In the era of Vision Transformers and increasingly complex multimodal architectures, convolutional neural networks (ConvNets) have often been written off as outdated. But what if a modern ConvNet could not only match the performance of today’s top models—but surpass them in speed, simplicity, and universality? Enter UniRepLKNet, a breakthrough architecture that redefines what’s possible with large convolutional kernels.
Unlike traditional deep ConvNets that stack dozens of small 3×3 filters to capture long-range context, UniRepLKNet takes a radically different approach: use fewer, much larger kernels—sometimes up to 31×31—to see wide without going deep. This design yields a model with a massive effective receptive field, stronger shape bias (over texture bias), and a unified structure that excels across wildly different data types: images, audio, video, point clouds, and even global-scale time-series like weather forecasting.
With a top-1 ImageNet accuracy of 88.0%, 56.4 COCO box AP, and 55.6 ADE20K mIoU—all achieved through a single architecture—UniRepLKNet proves that ConvNets aren’t just making a comeback; they’re becoming truly universal.
Why Large Kernels? The Core Innovation
Most modern ConvNets mimic the depth-heavy design of ResNet or adopt Transformer-inspired modules. UniRepLKNet challenges this orthodoxy. The key insight: large kernels can capture global spatial relationships in a single layer, eliminating the need for deep stacks and complex attention mechanisms.
The authors propose four architectural guidelines for large-kernel ConvNets:
- Prioritize width over depth—large kernels inherently provide broad spatial awareness.
- Maintain structural simplicity—avoid unnecessary complexity that dilutes the benefits of large kernels.
- Use structural re-parameterization during training to stabilize optimization, then fuse branches for efficient inference.
- Preserve modality-agnostic design—the same backbone should work across diverse inputs with minimal preprocessing.
This philosophy leads to models that are not only more accurate but also faster in real-world inference than Vision Transformers like InternImage or even ConvNeXt v2—thanks to better hardware utilization and fewer sequential operations.
Key Strengths That Solve Real Engineering Pain Points
1. State-of-the-Art Performance Across Vision Benchmarks
UniRepLKNet sets new records with models pretrained only on ImageNet-22K:
- 88.0% top-1 accuracy on ImageNet-1K (384×384 resolution)
- 56.4 box AP on COCO object detection
- 55.6 mIoU on ADE20K semantic segmentation
These results rival or exceed specialized architectures—yet come from a single, unified model family.
2. True Multimodal Universality
Perhaps more impressively, UniRepLKNet doesn’t need architecture changes to handle non-image data. With only task-specific preprocessing (e.g., spectrogram conversion for audio, voxelization for point clouds), the same backbone achieves:
- SOTA results in audio classification
- Strong performance in video action recognition
- World-class accuracy in global temperature and wind speed forecasting—a massive, real-world time-series challenge where it outperforms dedicated meteorological systems
This universality eliminates the need for maintaining separate model codebases per modality—a major win for engineering teams.
3. Deployment-Friendly via Structural Re-parameterization
UniRepLKNet inherits the RepVGG-style re-parameterization technique. During training, it uses parallel branches (e.g., small kernel + identity + batch norm) for better gradient flow. At deployment, these are fused into a single large-kernel convolution—zero latency overhead, no extra parameters.
This means you get the training stability of complex blocks and the inference speed of clean, lean convolutions.
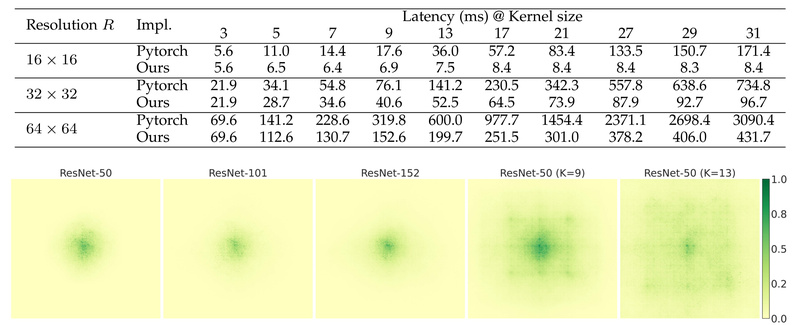
4. Real-World Speed Advantage Over Transformers
Despite massive kernels, UniRepLKNet runs faster than Vision Transformers on standard GPUs. Why? Convolution is inherently more hardware-friendly than attention, especially when implemented efficiently (see below).
Ideal Use Cases for Practitioners
UniRepLKNet shines in scenarios where simplicity, speed, and cross-modality consistency matter:
- Building unified perception pipelines: Deploy one model family for camera, microphone, LiDAR, and sensor time-series in robotics or autonomous systems.
- Edge vision applications: Leverage fast inference and compact deployment structure for real-time image classification or segmentation on embedded devices (especially with re-parameterized models).
- Large-scale forecasting: Tackle climate, energy, or financial time-series without redesigning your architecture.
- Research prototyping: Explore multimodal learning with a single, well-documented backbone instead of stitching together disparate models.
If your team is tired of maintaining separate audio, vision, and time-series models—or struggling with the latency of attention-based systems—UniRepLKNet offers a compelling alternative.
How to Get Started Quickly
Adopting UniRepLKNet is designed to be frictionless:
1. One-Line Model Instantiation via timm
Thanks to native integration with the timm library, you can load a pretrained UniRepLKNet in a single line:
from timm import create_model
model = create_model('unireplknet_l', num_classes=1000, in_22k_pretrained=True)
This automatically downloads and loads weights from Hugging Face.
2. Seamless Integration with MMDetection & MMSegmentation
The unireplknet.py file includes hooks for MM-based frameworks. Just copy the file into your project and reference the model in your config—no code refactoring needed.
3. Optional Speed Boost with Custom CUDA Kernel
For maximum throughput, install the provided DepthWiseConv2dImplicitGEMM CUDA extension. It replaces PyTorch’s native depthwise convolution with an iGEMM-based implementation that’s significantly faster for large kernels (>13×13). Installation takes under a minute and works across CUDA 10.2–11.3 and PyTorch 1.9–1.10.
4. Easy Re-parameterization for Deployment
After training, simply call:
model.reparameterize_unireplknet()
…to convert the model into its deployable form. The output is numerically identical but faster and lighter—ready for production.
Limitations and Practical Considerations
While powerful, UniRepLKNet isn’t a silver bullet:
- Custom CUDA dependency: The speed boost requires compiling a CUDA extension. While well-documented, this adds setup complexity—especially in restricted environments (e.g., some cloud platforms). You can skip it, but inference will be slower.
- High memory demand for large variants: The XL model (386M params) needs substantial GPU memory, especially at 384×384 resolution. Consider the S or B variants for resource-constrained settings.
- Best results require ImageNet-22K pretraining: The headline 88.0% accuracy comes from 22K pretraining. If you only have access to ImageNet-1K, performance drops (e.g., ~83.9% for S variant)—still competitive, but not SOTA.
Assess your infrastructure: if you can leverage 22K-pretrained weights and handle the memory footprint, UniRepLKNet delivers unmatched value.
Summary
UniRepLKNet isn’t just another ConvNet—it’s a paradigm shift in how we design convolutional architectures. By embracing large kernels and structural simplicity, it achieves SOTA performance, true multimodal universality, and production-ready efficiency in a single framework. For engineers and researchers tired of juggling modality-specific models or wrestling with Transformer latency, UniRepLKNet offers a faster, simpler, and surprisingly powerful path forward.
With open-source code, pretrained weights, and easy integration into major vision libraries, there’s never been a better time to give large-kernel ConvNets a serious look.