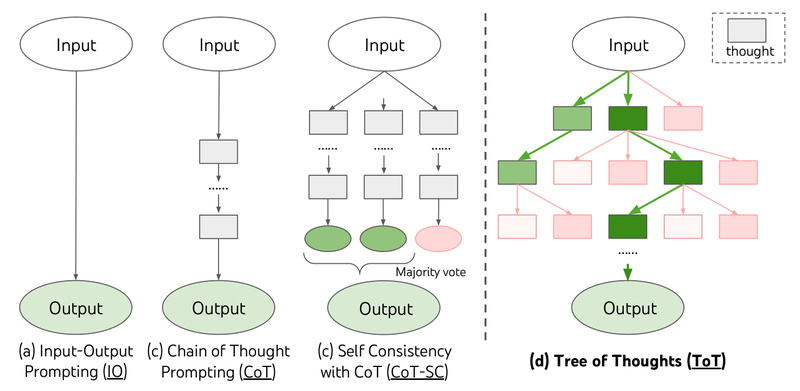
Large language models (LLMs) have transformed how we approach tasks ranging from coding assistance to content generation. Yet, their standard inference methods—processing tokens left-to-right in a linear sequence—often fail when problems demand planning, backtracking, or evaluating multiple options before committing to a path. Enter Tree of Thoughts (ToT): a groundbreaking framework that empowers LLMs to reason like human strategists by exploring, evaluating, and navigating multiple reasoning trajectories in parallel.
Developed by researchers at Princeton NLP and introduced in the paper “Tree of Thoughts: Deliberate Problem Solving with Large Language Models,” ToT generalizes the popular Chain of Thought (CoT) prompting technique. Instead of following a single reasoning chain, ToT enables models to maintain a “tree” of intermediate thoughts, deliberately selecting the most promising branches through self-evaluation, lookahead, and even backtracking when needed. This shift unlocks dramatic performance gains on tasks where early missteps doom linear approaches—making ToT a vital tool for practitioners tackling non-trivial, structured problems.
Why Standard LLM Reasoning Falls Short
Before diving into ToT’s mechanics, it’s essential to understand the limitations of conventional prompting. With standard Input-Output (IO) or Chain of Thought methods, an LLM generates a response step-by-step in a fixed sequence. Once a wrong turn is taken—say, an incorrect arithmetic operation in a math puzzle—the model has no mechanism to reconsider or explore alternatives. It’s locked into a single path, no matter how flawed.
This rigidity becomes especially problematic in domains requiring:
- Strategic lookahead (e.g., planning moves in a game)
- Global consistency (e.g., ensuring a story’s plot points align)
- Combinatorial search (e.g., solving puzzles with many possible states)
In such scenarios, even powerful models like GPT-4 stumble. For example, on the Game of 24—a mathematical puzzle requiring four numbers to be combined using arithmetic operations to reach 24—GPT-4 with CoT prompting succeeds only 4% of the time. The issue isn’t capability; it’s the lack of a deliberative problem-solving process.
How Tree of Thoughts Enables Deliberate Reasoning
ToT reimagines LLM inference as a search process over a tree of coherent reasoning steps, called thoughts. Each thought represents a partial solution (e.g., “10 − 4 = 6”) that can be:
- Generated in multiple plausible variants
- Evaluated for promise (e.g., “How close does this get us to 24?”)
- Selected for further exploration based on that evaluation
This cycle mimics how humans solve complex problems: brainstorming options, assessing their potential, and pruning dead ends. ToT implements this through three modular components:
Thought Generation
At each step, the LLM proposes multiple next thoughts. These can be sampled independently (useful for creative tasks like writing) or sequentially proposed (ideal for structured tasks like math puzzles).
State Evaluation
Each partial solution (or “state”) is scored via self-evaluation. ToT supports two strategies:
- Value-based: Assign a numeric score to each state (e.g., “This path has a 70% chance of success”)
- Vote-based: Compare multiple states and rank them relative to one another
Search Algorithm
ToT is compatible with classic tree-search methods:
- Breadth-First Search (BFS): Explores the top-k most promising paths at each depth
- Depth-First Search (DFS): Drills deep into a single path but backtracks if stuck (used in crossword solving)
Critically, all of this is achieved without modifying the underlying LLM. ToT works purely through prompting and orchestration—making it model-agnostic in principle and easy to integrate with APIs like OpenAI’s GPT-4.
Real-World Impact: Where ToT Excels
The original paper demonstrates ToT’s power across three challenging domains:
Game of 24
A math puzzle where players combine four numbers (e.g., 4, 5, 6, 10) using +, −, ×, ÷ to reach 24. With ToT + BFS, GPT-4’s success rate jumps from 4% (CoT) to 74%—a 18.5× improvement.
Creative Writing
Given a starting sentence, the model must generate a coherent four-paragraph story. ToT enables it to explore multiple plot directions, evaluate narrative consistency, and select the most compelling arc—outperforming CoT in both fluency and coherence.
Mini Crosswords
Solving 3–5 letter crossword clues requires interdependent reasoning across intersecting words. Here, ToT + DFS achieves a 30% solve rate, versus near-zero for standard methods, by backtracking when a word choice leads to contradictions.
These examples share a common thread: tasks where local decisions have global consequences, and recovery from early errors is essential.
Getting Started: Practical Integration
ToT is designed for immediate adoption by technical teams. The official repository (princeton-nlp/tree-of-thought-llm) offers two installation paths:
# Install from PyPI pip install tree-of-thoughts-llm # Or from source git clone https://github.com/princeton-nlp/tree-of-thought-llm cd tree-of-thought-llm pip install -e .
A minimal example solving Game of 24:
from tot.methods.bfs import solve from tot.tasks.game24 import Game24Task import argparse args = argparse.Namespace( backend='gpt-4', temperature=0.7, task='game24', method_generate='propose', method_evaluate='value', n_generate_sample=1, n_evaluate_sample=3, n_select_sample=5 ) task = Game24Task() ys, _ = solve(args, task, start_idx=900) print(ys[0]) # e.g., "(5 * (10 - 4)) - 6 = 24"
Adding a new task requires only:
- Defining a task class (specifying input format, validation logic, etc.)
- Writing task-specific prompts for thought generation and evaluation
No model retraining or architecture changes are needed.
Limitations and Trade-Offs
While powerful, ToT isn’t a universal solution. Key considerations include:
- Computational cost: Exploring multiple paths increases API calls and latency. A single ToT run may consume 10–100× more tokens than CoT.
- Model dependency: Best results require strong reasoning models (e.g., GPT-4). Performance degrades significantly with weaker backends.
- Task suitability: ToT shines only on problems with clear intermediate states and evaluability. It adds little value for simple QA or retrieval tasks.
- Non-determinism: Due to LLM sampling, results can vary across runs—aggregating multiple trials may be necessary for reliability.
When Should You Adopt ToT?
Choose Tree of Thoughts when your project involves:
✅ Multi-step reasoning with high interdependency (e.g., math proofs, logic puzzles)
✅ Need for backtracking or recovery from early errors
✅ Multiple viable solution paths that benefit from comparison
✅ Access to a capable LLM (e.g., GPT-4, Claude 3 Opus) and tolerance for higher latency/cost
Avoid it for straightforward tasks where speed and simplicity outweigh reasoning depth.
Summary
Tree of Thoughts transforms LLMs from reactive text generators into deliberate problem solvers. By structuring inference as a tree search over coherent reasoning steps—with built-in evaluation, selection, and backtracking—ToT unlocks unprecedented performance on planning-intensive tasks. With plug-and-play integration, minimal setup overhead, and dramatic empirical gains (e.g., 74% vs. 4% on Game of 24), it’s a compelling upgrade for any technical team facing complex, structured reasoning challenges. If your work demands more than linear thinking, ToT provides the framework to make your LLM truly strategic.