Retrieval-Augmented Generation (RAG) has become a cornerstone technique for grounding large language models (LLMs) in real-world knowledge. However, building effective RAG systems—especially ones that adapt knowledge to specific tasks or support multimodal inputs like PDFs, tables, and images—often demands significant engineering effort. This is where UltraRAG comes in.
Developed by THUNLP (Tsinghua University), NEUIR (Northeastern University), OpenBMB, and AI9stars, UltraRAG is an open-source, modular, and automated toolkit designed to streamline the entire RAG lifecycle—from knowledge ingestion and pipeline orchestration to multimodal generation and standardized evaluation. Its standout innovation lies in enabling adaptive knowledge integration while drastically lowering the coding barrier for researchers and developers.
Unlike traditional RAG frameworks that treat retrieval and generation as isolated steps, UltraRAG supports dynamic workflows with loops, conditionals, and multi-stage reasoning—all defined declaratively in simple YAML files. With built-in support for document parsing (PDF, HTML, Markdown), multimodal chunking (text, tables, figures), and plug-and-play components via the Model Context Protocol (MCP), UltraRAG empowers users to prototype advanced RAG systems as effortlessly as assembling building blocks.
Why UltraRAG Solves Real Pain Points
Many existing RAG toolkits assume static, linear pipelines: retrieve → generate. But real-world applications often require iterative refinement, multi-hop reasoning, or conditional branching (e.g., “if confidence is low, retrieve again”). Implementing such logic usually means writing custom orchestration code—time-consuming and error-prone.
UltraRAG eliminates this friction. By abstracting complex control flows into a YAML-based pipeline specification, it lets you express sophisticated RAG strategies—like IRCoT, IterRetGen, or RankCoT—without writing a single line of imperative code. This enables rapid experimentation and iteration, which is critical for both academic research and enterprise deployment.
Moreover, handling non-textual knowledge (e.g., answering questions over scientific charts or scanned reports) remains a major hurdle. UltraRAG natively supports multimodal knowledge ingestion and reasoning by integrating tools like MinerU for structured extraction from PDFs and enabling end-to-end pipelines from document parsing to multimodal generation.
Core Capabilities That Set UltraRAG Apart
Declarative Pipeline Design with Native Control Flow
UltraRAG pipelines are defined in YAML and support sequential steps, loops, and conditional branches out of the box. For example, you can define a loop that continues retrieving and refining until the answer meets a quality threshold. This is powered by an internal MCP client that interprets the YAML and orchestrates calls to modular MCP servers.
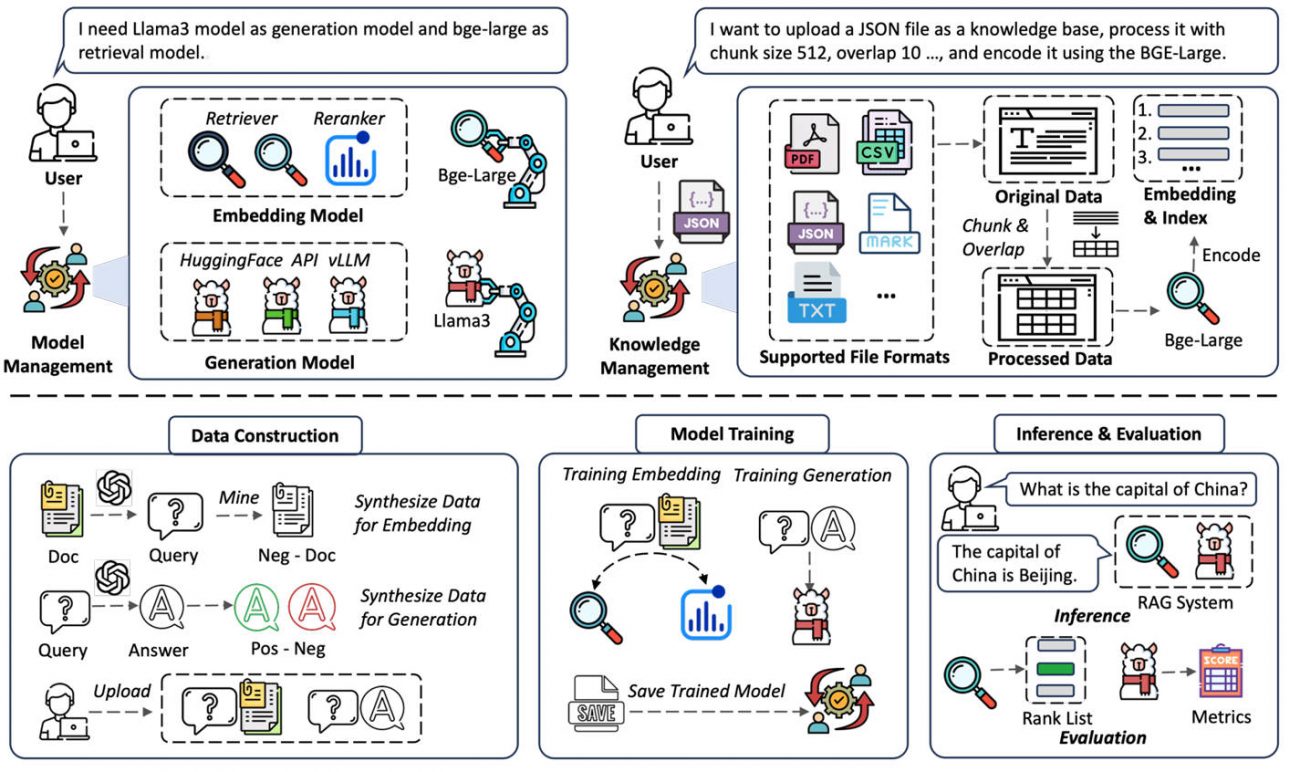
Modular Architecture via Model Context Protocol (MCP)
Every core component—retriever, reranker, generator, corpus parser, evaluator—is packaged as an independent MCP server. These servers expose standardized tool interfaces, allowing seamless integration of new modules or external services. Want to swap a FAISS-based retriever for an OpenAI-powered one? Just register a new MCP server. No global code changes needed.
This plug-and-play design ensures high reusability across projects while maintaining system stability.
Automated Knowledge Base Construction
UltraRAG automates the often tedious process of turning raw documents into a query-ready knowledge base. It supports:
- Input formats: PDF, Markdown, HTML, TXT
- Structured extraction: text, tables, figures (via MinerU integration)
- Chunking strategies optimized for retrieval quality
With one command, you can build a personal or enterprise-scale knowledge base from a folder of technical reports or academic papers.
Unified Evaluation Across Diverse Benchmarks
Reproducibility and fair comparison are vital in RAG research. UltraRAG includes a standardized evaluation framework with built-in support for over 20 public datasets, including:
- Text QA: NQ, TriviaQA, HotpotQA
- Multimodal QA: MP-DocVQA, ChartQA, InfoVQA
- Long-form and fact-checking tasks: ASQA, FEVER
Results are visualized and analyzed consistently, enabling systematic ablation studies and method comparisons.
WebUI for No-Code Experimentation
For users without coding experience, UltraRAG offers a user-friendly WebUI that guides them through pipeline configuration, knowledge base setup, and result inspection—making RAG accessible beyond engineering teams.
Who Should Use UltraRAG?
UltraRAG is ideal for:
- Researchers developing novel RAG algorithms who need to prototype complex reasoning pipelines quickly
- Enterprise teams building private QA systems over internal documents (e.g., technical manuals, legal contracts)
- Developers working on multimodal applications (e.g., document understanding, scientific Q&A)
- Educators running reproducible RAG labs or tutorials
In all these scenarios, UltraRAG shifts focus from infrastructure plumbing to algorithmic innovation and domain-specific adaptation.
Getting Started Is Straightforward
Installation is simple via pip or uv:
git clone https://github.com/OpenBMB/UltraRAG.git cd UltraRAG pip install -e .
To run your first pipeline:
ultrarag run examples/rag.yaml
The toolkit provides ready-to-use examples for methods like Vanilla RAG, IRCoT, VisRAG, and more. You can also launch the WebUI for interactive experimentation or use Docker for containerized deployment with GPU support.
Supported components include vLLM, Sentence Transformers, FAISS (CPU/GPU), BM25, and OpenAI-compatible APIs—ensuring flexibility in model and infrastructure choices.
Limitations to Consider
While UltraRAG minimizes coding effort, users still need a foundational understanding of RAG concepts (e.g., retrieval strategies, chunking, evaluation metrics). Additionally, some advanced features rely on external dependencies (e.g., vLLM for fast inference, MinerU for PDF parsing), which may require GPU resources or careful environment setup.
UltraRAG orchestrates the pipeline but doesn’t dictate model selection—you choose the retriever, generator, and embedding model that best fit your use case.
Why Choose UltraRAG Over Alternatives?
Most RAG toolkits excel at simple “retrieve-then-generate” workflows but falter when tasks demand adaptivity, multimodality, or iterative reasoning. UltraRAG fills this gap by:
- Supporting complex control flows natively (no custom code)
- Offering end-to-end multimodal pipeline support
- Providing standardized, reproducible evaluation across domains
- Enabling rapid iteration via YAML-driven development
This makes it uniquely suited for cutting-edge RAG research and real-world applications where knowledge must be dynamically adapted—not just statically retrieved.
Summary
UltraRAG reimagines RAG development as a modular, declarative, and adaptive process. By combining the Model Context Protocol, YAML-based orchestration, automated knowledge ingestion, and unified evaluation, it removes engineering bottlenecks that often slow down innovation. Whether you’re testing a new retrieval strategy or building a production-grade document QA system, UltraRAG lets you focus on what matters: how knowledge is used, not how the pipeline is coded.