Step-Video-T2V is a state-of-the-art open-source text-to-video foundation model developed by StepFun AI. With 30 billion parameters and the ability to generate videos up to 204 frames in length, it sets a new bar for fidelity, motion coherence, and multilingual support in video generation. Designed for real-world deployment, Step-Video-T2V addresses critical limitations that have historically plagued diffusion-based video models—such as blurry motion, temporal inconsistency, high computational cost, and limited language flexibility.
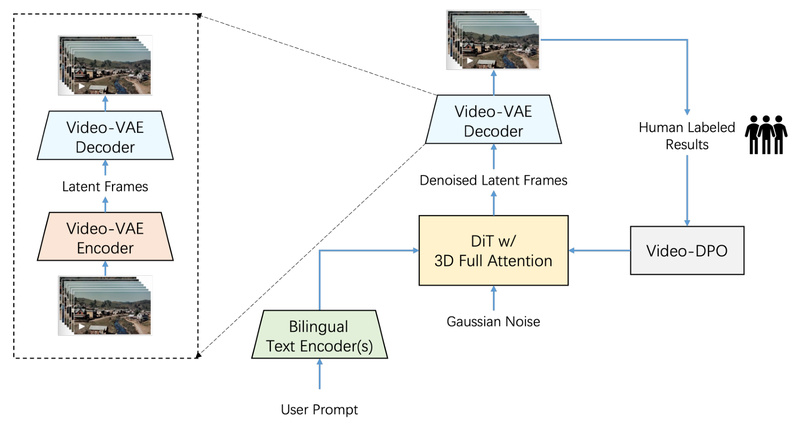
What makes Step-Video-T2V especially valuable for technical teams is its end-to-end optimization: from a deeply compressed video representation to a 3D attention-based diffusion transformer and a video-specific alignment technique that sharpens visual quality using human feedback. Whether you’re building AI-powered content pipelines, prototyping cinematic sequences, or exploring cross-lingual video applications, Step-Video-T2V offers a powerful, transparent, and benchmark-validated foundation.
Core Innovations That Solve Real Video Generation Challenges
Deeply Compressed Video-VAE for Efficiency Without Sacrificing Quality
A major bottleneck in video diffusion models is the sheer data volume of raw pixel sequences. Step-Video-T2V introduces a custom Video-VAE that achieves 16×16 spatial and 8× temporal compression—reducing the latent sequence length by over 2,000× compared to pixel space. This isn’t just about speed: the compressed representation is carefully designed to preserve fine visual details and motion dynamics, enabling both faster training and higher-resolution output (e.g., 768×768 at 204 frames).
For engineering teams, this means feasible training and inference on available GPU hardware—without resorting to heavy frame subsampling or resolution downgrades that degrade realism.
3D Full-Attention DiT for Coherent, Long-Form Motion
Unlike models that use sparse or factorized attention, Step-Video-T2V employs a Diffusion Transformer (DiT) with full 3D self-attention across space and time. This architecture processes all spatial patches and temporal frames jointly, ensuring consistent object identity, smooth motion trajectories, and global scene coherence—even in complex, multi-second videos.
Key technical enablers include:
- 3D Rotary Position Embedding (RoPE) for handling variable video lengths and resolutions
- QK-Norm in attention layers to stabilize training
- AdaLN-Single for precise timestep conditioning
These design choices directly tackle common failure modes like flickering, object duplication, or unnatural motion—issues that often require extensive post-processing in alternative systems.
Video-DPO: Aligning Outputs with Human Visual Preferences
Even high-fidelity diffusion models can produce subtle artifacts—jittery edges, inconsistent lighting, or implausible physics. Step-Video-T2V integrates Video-DPO (Direct Preference Optimization), a fine-tuning strategy that uses human-ranked video pairs to steer the model toward outputs that look more natural and visually pleasing.
Unlike reinforcement learning from human feedback (RLHF), DPO is simple, stable, and doesn’t require a reward model. In practice, this translates to videos with smoother transitions, fewer distortions, and better adherence to prompt semantics—critical for professional-grade content.
Practical Use Cases for Technical Teams
Step-Video-T2V isn’t just a research prototype—it’s built for production-grade applications:
- Multilingual Marketing Content: Generate branded video ads from prompts in English or Chinese using dual text encoders, enabling global campaigns without separate pipelines.
- Entertainment & Gaming Prototyping: Rapidly visualize storyboards, cutscenes, or character animations from textual descriptions, accelerating creative iteration.
- AI-Assisted Storytelling: Combine with LLMs to auto-generate narrative-driven video sequences for education, journalism, or social media.
- Benchmarking & Model Evaluation: Leverage the included Step-Video-T2V-Eval benchmark—a curated set of 128 real-user Chinese prompts across 11 categories—to objectively compare video models.
Getting Started: Deployment Options and Best Practices
Hardware & Software Requirements
Step-Video-T2V is resource-intensive but offers flexible deployment:
- Recommended: NVIDIA GPUs with ≥80GB VRAM (e.g., A100/H100)
- OS: Linux only
- CUDA Compute Capability: sm_80, sm_86, or sm_90
- Dependencies: Python ≥3.10, PyTorch ≥2.3, FFmpeg
Inference Strategies
-
Multi-GPU Parallel Inference (for full quality):
- Uses tensor and sequence parallelism (e.g., 4–8 GPUs)
- Separates text encoding, DiT denoising, and VAE decoding for optimal throughput
- Example command supports configurable
tp_degreeandulysses_degree
-
Single-GPU Inference via DiffSynth-Studio:
- Community integration enables quantization and VRAM reduction
- Ideal for evaluation or lower-resolution outputs on smaller hardware
Recommended Inference Settings
| Model | infer_steps | cfg_scale | time_shift |
|---|---|---|---|
| Step-Video-T2V | 30–50 | 9.0 | 13.0 |
| Step-Video-T2V-Turbo | 10–15 | 5.0 | 17.0 |
Higher cfg_scale and infer_steps improve prompt adherence and detail but increase latency. The Turbo variant uses step distillation for 3–5× faster generation with minor quality trade-offs.
Limitations and Infrastructure Considerations
While powerful, Step-Video-T2V isn’t plug-and-play for all teams:
- High VRAM demand: Full 204-frame 768×768 generation requires ~78GB GPU memory
- Linux-only: No official Windows or macOS support
- Multi-GPU complexity: Optimal throughput needs careful parallelization setup
- CUDA architecture constraints: Older GPUs (e.g., V100) are unsupported
Teams with limited GPU resources should start with the Turbo variant or leverage the online demo for rapid validation.
Performance Validation and Accessibility
Step-Video-T2V achieves state-of-the-art results on its own Step-Video-T2V-Eval benchmark, outperforming both open-source and commercial video generation systems in visual quality, motion realism, and prompt fidelity.
To experience it firsthand:
- Try the online demo: Available at yuewen.cn/videos
- Access code and weights: Fully open-sourced on GitHub (stepfun-ai/Step-Video-T2V) under permissive licensing
This transparency allows teams to audit, reproduce, and build upon the model—critical for enterprise adoption and research reproducibility.
Summary
Step-Video-T2V represents a significant leap in open, high-quality text-to-video generation. By combining deep compression, full 3D attention, and human-aligned fine-tuning, it solves core pain points in motion coherence, visual quality, and multilingual support. While it demands capable infrastructure, its modular design, benchmark validation, and open availability make it a compelling choice for technical teams serious about video foundation models. Whether you’re evaluating alternatives or building the next generation of AI video tools, Step-Video-T2V provides a robust, production-ready starting point.