Deploying large language models (LLMs) in production often runs into a hard trade-off: reduce model size and latency through quantization, or preserve accuracy at the cost of higher compute requirements. TEQ—short for Trainable Equivalent Transformation for Quantization of LLMs—offers a compelling middle ground. Developed by Intel and integrated into the open-source Neural Compressor library, TEQ enables 3- and 4-bit weight-only quantization of LLMs while maintaining near-FP32 accuracy. Crucially, it achieves this without adding any computational overhead during inference, making it ideal for latency-sensitive or resource-constrained environments.
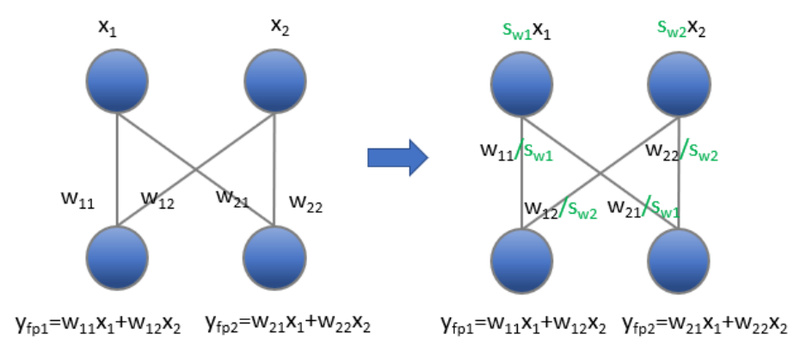
Unlike traditional quantization-aware training (QAT) that re-trains large portions of the model, TEQ introduces a lightweight, trainable transformation applied only to scaling factors. This approach preserves the model’s original output distribution while allowing aggressive weight compression—delivering state-of-the-art (SOTA) results with minimal training cost.
Why TEQ Stands Out
Minimal Training Cost, Maximum Impact
TEQ requires only ~1,000 training steps and updates fewer than 0.1% of the model’s parameters—typically just per-channel or per-tensor scaling vectors. This makes it dramatically more efficient than full fine-tuning or even most QAT methods. For teams without access to large GPU clusters or lengthy retraining pipelines, TEQ provides a practical path to high-accuracy low-bit models.
Zero Inference Overhead
Once quantized, a TEQ-transformed model runs exactly like a standard weight-only quantized model. There are no extra layers, no dynamic rescaling at runtime, and no activation modifications. This ensures compatibility with existing inference engines and maximizes throughput—especially on hardware optimized for low-bit operations.
SOTA Accuracy with Flexibility
Experiments show TEQ matches or exceeds the accuracy of leading post-training quantization (PTQ) methods on popular LLMs like Llama2, Falcon, OPT, and Bloom. Moreover, TEQ is composable: it can be combined with other techniques—such as SmoothQuant or activation clipping—to push accuracy even further.
When to Use TEQ
TEQ is particularly valuable in the following scenarios:
- Deploying LLMs on edge or data center hardware where memory bandwidth and storage are limited (e.g., Intel Gaudi AI Accelerators, Intel Xeon CPUs, or even ARM-based systems via ONNX Runtime).
- Running cost-sensitive inference workloads that demand 4-bit or even 3-bit model weights but cannot tolerate significant accuracy drops.
- Prototyping or production pipelines that rely on post-training quantization and cannot afford full retraining due to time, data, or compute constraints.
Because TEQ focuses exclusively on weight-only quantization, it is not designed for cases requiring activation quantization (e.g., full INT8 inference). However, for weight compression—a critical bottleneck in LLM deployment—it delivers exceptional efficiency.
Getting Started with TEQ
TEQ is part of Intel Neural Compressor, a comprehensive model compression toolkit supporting PyTorch, TensorFlow, and ONNX Runtime. To use TEQ:
-
Install Neural Compressor with PyTorch support:
pip install neural-compressor[pt]
-
Apply TEQ-style quantization via the library’s weight-only quantization APIs. While the exact TEQ transformation may be invoked through internal calibration and trainable scaling routines, Neural Compressor abstracts much of the complexity. Users can load pre-quantized models (e.g., from Hugging Face) or quantize their own using built-in recipes.
-
Run on supported hardware: TEQ works best on Intel platforms (Gaudi, Core Ultra, Xeon), but Neural Compressor also offers limited support for NVIDIA GPUs and AMD CPUs via ONNX Runtime.
For LLM deployment, common patterns include:
- Loading a Hugging Face model with
neural_compressor.torch.quantization.load() - Applying INT4 or FP8 quantization using framework-native APIs
- Leveraging automatic accuracy-driven tuning to select optimal quantization configs
Note that as of version 3.0, Neural Compressor encourages use of its newer 3.X APIs, though advanced compression features like trainable transformations (including TEQ) may still reside in the 2.X ecosystem.
Limitations and Practical Considerations
While powerful, TEQ has clear boundaries:
- Weight-only focus: TEQ does not quantize activations. If your use case requires full INT4/INT8 pipelines (weights + activations), you’ll need complementary techniques.
- Hardware optimization: Best performance and validation are on Intel hardware (especially Gaudi AI Accelerators). NVIDIA GPU support exists for some weight-only algorithms but is not as thoroughly tested.
- LLM-centric: Though Neural Compressor supports vision and multimodal models, TEQ was designed and evaluated primarily on LLMs like Llama2 and Falcon.
Also, ensure version compatibility between Neural Compressor, your deep learning framework (e.g., PyTorch), and underlying hardware drivers—especially when using Gaudi accelerators, where software stack versions must align precisely.
Summary
TEQ solves a critical pain point in modern LLM deployment: how to shrink models to 3- or 4-bit precision without sacrificing accuracy or slowing down inference. By introducing a lightweight, trainable equivalent transformation that incurs no runtime cost, TEQ empowers teams to ship smaller, faster, and more cost-efficient LLMs—especially on Intel infrastructure. If your project demands high-fidelity, low-bit LLM quantization with minimal engineering overhead, TEQ, through Intel Neural Compressor, is a strong candidate to evaluate.