As AI-generated videos grow increasingly convincing—featuring smooth motion, vivid aesthetics, and coherent narratives—a critical question emerges: How do we reliably measure whether these videos are not just visually pleasing, but truly faithful to reality?
Enter VBench, an open-source, comprehensive benchmark suite purpose-built to evaluate video generative models across both technical quality and deeper dimensions of realism. Developed by researchers at top institutions and accepted at CVPR 2024 and TPAMI 2025, VBench has rapidly evolved through three major iterations—VBench, VBench++, and the newly released VBench-2.0—to address the full spectrum of video generation challenges, from basic frame-level fidelity to intrinsic faithfulness grounded in physics, human anatomy, and commonsense reasoning.
For technical decision-makers, researchers, and AI engineers building or selecting video generation systems for applications like virtual production, simulation, or content creation, VBench offers a standardized, human-aligned, and extensible evaluation framework that cuts through marketing claims and reveals what models actually get right—or wrong.
Why Video Generation Needs Structured Evaluation
Early benchmarks for generative AI focused largely on images or text. But video introduces unique complexities: temporal coherence, object permanence, motion dynamics, and inter-frame consistency. A model might produce stunning individual frames yet fail catastrophically on basic physical plausibility—like a person walking through a wall or objects floating mid-air.
Superficial metrics (e.g., FID, CLIP score) often miss these failures. VBench was created to fill this gap by decomposing “video quality” into well-defined, measurable dimensions—first for technical aspects, and now for intrinsic faithfulness.
The VBench Family: From Technical Quality to Intrinsic Realism
VBench (CVPR 2024): Foundational Technical Evaluation
The original VBench introduced a hierarchical evaluation framework covering 16 dimensions across two categories:
- Quality Dimensions: subject consistency, background consistency, temporal flickering, motion smoothness, aesthetic quality, imaging quality, dynamic degree
- Semantic Dimensions: object class, human action, spatial relationships, scene fidelity, color accuracy, etc.
Each dimension is evaluated using purpose-built pipelines—combining classical computer vision, deep learning metrics, and perceptual models—ensuring scores align closely with human preference annotations.
VBench++ (TPAMI 2025): Versatility and Trust
VBench++ extends the suite to new modalities and responsibilities:
- VBench-I2V: Evaluates image-to-video models using an adaptive image suite
- VBench-Long: Benchmarks long-form video generation (e.g., Sora-like outputs)
- VBench-Trustworthiness: Assesses fairness, cultural sensitivity, bias, and safety
This makes VBench++ the first benchmark to holistically evaluate not just how well a model generates video, but how responsibly.
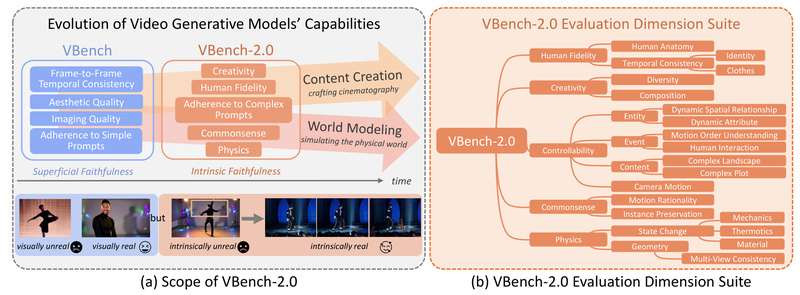
VBench-2.0 (2025): The Leap to Intrinsic Faithfulness
While earlier versions focused on superficial faithfulness (does it look good?), VBench-2.0 tackles intrinsic faithfulness (does it make sense in the real world?). It evaluates five high-level categories:
- Human Fidelity: Anatomical correctness, natural motion, pose plausibility
- Controllability: Ability to follow complex prompts accurately
- Creativity: Novel yet coherent compositions
- Physics: Adherence to real-world physical laws (e.g., gravity, collision)
- Commonsense: Logical consistency in everyday scenarios
These are measured using a hybrid framework that blends specialist models (e.g., anomaly detectors for human motion) and generalist foundation models (SOTA VLMs and LLMs), all validated against extensive human judgments.
Practical Use Cases for Technical Decision-Makers
VBench isn’t just for academic evaluation—it delivers concrete value in real-world scenarios:
- Model Selection: Compare 40+ T2V and I2V models on the official VBench Leaderboard before committing to a vendor or architecture.
- R&D Validation: Quantify improvements during model iteration—e.g., “Our new motion module reduces temporal flickering by 22%.”
- Failure Diagnosis: Identify subtle flaws (e.g., unnatural limb movement, physics violations) that user testing might miss until it’s too late.
- Compliance & Safety Auditing: Use VBench-Trustworthiness to screen for harmful stereotypes or unsafe content in generative pipelines.
For AI-assisted filmmaking or simulated training environments, where realism directly impacts outcomes, VBench helps avoid costly errors rooted in implausible or inconsistent video outputs.
Getting Started: Flexible and Developer-Friendly
VBench supports two primary workflows:
1. Standardized Benchmarking (For Fair Comparisons)
Evaluate your model on VBench’s official Prompt Suite (160+ carefully curated prompts) to generate leaderboard-ready results. Videos must follow the expected naming convention and structure, ensuring apples-to-apples comparisons across models.
2. Custom Video Evaluation (For Rapid Prototyping)
Test your own videos—even with private prompts—on core quality dimensions:
vbench evaluate --dimension motion_smoothness --videos_path ./my_videos/ --mode=custom_input
Currently supported custom dimensions include: subject_consistency, motion_smoothness, aesthetic_quality, and others focused on low-level fidelity.
Installation & Integration
VBench is available via PyPI:
pip install vbench
It offers both a command-line interface and a Python API, supports multi-GPU evaluation, and includes pre-collected sampled videos from leading models (e.g., VideoCrafter, Pika, Gen-3) for immediate experimentation.
Note: Some dimensions (e.g., human action) require optional dependencies like Detectron2, which needs CUDA 11.x or 12.1.
Limitations and Best Practices
While powerful, VBench has boundaries to consider:
- Custom prompt support is limited: Only basic quality dimensions accept arbitrary inputs; semantic and intrinsic faithfulness evaluations require standard prompts for scoring consistency.
- Intrinsic evaluation relies on foundation models: VBench-2.0’s physics and commonsense scores depend on VLM/LLM judgments, which may inherit biases or hallucinations from their base models.
- Human review remains essential: Automated scores should guide—not replace—expert judgment in high-stakes applications like medical simulation or autonomous driving training.
Always pair VBench results with targeted human evaluation when realism directly impacts safety or user trust.
Summary
VBench represents the state-of-the-art in video generative model evaluation—evolving from pixel-level quality checks to deep assessments of physical, anatomical, and logical realism. By providing a unified, open, and human-aligned framework across VBench, VBench++, and VBench-2.0, it empowers technical leaders to make evidence-based decisions, avoid hidden failure modes, and push the field toward truly world-consistent video generation.
Whether you’re benchmarking a new architecture, selecting a commercial API, or auditing a production pipeline, VBench gives you the metrics that matter—not just for how videos look, but for how they behave in the real world.