special hardware required.
Limitations and Considerations
SmoothQuant is powerful but not universal:
- Post-Training Only: It does not support quantization-aware training (QAT). If your workflow requires retraining, consider complementary approaches.
- Calibration Dependency: While default scales cover major models, custom architectures or domains may require collecting new activation statistics.
- Hardware Backend Matters: Full speed benefits require INT8-optimized kernels (e.g., CUTLASS, TensorRT). PyTorch-only inference may see modest gains unless paired with
torch-int.
Always verify compatibility with your serving stack—though integration is broad, edge cases may arise with niche runtimes.
Real-World Adoption and Ecosystem Support
SmoothQuant’s industry traction underscores its production readiness:
- Integrated into NVIDIA TensorRT-LLM for maximum throughput on A100/H100.
- Available in Amazon SageMaker for managed LLM deployments.
- Supported in Microsoft ONNX Runtime for cross-platform inference.
- Included in Intel Neural Compressor for CPU and GPU optimization.
- Recently enabled on AMD Instinct MI300X via Composable Kernel.
This ecosystem support means you’re not betting on a research prototype—you’re adopting a standard already vetted by cloud providers and chipmakers.
Summary
SmoothQuant redefines what’s possible with post-training quantization for LLMs. By enabling accurate, efficient W8A8 inference without retraining, it directly addresses the cost, memory, and scalability barriers that prevent many teams from deploying state-of-the-art language models. With strong accuracy retention, real speedups, and deep integration across the AI infrastructure stack, it’s a pragmatic, production-ready solution for technical decision-makers aiming to deploy LLMs faster, cheaper, and wider.