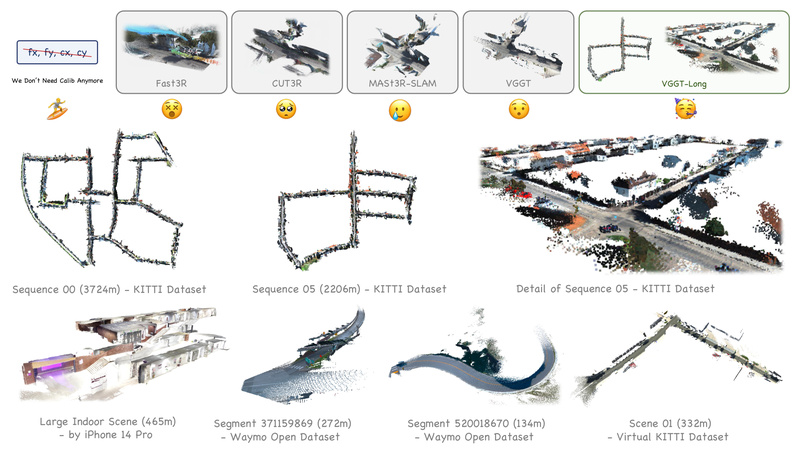
Monocular 3D reconstruction has seen rapid advances thanks to foundation models capable of inferring rich geometric structure from single images. However, deploying these models on real-world, long-form RGB video—such as those captured during autonomous vehicle operation—remains a major practical hurdle. Most foundation models quickly hit GPU memory limits when processing sequences longer than a few hundred frames, making kilometer-scale reconstruction infeasible without complex engineering workarounds.
Enter VGGT-Long: a lightweight yet powerful system that extends the capabilities of the VGGT foundation model to handle kilometer-long, unbounded outdoor RGB sequences—all without requiring camera calibration, depth supervision, or retraining. By intelligently chunking input sequences, aligning overlapping segments, and applying a lightweight loop closure mechanism, VGGT-Long achieves reconstruction accuracy on par with traditional SLAM systems while leveraging the semantic richness of modern vision foundation models.
For technical decision-makers in autonomous driving, robotics, and large-scale 3D scene modeling, VGGT-Long offers a rare combination: plug-and-play compatibility with state-of-the-art monocular models, robustness to real-world scale, and minimal dependency on ground-truth metadata.
Why VGGT-Long Solves a Real Pain Point
Existing vision foundation models for 3D reconstruction are typically evaluated on short clips or indoor scenes. When applied to real-world driving logs—spanning thousands of frames over kilometers—they either crash from GPU memory overflow or produce inconsistent geometry due to drift and lack of global consistency.
VGGT-Long directly addresses this scalability bottleneck. It enables monocular 3D reconstruction at scale in environments where:
- Camera intrinsics are unknown or vary over time
- No LiDAR or depth sensors are available
- Sequences are too long for end-to-end processing on a single GPU
This is especially valuable in autonomous driving R&D, where teams often work with legacy or anonymous video logs lacking calibration data—but still need reliable 3D scene estimates for simulation, mapping, or behavior analysis.
Core Technical Innovations
Chunk-Based Processing for Memory Efficiency
Instead of feeding the entire sequence into VGGT at once (which is impossible beyond ~200 frames on most GPUs), VGGT-Long splits the input into manageable chunks. Each chunk is processed independently by the underlying VGGT model, sidestepping GPU memory constraints entirely.
Overlap-Based Alignment for Geometric Consistency
Adjacent chunks share overlapping frames. VGGT-Long uses these overlaps to align the 3D trajectories and reconstructions across chunks via relative pose estimation. This ensures smooth transitions and prevents abrupt misalignments that would otherwise fragment the reconstructed scene.
Lightweight Loop Closure Without Heavy Engineering
To combat long-term drift—a common issue in monocular reconstruction—VGGT-Long integrates a lightweight loop closure module. It detects revisited places (using visual place recognition) and applies a minimal Sim3 optimization to globally align the trajectory. Notably, this is implemented in pure Python by default, though a faster C++ backend is available for performance-critical deployments.
Zero Retraining, Zero Calibration
Perhaps most compelling for practitioners: VGGT-Long uses the original pre-trained VGGT weights as-is. No fine-tuning, no custom training, and no need for camera parameters. This dramatically lowers the barrier to adoption for teams without access to large-scale 3D training data or calibration pipelines.
Ideal Use Cases
VGGT-Long excels in scenarios involving long-duration, uncalibrated monocular video in outdoor environments, including:
- Autonomous vehicle data logs: Reconstructing 3D scenes from dashcam or fleet footage without sensor metadata
- Urban mapping from handheld or drone video: Generating consistent geometry over city-scale routes
- Legacy video analysis: Extracting 3D structure from archival or crowd-sourced video where depth or calibration is missing
It is particularly suited for teams with limited GPU memory but ample disk space, as it trades VRAM usage for temporary disk storage (more on this below).
Getting Started: Python-First, No C++ Required
Despite using C++ components under the hood for optional acceleration, VGGT-Long is designed for ease of adoption by deep learning practitioners. The default pipeline runs entirely in Python:
- Create a Conda environment with Python 3.10
- Install PyTorch (tested on 2.2.0 + CUDA 11.8) and other dependencies via
pip install -r requirements.txt - Download pre-trained weights with a single script:
bash ./scripts/download_weights.sh - Run inference with a simple command:
python vggt_long.py --image_dir ./your_image_sequence
Optional C++ modules (for loop closure and visual place recognition) can be compiled for speed gains, but they are not required for basic functionality. This “works out of the box” philosophy makes VGGT-Long accessible even to researchers without systems programming experience.
Important Practical Considerations
While VGGT-Long solves GPU memory issues, it introduces disk I/O and storage requirements:
- Disk space: For a KITTI-style sequence (~4,500 frames), expect ~50 GiB of temporary storage. Shorter sequences (e.g., 300 frames) use ~5 GiB.
- Runtime performance: Since intermediate results are written to and read from disk, SSD storage significantly accelerates processing compared to HDDs.
- Automatic cleanup: Temporary files are deleted after reconstruction, but users must ensure sufficient free space beforehand to avoid system instability (CPU OOM can freeze the entire machine).
Additionally, VGGT-Long relies on the pre-trained VGGT model weights, which are available under specific licensing terms. Commercial users should review the license and consider the commercial version if needed.
Summary
VGGT-Long bridges the gap between cutting-edge monocular 3D foundation models and real-world, large-scale deployment. By introducing a memory-efficient, calibration-free, and retraining-free pipeline, it unlocks kilometer-scale reconstruction for autonomous driving, urban mapping, and video-based 3D analysis—without sacrificing geometric consistency or semantic richness. For technical teams evaluating solutions for long-sequence monocular reconstruction, VGGT-Long offers a rare blend of simplicity, scalability, and performance.