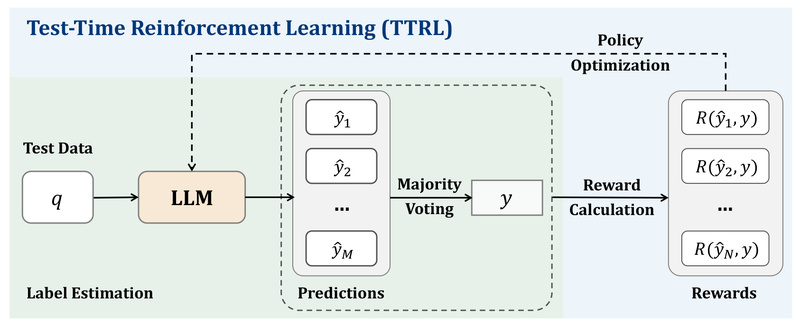
Imagine being able to improve a large language model’s (LLM) reasoning capabilities after deployment, using only unlabeled test data—no ground-truth answers, no human annotators, no expensive reward signals. That’s the promise of TTRL (Test-Time Reinforcement Learning), a novel approach that enables LLMs to self-evolve through reinforcement learning during inference.
TTRL directly addresses a critical bottleneck in real-world AI deployment: the scarcity or impracticality of labeled data for fine-tuning or reward modeling. Traditional RL fine-tuning requires either human feedback (RLHF) or access to correct answers—both of which are often unavailable in live environments like math competitions, customer support logs, or open-ended problem-solving domains. TTRL eliminates this dependency by leveraging inherent signals from the model’s own test-time behavior to guide learning.
How TTRL Works: Reinforcement Learning Without Ground Truth
At its core, TTRL reimagines how rewards can be estimated when no labels exist. Instead of relying on external supervision, it repurposes a well-known technique from Test-Time Scaling (TTS): majority voting across multiple model-generated responses.
Here’s the insight: when an LLM generates several answers to the same question, responses that appear more frequently (i.e., form a “majority”) often correlate with correctness—especially in well-structured reasoning domains like mathematics. TTRL uses this maj@n consensus score as a proxy reward signal. Even though it’s derived purely from the model’s own outputs, this signal proves surprisingly effective for driving policy improvement via reinforcement learning.
This transforms unlabeled test inputs—such as competition problems from AIME 2024—into rich training signals. The model learns to adjust its internal policy to favor strategies that lead to more self-consistent, high-agreement answers, effectively bootstrapping its own improvement.
Proven Performance Gains Across Models and Tasks
TTRL isn’t just theoretically elegant—it delivers measurable results. In experiments, applying TTRL to Qwen-2.5-Math-7B on the AIME 2024 benchmark (using only unlabeled problems) resulted in a 211% increase in pass@1 accuracy—jumping from ~14% to over 43%.
Even more impressively, TTRL consistently exceeds the theoretical upper bound of the original model’s maj@n performance. In other words, it doesn’t just mimic consensus—it learns to generate correct answers more reliably than the initial ensemble could vote for. This demonstrates genuine learning, not just aggregation.
These gains hold across multiple reasoning tasks and model architectures, suggesting TTRL is a general-purpose tool for post-hoc LLM enhancement in label-scarce scenarios.
Ideal Use Cases for Technical Decision-Makers
TTRL is particularly valuable in the following situations:
-
Post-deployment adaptation: You’ve deployed an LLM in a specialized domain (e.g., math tutoring, code generation, or technical QA), and you’re collecting user queries—but you don’t have verified answers. TTRL lets you turn that raw query stream into a signal for continuous improvement.
-
Competition or benchmark settings: In events like math Olympiads or coding challenges, test problems are released without solutions during the event window. TTRL allows teams to refine their models on these problems in real time, even before official answers are published.
-
Resource-constrained R&D: Your team lacks the budget or infrastructure for large-scale human labeling or reward modeling. TTRL offers a zero-label alternative that requires only computational resources for sampling (e.g., 8–32 responses per prompt).
-
Research on self-improving systems: If you’re exploring autonomous learning in LLMs, TTRL provides a practical, reproducible framework for studying how models can refine themselves using internal consistency as a guide.
Getting Started: Simple Integration via Verl
TTRL is built on top of Verl, a modular RL framework for LLMs. Integration is streamlined:
-
Clone the repository:
git clone https://github.com/PRIME-RL/TTRL.git
-
Set up the environment (Python 3.10 recommended):
cd TTRL/verl conda create -n ttrl python=3.10 conda activate ttrl bash scripts/install_ttrl_deps.sh pip install -e .
-
Run a preconfigured experiment (e.g., on AIME 2024):
bash examples/ttrl/Qwen2.5/aime.sh
Under the hood, enabling TTRL often requires only modifying the reward function to use consensus-based scoring. The rest—sampling, policy updates, and optimization—is handled by Verl. The codebase includes scripts for multiple models (Qwen, Llama variants) and benchmarks, making reproduction straightforward.
Note: Experiments in the paper used 8× NVIDIA A100 80GB GPUs, reflecting the compute needed for high-quality sampling (e.g., 32–64 responses per prompt). While smaller runs are possible, performance scales with sampling fidelity.
Limitations and Practical Considerations
While powerful, TTRL has important boundaries:
-
Task dependency: It works best in domains where correct answers are discrete and verifiable via self-consistency, such as math, logic puzzles, or code synthesis. It’s less suited for open-ended generation (e.g., creative writing) where majority voting lacks meaning.
-
Compute overhead: Generating dozens of responses per input is significantly more expensive than standard greedy decoding. This makes TTRL a training-time technique, not an inference-time one.
-
Reliance on maj@n signal: If the base model is too weak or the task too ambiguous, majority voting may not correlate with correctness, weakening the reward signal.
-
Current validation focus: Most results are on reasoning-heavy benchmarks (e.g., AIME, MATH). Broader applicability to classification, dialogue, or multimodal tasks remains to be explored.
Summary
TTRL redefines what’s possible with reinforcement learning in the absence of labels. By turning test-time self-consistency into a training signal, it empowers technical teams to continuously refine LLMs using only raw, unlabeled data—a capability with profound implications for real-world AI systems. Whether you’re competing in benchmarks, deploying domain-specific assistants, or researching autonomous learning, TTRL offers a practical, high-impact path forward. With open-source code, clear documentation, and integration into Verl, it’s ready for adoption by teams seeking label-free LLM evolution.