In the era of foundation models, CLIP (Contrastive Language–Image Pretraining) has revolutionized how we approach vision-language tasks—especially zero-shot image classification. But what if you only have a handful of labeled examples per class and need better accuracy than vanilla CLIP offers, without investing in costly fine-tuning? That’s where Tip-Adapter comes in.
Tip-Adapter is a clever, training-free adaptation method for CLIP that significantly improves few-shot classification performance—without a single backpropagation step. Developed by researchers at the time of ECCV 2022, it sidesteps the computational overhead of traditional adapter methods while matching or even outperforming them. For project leads, engineers, and researchers working under tight resource constraints or rapid iteration cycles, Tip-Adapter offers a rare combination: strong performance, minimal data, and zero training.
How Tip-Adapter Works—Without Training
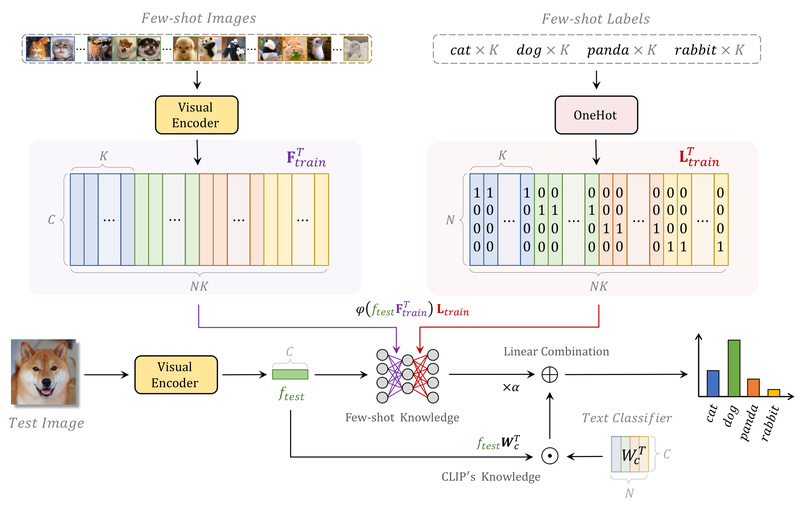
At its core, Tip-Adapter treats few-shot learning as a feature retrieval problem. Instead of learning adapter parameters through optimization, it constructs a lightweight key-value cache directly from the few-shot support set:
- Keys: CLIP visual features of the labeled support images.
- Values: Corresponding class logits derived from CLIP’s text encoder (e.g., “a photo of a [class]”).
During inference, the visual feature of a test image is compared against all keys in the cache using cosine similarity. The resulting attention weights are used to aggregate values, producing refined predictions that blend CLIP’s zero-shot prior with task-specific knowledge from the support set.
This cache-based approach is non-parametric—no parameters are learned, and no GPU-intensive training is required. Yet, it effectively adapts CLIP to new domains using as few as 1–16 examples per class.
Key Advantages for Technical Decision-Makers
1. Zero Training, Immediate Results
Unlike CLIP-Adapter or CoOp, which require fine-tuning even lightweight modules, Tip-Adapter delivers improved performance out of the box. Just prepare your few-shot dataset, extract features once, and run inference. This is ideal for environments where training pipelines are unavailable or impractical.
2. Comparable or Better Performance Than Trainable Methods
Extensive experiments across ImageNet and 10 other benchmark datasets show that Tip-Adapter matches or exceeds the accuracy of CLIP-Adapter—without any training. That alone makes it a compelling drop-in upgrade for CLIP-based systems.
3. Optional Fast Fine-Tuning (Tip-Adapter-F)
If you do have access to light GPU resources, Tip-Adapter supports a second stage: fine-tuning the pre-initialized cache model for just a few epochs (often 1–10). This “Tip-Adapter-F” variant converges 10x faster than comparable methods and frequently achieves state-of-the-art few-shot results.
4. Seamless Integration with Standard CLIP Backbones
Tip-Adapter works with any standard CLIP vision encoder—whether ResNet-50 or ViT-B/16—making it compatible with existing CLIP deployments. The official implementation provides ready-to-use config files and supports caching features for rapid hyperparameter sweeps.
Ideal Scenarios for Adoption
Tip-Adapter shines in real-world settings where:
- Labeled data is extremely scarce (e.g., medical imaging, defect detection in manufacturing, or niche retail categories).
- Deployment speed matters more than marginal accuracy gains (e.g., MVP development, proof-of-concept demos).
- Compute resources are limited (e.g., edge devices, small teams without dedicated ML infrastructure).
- You need a reliable baseline before investing in full fine-tuning.
Because it leverages CLIP’s robust vision-language alignment, Tip-Adapter also handles semantic shifts better than pure vision-only few-shot methods—critical when class names carry meaningful context (e.g., “rash,” “cracked turbine blade,” or “vintage handbag”).
Practical Getting-Started Workflow
- Prepare your few-shot dataset: A small set of labeled images (e.g., 4–16 per class).
- Extract CLIP features: Use the official script to encode support, validation, and test images.
- Run inference: The cache model is built on-the-fly; predictions are generated instantly.
- (Optional) Fine-tune: Enable Tip-Adapter-F for a quick boost—often <10 epochs with default hyperparameters.
The codebase is clean, well-documented, and mirrors common CLIP adaptation conventions (e.g., CoOp-style configs), reducing onboarding friction.
Limitations and Strategic Considerations
While powerful, Tip-Adapter is not a universal solution:
- It’s designed exclusively for few-shot image classification—not detection, segmentation, or generation.
- Performance hinges on the quality and representativeness of the support set. Noisy or atypical examples degrade results.
- The optional fine-tuning stage (Tip-Adapter-F) still requires a GPU, though far less than full adapter training.
Also, because it’s cache-based, memory usage scales linearly with the number of support samples—manageable for few-shot settings but not for large-scale training sets.
Summary
Tip-Adapter redefines what’s possible in few-shot vision-language adaptation: high performance without training. By transforming labeled examples into a static cache, it unlocks CLIP’s full potential in data-scarce scenarios while preserving its zero-shot agility. For technical leaders evaluating lightweight, deployable solutions that balance accuracy, speed, and resource efficiency, Tip-Adapter isn’t just an option—it’s a strategic advantage.