If you’re a technical decision-maker evaluating options for building or fine-tuning a conversational AI system, you know that high-quality instruction-following data is the backbone of any capable chat model. But sourcing such data often comes with trade-offs: human-collected interactions raise privacy concerns, publicly scraped dialogues may contain noise or bias, and proprietary datasets lock you into vendor ecosystems.
Enter UltraChat—a meticulously engineered, open-source dataset of 1.5 million multi-turn, AI-generated dialogues designed specifically to train robust, general-purpose chat language models without using any real human queries. Developed by researchers at Tsinghua University’s THUNLP group, UltraChat enables you to replicate high-performance models like UltraLM, which once ranked #1 among all open-source models on the AlpacaEval benchmark.
What makes UltraChat unique isn’t just its scale—it’s the deliberate design behind its construction, its topic diversity, and its strict adherence to privacy-by-design principles. For teams seeking to build capable, customizable, and ethically sound conversational agents without relying on user data, UltraChat offers a compelling alternative.
What Makes UltraChat Different
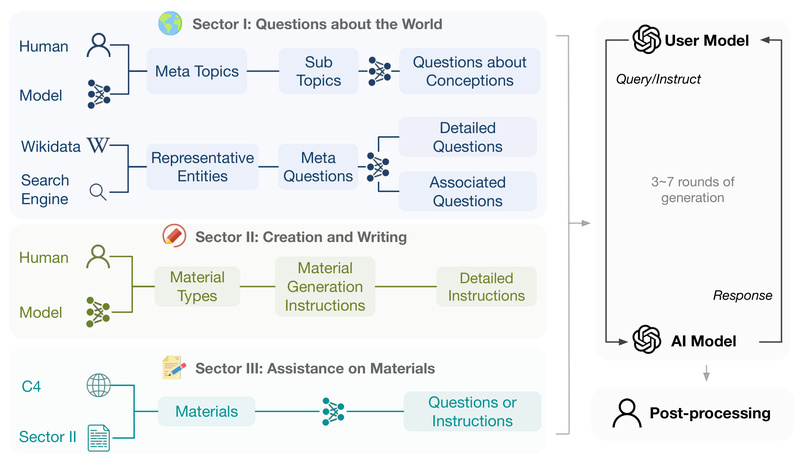
Unlike many instruction datasets that repurpose user prompts from public forums or fine-tuning pipelines that mix in real interactions, UltraChat contains zero human queries. Every conversation is synthetically generated using large language models (LLMs) acting as both user and assistant in a controlled, iterative framework. This eliminates privacy risks while still capturing the breadth and depth of real-world AI interactions.
The dataset is structured around three core sectors, ensuring comprehensive coverage of common assistant tasks:
- Questions about the World: Covers factual, conceptual, and practical inquiries across technology, science, arts, business, and everyday knowledge. Built using 30 meta-topics, 1,100+ subtopics, and 10,000 real-world entities from Wikidata.
- Writing and Creation: Includes dialogues where users request original content—emails, stories, poems, scripts, and more—with iterative refinement and feedback.
- Assistance on Existent Materials: Simulates tasks like summarization, rewriting, continuation, and inference based on existing text snippets (e.g., from the C4 dataset).
Each dialogue spans 3 to 7 turns, significantly longer than many open datasets, and emphasizes coherence, logical flow, and topic consistency. Statistical analyses show UltraChat leads in key metrics: scale, average conversation length, lexical diversity, and semantic richness.
Proven Performance: UltraLM and Beyond
The true test of any instruction dataset is the model it produces. When the THUNLP team fine-tuned LLaMA-13B on UltraChat, the resulting model—UltraLM-13B—outperformed Vicuna (then the SOTA open-source chat model) across multiple benchmarks, including AlpacaEval, Evol-Instruct, and a custom evaluation set spanning commonsense, reasoning, writing, and domain knowledge.
Notably, UltraLM demonstrated strong capabilities in general knowledge recall, creative text generation, and multi-turn consistency—exactly the traits needed for customer-facing chatbots, educational assistants, or internal knowledge tools. Later versions (like UltraLM-13B-v2.0) combined with the UltraFeedback preference dataset and UltraRM reward model achieved over 92% win rates against text-davinci-003 on AlpacaEval using simple best-of-16 decoding.
This performance validates UltraChat not just as a data collection, but as a foundation for state-of-the-art open conversational AI.
Ideal Use Cases for Technical Teams
UltraChat is particularly valuable for organizations and researchers who:
- Want full control over their chat model stack without dependency on closed APIs or user data.
- Need to prototype or deploy domain-specific assistants in education, content creation, technical support, or internal knowledge management—especially when real user logs are unavailable or restricted.
- Require reproducible, open, and ethically sourced training data for academic research, compliance, or responsible AI initiatives.
- Seek to fine-tune base LLMs like LLaMA or GPT-J with high-quality multi-turn dialogue data to boost conversational fluency and instruction adherence.
Because all data is MIT-licensed and hosted on Hugging Face, integration into existing pipelines is straightforward—and legally unambiguous.
Getting Started: Data, Code, and Pretrained Models
UltraChat is designed for immediate usability:
- Download the dataset via Hugging Face Datasets, segmented by sector (e.g., Questions about the World, Writing and Creation).
- Data format is simple: each line is a JSON object with an
"id"and a"data"list alternating user and assistant turns. - Training scripts are provided for both LLaMA (using BMTrain) and GPT-J (using OpenPrompt), with clear instructions for distributed training.
- Pretrained models like UltraLM-13B and UltraLM-65B are available on Hugging Face. You can recover full weights using the provided delta files and
recover.shscript, then chat locally viachat_cli.sh.
This end-to-end tooling lowers the barrier to entry—whether you’re testing a model out-of-the-box or training your own variant from scratch.
Limitations and Realistic Expectations
While UltraChat excels in general knowledge and creative tasks, models trained on it still exhibit limitations in advanced reasoning, mathematics, and code generation. The synthetic nature of the data—though a strength for privacy and scale—means it lacks the unpredictability and edge cases of real human interactions.
Therefore, if your use case demands strong performance in STEM problem-solving or software development, you may need to augment UltraChat with task-specific datasets (e.g., for coding or math reasoning).
That said, for broad-domain conversational ability, instruction following, and text generation, UltraChat remains one of the most effective open resources available.
Summary
UltraChat solves a critical bottleneck in open conversational AI: how to obtain large-scale, high-quality, multi-turn dialogue data without compromising privacy or openness. By generating 1.5 million diverse, coherent, and realistic AI-to-AI conversations across knowledge, creation, and assistance tasks, it enables technical teams to build, benchmark, and deploy capable chat models with full transparency and control.
Whether you’re fine-tuning a base model for internal use, researching instruction-following dynamics, or prototyping the next open-source assistant, UltraChat offers a robust, ethical, and high-performing foundation—backed by real benchmark results and ready-to-use tooling.