Imagine deploying a single robot policy that works across different hardware—robotic arms, mobile bases, or even human-inspired setups—without retraining from scratch for each new device. UniVLA (Universal Vision-Language-Action) makes this vision practical by introducing a task-centric latent action framework that learns from diverse video sources, including internet-scale human demonstrations. Unlike traditional vision-language-action (VLA) models that demand massive, robot-specific datasets and enormous compute budgets, UniVLA achieves state-of-the-art performance with dramatically fewer resources: less than 5% of OpenVLA’s training compute and only 10% of downstream demonstration data.
Developed by OpenDriveLab, UniVLA redefines how generalist robot policies can be trained. Instead of relying solely on robot-collected trajectories, it leverages heterogeneous data—including videos of humans performing tasks—to build transferable action representations. At its core, UniVLA uses a two-stage latent action model trained in the DINO feature space, guided by language instructions to filter out task-irrelevant motion. This enables the system to extract what matters from any video, regardless of the embodiment performing the action.
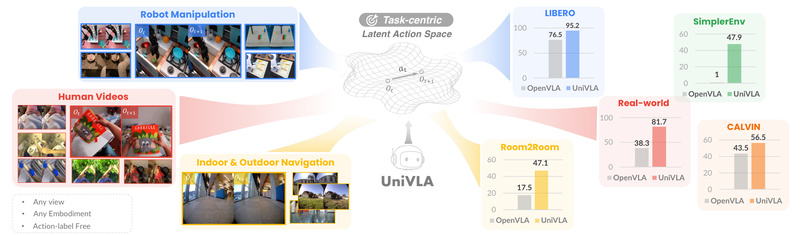
The result? A lightweight, efficient, and highly generalizable policy that excels across simulation benchmarks like LIBERO, CALVIN and SimplerEnv, and transfers effectively to real-world robots such as those on the AgiLex platform. For engineers, researchers, and product teams working on embodied AI, UniVLA offers a compelling path toward scalable, data-efficient, and hardware-agnostic robotic intelligence.
Why UniVLA Solves Real Robotics Bottlenecks
Drastically Lower Data and Compute Requirements
Training general-purpose robot policies has traditionally required millions of labeled robot trajectories—a costly and often infeasible proposition. UniVLA flips this paradigm. By learning task-centric latent actions from unlabeled or weakly labeled videos (including human footage from Ego4D), it reduces dependency on expensive robot-collected data.
Notably, full pretraining of UniVLA-7B takes only ~960 A100 GPU-hours—just 1/20th the compute of OpenVLA. Even more impressively, fine-tuning on specific tasks like BridgeV2 or human-centric actions can be done in under 200 GPU-hours. This makes advanced VLA capabilities accessible to teams without access to massive GPU clusters.
Cross-Embodiment Generalization Without Custom Architectures
Most VLA models are tightly coupled to a specific robot’s action space (e.g., joint angles or end-effector velocities). Change the hardware, and you must retrain. UniVLA decouples policy learning from embodiment by operating in a unified, embodiment-agnostic latent action space.
During deployment, a tiny task-specific action decoder (only ~12M parameters) maps these latent actions to the target robot’s motor commands. This modular design means the same pretrained UniVLA backbone can be rapidly adapted to new robots via lightweight fine-tuning—often using LoRA with just 123M trainable parameters.
State-of-the-Art Performance Across Benchmarks
UniVLA doesn’t just save resources—it outperforms prior art. On the LIBERO suite, it achieves 95.2% average success rate, surpassing OpenVLA (76.5%) and all other baselines across all four sub-benchmarks (Spatial, Object, Goal, and Long). Even with only 10% of training data, UniVLA scores 86.3% on LIBERO-Goal—beating OpenVLA’s full-data performance.
In SimplerEnv real-to-sim evaluations on the WidowX robot, UniVLA achieves a 47.9% overall success rate, far exceeding Octo (~30%) and OpenVLA (~1%). Real-world demos further validate its robustness—from folding towels to solving Tower of Hanoi—proving that its learned representations translate beyond simulation.
Ideal Use Cases for Practitioners
UniVLA shines in scenarios where data is scarce, hardware varies, or rapid adaptation is needed:
- Multi-robot deployment: Use one pretrained policy across different arms or mobile manipulators by swapping only the lightweight action decoder.
- Bootstrapping from human videos: Leverage public datasets like Ego4D to pretrain skills before fine-tuning on limited real-robot data.
- Low-data fine-tuning: Achieve high performance on new tasks with as little as 10–20% of standard demonstration datasets.
- Simulation-to-reality transfer: Pretrain in diverse simulators (LIBERO, CALVIN, Room2Room) and deploy on physical platforms like AgiLex with minimal retraining.
The framework officially supports evaluation and fine-tuning on LIBERO, CALVIN, Room2Room, and SimplerEnv, with clear scripts for both training and real-world deployment.
Getting Started Without Deep Expertise
You don’t need a robotics PhD to use UniVLA. The team provides a streamlined workflow:
- Start with pretrained models: Download UniVLA-7B or task-specific variants (e.g.,
univla-libero,univla-calvin) from Hugging Face via the Model Zoo. - Use provided latent action models: The
lam-stage-2checkpoint generates task-centric pseudo-labels from video—no need to train your own unless you have custom data. - Fine-tune efficiently: Use the included scripts (
finetune_libero.py,finetune_calvin.py) with LoRA to adapt to your task. Training logs, config templates, and data formatting guides are all included. - Deploy with a lightweight decoder: After fine-tuning, extract the action decoder and pair it with the UniVLA backbone for inference on your robot.
The codebase is built on PyTorch and integrates with standard tools like FlashAttention-2. Setup takes minutes with conda, and the repo includes detailed instructions for dataset preparation (e.g., converting Ego4D to RLDS format).
Limitations and Practical Notes
While powerful, UniVLA has constraints worth considering:
- Backbone dependency: It currently relies on the Prismatic VLM architecture with DINO + SigLIP vision encoders. Swapping backbones isn’t trivial.
- Data format requirements: Training data must be in RLDS or OXE-compatible formats. Custom datasets require preprocessing into this structure.
- Decoder customization: Every new robot embodiment needs a dedicated action decoder trained via fine-tuning. However, this step is lightweight and well-documented.
- Human video utility: Internet videos only help if processed through UniVLA’s latent action pipeline—they can’t be used as raw inputs “out of the box.”
These are manageable trade-offs given the framework’s overall efficiency and performance gains.
Summary
UniVLA represents a significant leap toward practical, general-purpose robot learning. By decoupling policy intelligence from hardware specifics and leveraging heterogeneous video data—including human demonstrations—it delivers top-tier performance with minimal data and compute overhead. For teams building embodied AI systems, it offers a rare combination: research-grade results, production-friendly efficiency, and real-world deployability. Whether you’re fine-tuning for a warehouse robot or prototyping in simulation, UniVLA lowers the barrier to building truly adaptable robotic agents.
Explore the code, try the pretrained models, and see how a task-centric latent action space can transform your robotics pipeline.