Steel-LLM is a 1-billion-parameter open-source language model developed entirely from scratch with a strong focus on Chinese language understanding and generation. What makes it stand out isn’t just its competitive benchmark scores—it’s the project’s unwavering commitment to transparency, reproducibility, and accessibility for developers, researchers, and small teams operating under limited computational budgets.
Unlike many large language models (LLMs) that release only final weights or vague training descriptions, Steel-LLM provides the full stack: raw data collection pipelines, preprocessing scripts, model architecture modifications, training code, and checkpoint weights. This end-to-end openness enables practitioners to not only use the model but also understand, replicate, and extend every stage of its development.
Why Steel-LLM Matters for Chinese-Centric Applications
Most open-source LLMs under 2B parameters either underperform on Chinese tasks or lack detailed documentation of their training process. Steel-LLM directly addresses this gap by delivering strong performance on standard Chinese benchmarks while being built with publicly shareable methods and code.
The model was trained on approximately 1 trillion tokens, with over 80% of the data in Chinese—including sources like Baidu Baike, Zhihu Q&A, BELLE dialogues, and Wikipedia. A small portion of English data was intentionally included to maintain cross-lingual robustness, but the core design prioritizes native Chinese fluency, making it ideal for applications where Chinese is the primary language.
Competitive Performance Despite Modest Scale
Steel-LLM punches above its weight class. On the CEVAL benchmark—a widely used evaluation suite for Chinese knowledge and reasoning—it achieves a score of 41.9, outperforming early versions of larger institutional models like ChatGLM-6B (38.9) and even approaching the performance of some 2B-scale models. On CMMLU, a benchmark focused on Chinese subject mastery, it scores 36.1, significantly ahead of TinyLlama (24.0) and Phi-2 (24.2).
These results demonstrate that with careful data curation, efficient architecture choices, and transparent iteration, a 1B-parameter model can deliver practical value—especially in Chinese-language contexts—without requiring massive compute clusters.
Architecture and Training Innovations
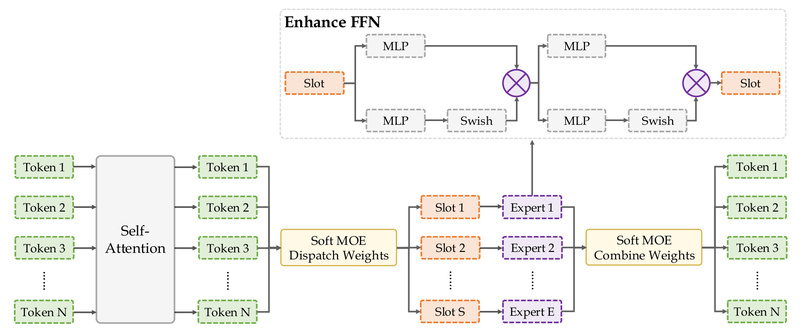
Steel-LLM is based on Qwen1.5 but introduces two key modifications to enhance training efficiency and model expressiveness under parameter constraints:
- Softmax-based Mixture-of-Experts (MoE) in the FFN layers: This design allows dynamic activation of sub-networks during training and inference, improving throughput and expressivity without drastically increasing the active parameter count.
- Dual-layer SwiGLU activation: Replacing standard feed-forward blocks with stacked SwiGLU layers increases non-linearity and learning capacity while maintaining compatibility with existing training frameworks.
The training pipeline builds on TinyLlama’s pretraining code but adds critical enhancements:
- Full support for Hugging Face model formats
- Resumable training with exact data checkpointing
- On-the-fly data validation and consistency checks
- Ability to append new datasets without restarting training
These features make the training process not only more robust but also far more accessible to teams without dedicated MLOps infrastructure.
Getting Started: Simple Integration for Prototyping and Deployment
Using Steel-LLM in your project requires just a few lines of code. It’s available on both Hugging Face Hub and ModelScope, and supports standard chat templating for instruction-following use cases.
For example, with ModelScope:
from modelscope import AutoModelForCausalLM, AutoTokenizer
model = AutoModelForCausalLM.from_pretrained( "zhanshijin/Steel-LLM", torch_dtype="auto", device_map="auto"
)
tokenizer = AutoTokenizer.from_pretrained("zhanshijin/Steel-LLM")
messages = [{"role": "user", "content": "你是谁开发的?"}]
text = tokenizer.apply_chat_template(messages, tokenize=False, add_generation_prompt=True)
inputs = tokenizer([text], return_tensors="pt").to(model.device)
outputs = model.generate(**inputs, max_new_tokens=512)
response = tokenizer.decode(outputs[0][inputs.input_ids.shape[1]:], skip_special_tokens=True)
print(response)
This simplicity lowers the barrier to experimentation, enabling rapid prototyping of Chinese chatbots, educational assistants, or content-generation tools. Inference can run on consumer-grade GPUs (e.g., RTX 3090/4090) or even CPU with quantization, though full fine-tuning requires server-grade hardware.
Ideal Use Cases
Steel-LLM excels in scenarios where:
- A Chinese-first language model is required
- Compute or budget constraints rule out 7B+ models
- Transparency and reproducibility are non-negotiable (e.g., academic research, compliance-sensitive domains)
- You need a solid base model for fine-tuning on domain-specific Chinese tasks (legal, medical, customer support, etc.)
It’s particularly well-suited for startups, university labs, or independent developers who want a performant, inspectable, and modifiable foundation without relying on black-box APIs or poorly documented open weights.
Key Limitations to Consider
While Steel-LLM delivers strong results for its size, users should be aware of its boundaries:
- Not optimized for English-only tasks: Performance on English benchmarks is not competitive with English-centric models of similar scale.
- Limited reasoning and math capabilities: The model was not trained on specialized STEM or formal logic datasets, so complex reasoning or quantitative tasks may yield unreliable results.
- 1B parameter ceiling: It will naturally underperform compared to 7B+ models on advanced multi-step reasoning or knowledge-intensive tasks.
- Training requires significant GPU resources: Full pretraining used 8×H800 GPUs for ~30 days; fine-tuning from scratch isn’t feasible on consumer hardware, though inference and lightweight tuning (e.g., LoRA) are accessible.
Summary
Steel-LLM proves that high-quality, open, and reproducible language models are achievable even with modest resources—provided the process is transparent, data is thoughtfully curated, and the community is invited to learn and build together. For teams focused on Chinese-language AI applications, it offers a rare combination: competitive performance, full code and data pipeline access, and a clear path to customization. If your project demands a trustworthy, inspectable, and effective Chinese LLM under 2B parameters, Steel-LLM is a compelling choice worth exploring.