Video understanding has long been bottlenecked by two competing demands: capturing fine-grained local motion while simultaneously modeling long-range temporal dependencies. Traditional approaches like 3D CNNs suffer from high computational redundancy, while video transformers—though powerful—scale quadratically with sequence length, making them impractical for high-resolution or long-duration videos.
Enter VideoMamba, a novel architecture built on State Space Models (SSMs) that rethinks how we process video data. By leveraging a linear-complexity operator, VideoMamba efficiently handles both short clips and extended video sequences without sacrificing performance. Released as open-source software with pretrained models and training scripts, it offers a practical, plug-and-play solution for developers and researchers tackling real-world video analysis challenges.
Why VideoMamba Stands Out
Unlike conventional backbones, VideoMamba doesn’t require massive pretraining on billions of videos to scale effectively. Its design integrates a self-distillation technique that enables strong transferability across tasks—even when starting from modest datasets. This makes it particularly appealing for teams without access to large-scale compute clusters or proprietary video corpora.
Moreover, VideoMamba is not a one-trick pony. It unifies capabilities across multiple video understanding regimes—short-term action recognition, long-term temporal modeling, and multimodal alignment—within a single, coherent architecture. This versatility stems from its core innovation: adapting the Mamba sequence model to the spatiotemporal structure of video.
Solving Real Pain Points in Video Analysis
1. Efficient Scalability Without Massive Pretraining
Many modern video models rely on pretraining on enormous datasets like IG-65M or WebVid-2M, which are inaccessible to most organizations. VideoMamba bypasses this barrier through a novel self-distillation strategy that enhances feature learning during training, enabling strong performance even with limited data. This lowers the entry threshold for adopting state-of-the-art video understanding in resource-constrained environments.
2. High Sensitivity to Subtle Motion Cues
In tasks like fine-grained action recognition—e.g., distinguishing between “picking up a cup” and “handing over a cup”—temporal precision matters. VideoMamba demonstrates exceptional sensitivity to minute motion differences in short video clips, outperforming both 3D CNNs and transformer-based models on benchmarks like Something-Something V2.
3. Superior Long-Term Video Modeling
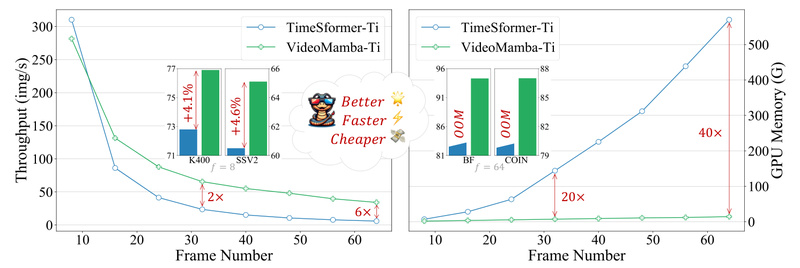
For applications involving minutes-long footage—such as surveillance, instructional video analysis, or sports highlight detection—the ability to model long-range context is critical. Thanks to its linear-time complexity, VideoMamba processes long sequences far more efficiently than quadratic-attention models, while maintaining or improving accuracy on datasets like ActivityNet and Charades.
4. Native Multimodal Compatibility
VideoMamba isn’t confined to pixels. Its architecture seamlessly integrates with textual inputs, enabling strong performance on video-text retrieval tasks without major architectural overhauls. This makes it ideal for building multimodal systems such as video search engines or accessibility tools that align spoken narration with visual content.
Where VideoMamba Delivers Real-World Value
VideoMamba is particularly well-suited for the following scenarios:
- Surveillance and Security: Detecting anomalous behaviors over extended periods without overwhelming compute resources.
- Sports Analytics: Recognizing complex, fine-grained player actions (e.g., dribbling vs. passing) in real time.
- Long-Form Content Indexing: Automatically tagging or summarizing hours of lecture recordings, cooking shows, or gameplay streams.
- Multimodal Video Search: Building systems where users can retrieve relevant video segments using natural language queries.
Because it supports both single-modality (e.g., video-only classification) and multimodal (e.g., video-text alignment) pipelines, teams can deploy one backbone across diverse product features.
Getting Started Is Straightforward
The official repository (hosted on GitHub by OpenGVLab) is organized for immediate usability:
- The
video_smdirectory contains scripts and models for single-modality tasks, including short- and long-term video understanding as well as masked modeling. - The
video_mmfolder provides tools for multimodal applications, such as video-text retrieval. - Pretrained models are available for immediate inference or fine-tuning, and training scripts follow community-standard practices.
Thanks to its linear-complexity design, VideoMamba runs efficiently on standard GPUs—no need for specialized hardware or distributed training setups for most use cases.
Limitations and Practical Considerations
While VideoMamba represents a significant leap forward, prospective adopters should note a few caveats:
- Early model releases were trained without layer-wise learning rate decay—a common technique in masked autoencoding—but this was later addressed in the VideoMamba-M variant.
- Although more efficient than transformers, inference on very high-resolution or ultra-long videos may still require GPU acceleration.
- As a relatively new architecture (introduced in early 2024), community tooling, third-party integrations, and deployment guides are still maturing compared to established models like TimeSformer or VideoMAE.
Nonetheless, the open-source release—including full code, models, and training protocols—enables rapid experimentation and adaptation.
Summary
VideoMamba redefines what’s possible in efficient video understanding. By combining the temporal modeling strengths of State Space Models with practical design choices for real-world deployment, it solves longstanding pain points: high compute costs, poor long-video handling, and modality inflexibility. Whether you’re building an action recognition system, a video search engine, or a long-form content analyzer, VideoMamba offers a scalable, performant, and open foundation worth evaluating for your next project.