Step-Audio 2 is an open-source, end-to-end multimodal large language model (MLM) purpose-built for real-world audio understanding and natural speech conversation. Unlike traditional automatic speech recognition (ASR) systems that transcribe speech into text and stop there, Step-Audio 2 integrates semantic comprehension, paralinguistic reasoning (e.g., emotion, age, speaking style), and tool-augmented response generation into a single unified architecture. Designed for industry deployment, it bridges the gap between academic prototypes and production-ready voice AI—offering developers, product teams, and researchers a powerful, transparent, and customizable alternative to closed commercial APIs.
Built on millions of hours of multilingual speech and audio data, Step-Audio 2 leverages a latent audio encoder, reinforcement learning for reasoning, and retrieval-augmented generation (RAG) to deliver accurate, expressive, and contextually grounded interactions. Its mini variants—Step-Audio 2 mini, mini Base, and mini Think—are openly released under the permissive Apache 2.0 license, enabling immediate experimentation and integration.
Core Capabilities That Redefine Audio AI
End-to-End Audio Understanding with Paralinguistic Intelligence
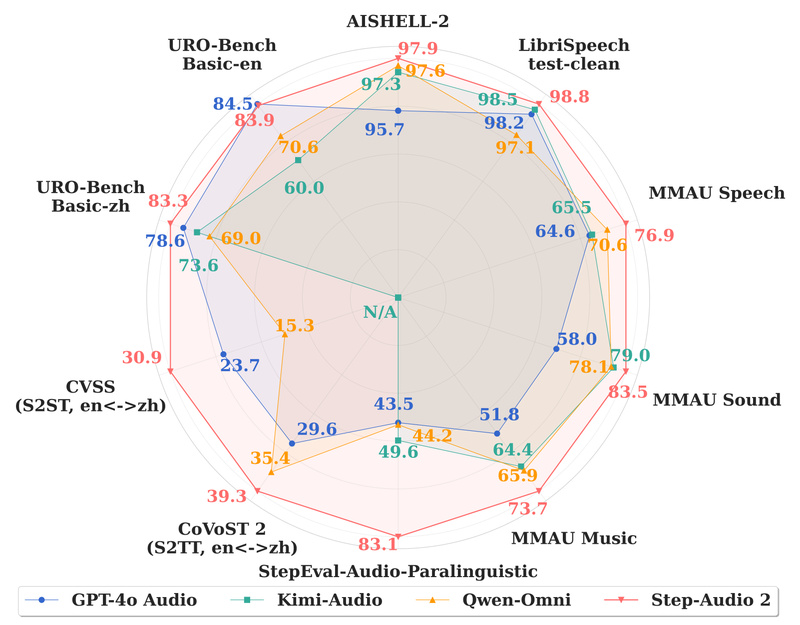
Step-Audio 2 doesn’t just hear words—it interprets how they’re spoken. The model excels at understanding paralinguistic cues such as emotion, age, timbre, pitch, rhythm, and speaking speed. On the StepEval-Audio-Paralinguistic benchmark, Step-Audio 2 achieves an average score of 83.09%, far surpassing GPT-4o Audio (43.45%), Kimi-Audio (49.64%), and Qwen-Omni (44.18%). This makes it uniquely suited for applications where emotional tone or speaker identity matters—such as empathetic customer service agents or personalized voice assistants.
State-of-the-Art ASR Across Languages and Accents
Step-Audio 2 delivers best-in-class automatic speech recognition across multiple languages, including Chinese, English, Japanese, and Arabic. Notably, it outperforms competitors on challenging in-house accent datasets (e.g., Shanghai dialect, Shanxi accent), achieving an average Character Error Rate (CER) of 8.85%—more than 50% lower than leading commercial systems like Doubao and GPT-4o. In standard benchmarks like LibriSpeech and AISHELL, it consistently ranks at or near the top.
Seamless Speech-to-Speech Conversation
Unlike models that require separate ASR and TTS pipelines, Step-Audio 2 supports true end-to-end speech conversation by generating discrete audio tokens within its language modeling framework. This enables low-latency, natural-sounding dialogues that preserve paralinguistic information. On the URO-Bench (Understanding, Reasoning, Oral conversation), Step-Audio 2 scores 83.32 for Chinese and 83.90 for English—outperforming GPT-4o Audio and others in both comprehension and oral fluency.
Tool Calling and Multimodal RAG for Grounded Responses
To combat hallucination and enhance functionality, Step-Audio 2 integrates tool calling with retrieval-augmented generation. It can invoke external tools like web search or audio search during inference—enabling dynamic behaviors such as switching speaker timbre based on retrieved voice samples or fetching real-time information. On the StepEval-Audio-Toolcall benchmark, it achieves >95% recall and >86% precision across audio search, weather, date/time, and web search tasks—matching or exceeding specialized instruction-tuned models like Qwen3-32B+.
Practical Use Cases for Developers and Product Teams
- Emotion-Aware Voice Assistants: Build assistants that adapt tone and response based on user frustration, excitement, or urgency.
- Multilingual Transcription & Translation Services: Deploy high-accuracy ASR and speech-to-speech translation (S2ST/S2TT) for global customer support or content localization.
- Intelligent Call Centers: Analyze caller sentiment, accent, and intent in real time to route calls or generate summaries.
- Voice-Enabled RAG Applications: Create voice interfaces that query live data (e.g., stock prices, weather) or retrieve similar audio clips (e.g., voice cloning with consent-based timbre switching).
Getting Started: Simple, Flexible, and Production-Ready
Step-Audio 2 is designed for rapid adoption:
- Install Dependencies: Requires Python ≥3.10, PyTorch ≥2.3 with CUDA, and standard audio libraries (
librosa,torchaudio). - Download Models: The mini variants are available on Hugging Face and ModelScope. Clone directly via Git LFS.
- Run Inference: Use provided scripts like
examples.pyorexamples-vllm.pyfor quick testing. - Deploy at Scale: Leverage the official vLLM backend for streaming, multi-GPU inference with tool-calling support via Docker.
- Prototype Locally: Launch a Gradio-based web demo in minutes with
web_demo.py.
All models are open-sourced under Apache 2.0, allowing commercial use, modification, and redistribution—ideal for startups and enterprises seeking control over their audio AI stack.
Key Limitations and Considerations
While powerful, Step-Audio 2 has practical constraints:
- Hardware Requirements: Requires a CUDA-enabled GPU and modern PyTorch; not suitable for CPU-only or edge devices without optimization.
- Language Coverage: Optimized for Chinese, English, Japanese, and Arabic; performance on low-resource languages may be limited.
- Tool Dependency: Full functionality (e.g., web/audio search) requires integration with external services—local inference without tools reduces contextual accuracy.
- Model Scope: Only the “mini” family (mini, mini Base, mini Think) is currently open-sourced; the full Step-Audio 2 model remains proprietary.
How Step-Audio 2 Stacks Up Against Alternatives
Benchmarks consistently place Step-Audio 2 at the forefront:
- Paralinguistic Understanding: 83.09% vs. 43–50% for GPT-4o, Kimi, and Qwen.
- ASR Accuracy: 3.14% average CER/WER vs. 4.18–14.05% for competitors.
- Tool Calling: >95% recall with precise parameter handling.
- Speech Translation: 39.26 average BLEU on CoVoST 2, beating GPT-4o (29.61) and Qwen-Omni (35.40).
These results validate Step-Audio 2 as a top choice for any project demanding more than basic transcription—especially where emotional intelligence, multilingual robustness, or real-time tool use are critical.
Summary
Step-Audio 2 redefines what open-source audio AI can achieve. By unifying ASR, paralinguistic reasoning, speech generation, and tool-augmented RAG in a single end-to-end framework, it offers a uniquely capable, transparent, and deployable solution for real-world voice applications. Whether you’re building the next-generation voice assistant, automating multilingual customer interactions, or researching emotion-aware dialogue systems, Step-Audio 2 provides the performance, flexibility, and openness needed to move beyond black-box commercial APIs. With its Apache 2.0 license and active open-source development, it’s not just a model—it’s a platform for the future of conversational audio AI.