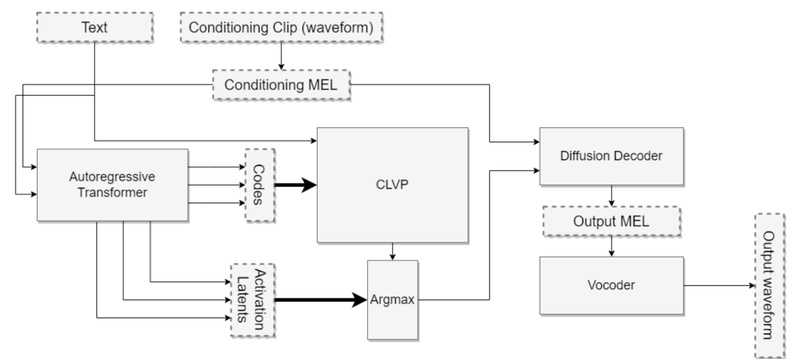
Tortoise-TTS is an open-source text-to-speech (TTS) system designed for one core purpose: generating expressive, natural-sounding speech with strong multi-voice capabilities. Built on insights from the paper “Better speech synthesis through scaling,” Tortoise-TTS leverages techniques adapted from image generation—specifically autoregressive transformers and diffusion models—to produce speech with highly realistic prosody and intonation. Unlike many commercial TTS services that prioritize speed or simplicity, Tortoise-TTS focuses on voice quality, emotional expressiveness, and voice diversity, making it uniquely suited for creative, research, and accessibility-oriented applications.
All model code and pre-trained weights are publicly available under the Apache 2.0 license, empowering developers and researchers to inspect, modify, and deploy the system without vendor lock-in or usage restrictions.
Key Strengths That Set Tortoise-TTS Apart
Realistic Prosody and Intonation
One of Tortoise-TTS’s standout features is its ability to mimic the natural rhythm, pitch variation, and emotional tone of human speech. This is achieved through a two-stage architecture: an autoregressive model that predicts coarse speech tokens, followed by a diffusion-based decoder that refines these tokens into high-fidelity audio. The result is speech that doesn’t just sound clear—it sounds human.
Multi-Voice and Voice Cloning
Tortoise-TTS supports a wide range of built-in voices (e.g., “geralt,” “tom,” “emma”), but its real power lies in custom voice cloning. By providing just a few seconds of reference audio, users can synthesize new speech in that specific voice. This is done by feeding reference clips into the model during inference, enabling personalized or character-specific narration without retraining.
Fully Open and Transparent
Unlike proprietary TTS APIs, Tortoise-TTS gives full access to both code and model weights. This transparency allows teams to audit the system, fine-tune it for specific domains, or integrate it into privacy-sensitive workflows—critical for research labs, startups, and enterprises that cannot rely on cloud-based speech services.
Ideal Use Cases
Tortoise-TTS excels in scenarios where voice quality and expressiveness matter more than raw speed. Common applications include:
- Interactive storytelling and gaming: Generate unique character voices with emotional range.
- Accessibility tools: Create personalized screen readers or audiobooks for visually impaired users.
- AI research prototypes: Experiment with voice-controlled interfaces, dialogue systems, or synthetic data generation.
- Creative audio production: Produce voiceovers for animations, podcasts, or demos without hiring voice actors.
While not optimized for real-time, low-latency use out of the box, recent optimizations—including streaming support and inference acceleration—have significantly improved performance, making it increasingly viable for near-real-time applications.
Getting Started: Practical Usage
Tortoise-TTS can be used via command-line scripts, a Python API, or Docker, offering flexibility for different deployment needs.
Command-Line Inference
The simplest way to generate speech is through do_tts.py:
python tortoise/do_tts.py --text "Hello, world!" --voice random --preset fast
Presets like fast, standard, and ultra_fast let users trade off between speed and quality based on their hardware and requirements.
Programmatic Integration
For application developers, the Python API provides fine-grained control:
from tortoise.api import TextToSpeech
from tortoise.utils.audio import load_audio
reference_clips = [load_audio(path, 22050) for path in ["sample1.wav", "sample2.wav"]]
tts = TextToSpeech()
audio = tts.tts_with_preset("Your custom text", voice_samples=reference_clips, preset='fast')
Advanced users can enable optimizations like DeepSpeed, KV caching, and FP16 precision to accelerate inference on NVIDIA GPUs.
Deployment Options
- Local GPU setup: Recommended for best performance. Official instructions support Conda environments on Windows and Linux.
- Docker: Ideal for reproducible deployments in server or cloud environments.
- Apple Silicon: Supported via PyTorch nightly builds, though DeepSpeed is disabled and some operations require fallback to CPU.
Important Limitations and Trade-offs
Despite its strengths, Tortoise-TTS comes with practical constraints:
- Inference speed: Originally very slow (minutes per sentence on older GPUs), though modern optimizations now achieve real-time factors (RTF) as low as 0.25–0.3 on 4GB VRAM GPUs, with streaming latency under 500 ms.
- Hardware dependency: Full performance requires an NVIDIA GPU. CPU-only or Apple Silicon runs are possible but slower and lack DeepSpeed support.
- Setup complexity: Windows users are strongly advised to use Conda to avoid dependency conflicts. Proper environment management is essential.
These trade-offs reflect a deliberate design choice: prioritize speech quality and flexibility over convenience or speed.
Why This Matters for Technical Decision-Makers
For teams evaluating TTS solutions, Tortoise-TTS solves a critical pain point: the lack of high-quality, open, and customizable speech synthesis. Commercial APIs offer convenience but limit voice control, impose usage quotas, and raise privacy concerns. On the other end, simpler open-source TTS models often produce flat, robotic speech.
Tortoise-TTS bridges this gap. It delivers near-human expressiveness while remaining fully inspectable and modifiable—ideal for projects where voice identity, emotional tone, or data sovereignty are non-negotiable. Whether you’re building an AI character, a research prototype, or an inclusive accessibility tool, Tortoise-TTS gives you the tools to do it your way, with no black boxes.
Summary
Tortoise-TTS stands out as a high-fidelity, open-source TTS system that prioritizes natural prosody, multi-voice flexibility, and user control. While it demands more computational resources than lightweight alternatives, its ability to clone voices and produce emotionally rich speech makes it a powerful choice for creative, research, and privacy-conscious applications. With ongoing performance improvements and a permissive license, it’s a compelling option for technical teams seeking an alternative to closed, commercial TTS platforms.