Time series data is everywhere—in financial markets, wearable health monitors, industrial sensors, and smart infrastructure. Yet, despite its ubiquity, building machine learning systems for time series remains frustratingly fragmented. Most teams juggle separate models for forecasting future values, classifying activity types, detecting anomalies, or filling in missing data. Each task demands its own architecture, training pipeline, and maintenance overhead. The result? Slower iteration, higher operational costs, and brittle systems that don’t generalize across domains.
Enter UniTS—a unified, multi-task time series foundation model that breaks this siloed paradigm. Developed by researchers at Harvard, UniTS integrates forecasting, classification, imputation, and anomaly detection into a single transformer-based architecture with shared parameters and no task-specific modules. Trained on a heterogeneous mix of 38 real-world datasets spanning healthcare, finance, engineering, and human activity sensing, UniTS not only matches but often outperforms specialized models across all four task types—while enabling zero-shot and few-shot transfer to new domains.
For project and technical decision-makers evaluating time series solutions, UniTS offers a rare combination: architectural simplicity, cross-task versatility, and strong empirical performance—all in one deployable model.
The Fragmentation Problem in Time Series Workflows
Before UniTS, the standard practice was clear: use a dedicated model for each time series task. Need to predict stock prices? Use a forecasting model like Informer or Autoformer. Classifying ECG rhythms? Train a separate Temporal Convolutional Network. Detecting sensor failures? Try an unsupervised anomaly detector like USAD. Imputing missing readings from wearables? That’s yet another pipeline, perhaps based on SAITS or BRITS.
This approach works—but at a cost. Maintaining four distinct model stacks multiplies development time, increases deployment complexity, and hinders knowledge transfer between tasks. Worse, when new data domains emerge (e.g., a new IoT sensor type), teams must rebuild entire pipelines from scratch.
UniTS directly addresses this fragmentation by asking: What if a single model could handle all these tasks without structural changes?
How UniTS Unifies Heterogeneous Time Series Tasks
UniTS achieves unification through two key innovations:
Task Tokenization Instead of Task-Specific Heads
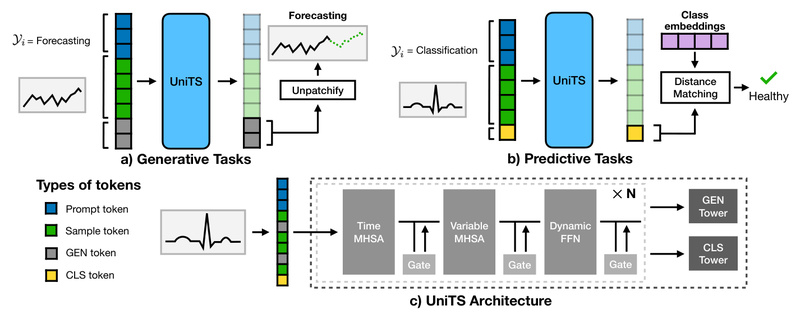
Rather than attaching different output heads for forecasting vs. classification, UniTS encodes the task type directly into the input sequence using task tokens. These tokens—learned embeddings—signal to the model whether it should generate future values, assign a class label, reconstruct masked observations, or flag anomalies. This eliminates the need for task-specific modules, enabling a truly shared backbone.
A Modified Transformer with Sequence and Variable Attention
UniTS builds on a customized transformer block that jointly attends to:
- Temporal dynamics (sequence attention across time steps)
- Inter-variable relationships (variable attention across sensors or features)
Coupled with a dynamic linear operator, this design captures universal patterns across diverse sampling rates, temporal scales, and data domains—critical for multi-task generalization.
Proven Performance Across 38 Real-World Datasets
UniTS isn’t just theoretically elegant—it delivers empirically. In head-to-head comparisons:
- Outperformed 12 dedicated forecasting models
- Beat 20 time series classification baselines
- Surpassed 18 anomaly detection methods
- Exceeded 16 imputation techniques
Notably, UniTS also outperformed repurposed text-based LLMs (e.g., LLMs reprogrammed for time series), demonstrating that domain-native architecture matters. Even in single-task settings—where specialized models have all the advantages—UniTS holds its own, proving that unification doesn’t require sacrificing performance.
Practical Use Cases: Where UniTS Delivers Real Value
Fintech: Dual Needs for Forecasting and Anomaly Detection
A payment processing team can deploy one UniTS model to both forecast transaction volumes (for capacity planning) and detect fraudulent spikes (for real-time alerts)—without maintaining two separate systems.
Digital Health: Wearable Data with Missing Values and Activity Labels
A health tech startup analyzing smartwatch data can use UniTS to:
- Classify user activities (walking, sleeping, etc.)
- Impute missing heart rate readings due to sensor dropout
- Detect abnormal physiological patterns
All with a single model, simplifying both training and edge deployment.
Industrial IoT: Cross-Asset Monitoring
An engineering firm monitoring turbines, pumps, and compressors across sites can fine-tune one pretrained UniTS model to handle anomaly detection on new equipment types using only a few labeled examples—thanks to its few-shot capabilities.
Getting Started: From Installation to Custom Data
UniTS is designed for practical adoption. The official GitHub repository provides a clear workflow:
- Install dependencies via
pip install -r requirements.txt(requires PyTorch 2.0+). - Download benchmark datasets using the provided
download_data_all.shscript, or plug in your own time series data following the tutorial. - Choose a training strategy:
- Pretraining + prompt learning: Leverage large-scale multi-domain pretraining, then adapt via prompt tuning.
- Supervised learning: Train end-to-end on your task-specific data.
- Apply transfer strategies for new tasks:
- Use few-shot fine-tuning or prompt tuning for new forecasting, classification, anomaly detection, or imputation tasks.
- Attempt zero-shot forecasting for new prediction horizons or datasets (with a specially trained variant).
Pretrained checkpoints are publicly available, and the codebase includes scripts for all major scenarios—making experimentation fast and reproducible.
Limitations and Practical Considerations
While UniTS is remarkably flexible, it’s not a magic bullet:
- Input format constraints: Your time series data must be structured into the expected (batch, sequence_length, num_variables) tensor format. Domain-specific preprocessing (e.g., handling irregular timestamps) remains your responsibility.
- Latency-sensitive applications: UniTS uses a transformer backbone, which may be heavier than lightweight RNNs or linear models for ultra-low-latency edge inference. Quantization or distillation may be needed in such cases.
- Zero-shot reliability: While UniTS supports zero-shot transfer, performance on completely novel domains (e.g., geophysical time series when trained only on biomedical data) may degrade. Prompt tuning with minimal labels (e.g., 5–20 examples) is often necessary to stabilize results.
Summary
UniTS represents a significant step toward time series foundation models. By unifying forecasting, classification, imputation, and anomaly detection under one architecture—without task-specific modules—it eliminates model sprawl, reduces engineering overhead, and enables knowledge transfer across domains. Its strong empirical results across 38 diverse datasets, combined with support for few-shot and zero-shot learning, make it a compelling choice for teams looking to simplify their time series ML stack.
If your work involves multiple time series tasks across evolving data sources, UniTS isn’t just another model—it’s a strategic enabler for faster iteration, lower maintenance, and more robust generalization.