Imagine being able to ask questions like “What did the professor say about quantum entanglement in Lecture 3?” or “Show me all scenes in this 50-hour documentary series where climate policy was discussed”—and getting precise, context-aware answers instantly. Until recently, this level of intelligent interaction with long-form video content remained out of reach for most AI systems.
Enter VideoRAG: the first Retrieval-Augmented Generation (RAG) framework purpose-built for extremely long-context videos. While traditional RAG excels with text, it struggles—or fails entirely—with the rich, multimodal fabric of video. VideoRAG bridges this gap by enabling Large Language Models (LLMs) to reason over visual, audio, and semantic content across videos that span hundreds of hours.
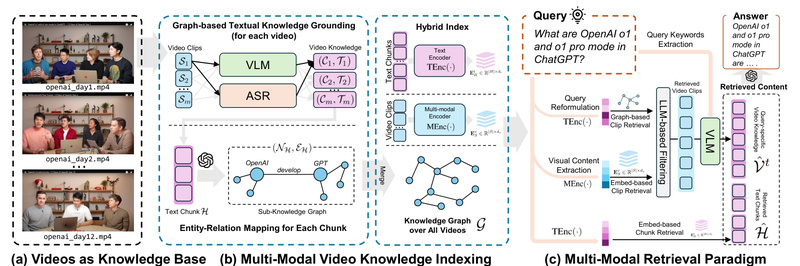
Developed by the HKUDS team, VideoRAG isn’t just another video captioning tool. It’s a dual-channel architecture that fuses graph-based textual knowledge grounding with multimodal context encoding, creating structured, searchable representations of video content without sacrificing temporal or visual fidelity. The result? A system that can chat with your videos—accurately, scalably, and intuitively.
What Makes VideoRAG Unique?
Built for Extreme Video Lengths—No Compromises
Most video understanding models cap out at minutes, not hours. VideoRAG shatters that limit. It processes unlimited-length videos, including collections totaling over 134 hours (as validated on the LongerVideos benchmark). Whether you’re analyzing a 30-second clip or a 100-hour lecture series, VideoRAG scales seamlessly.
Cross-Video Semantic Understanding
Unlike isolated video analyzers, VideoRAG constructs knowledge graphs that span multiple videos. This enables cross-video reasoning—for example, comparing how two documentaries frame the same historical event or tracking a concept across a semester’s worth of recorded lectures.
Designed for Real Users, Not Just Researchers
The companion desktop app, Vimo, brings VideoRAG’s power to everyday users:
- Drag-and-drop upload of MP4, MKV, AVI, and other common formats
- Natural language querying—no technical syntax required
- Cross-platform support (macOS, Windows, Linux)
For developers and researchers, the open-source framework offers extensible architecture, full access to the LongerVideos benchmark, and reproducible evaluation scripts.
Who Benefits from VideoRAG?
Educators & Students
Review recorded lectures efficiently. Ask, “In which segment did the instructor explain backpropagation?” and get an exact timestamp—not just a transcript snippet.
Documentary Filmmakers & Researchers
Analyze thematic evolution across episodes. Compare narrative structures, interview responses, or visual motifs in multi-part series without manual scrubbing.
AI Developers & Product Teams
Build intelligent video assistants, educational tools, or enterprise knowledge bases that understand and retrieve from long-form video archives—a capability previously reserved for text-based systems.
Legal & Compliance Professionals
Rapidly locate specific statements, agreements, or visual evidence in lengthy depositions, hearings, or surveillance footage using semantic search, not just keyword matching.
How to Get Started
VideoRAG offers two pathways:
Option 1: Vimo Desktop App (Coming Soon)
The simplest route for non-technical users. A beta release for macOS (Apple Silicon) is underway, with Windows and Linux versions to follow. Just install, drag in your video, and start chatting.
Option 2: Run from Source
For developers and researchers, the full pipeline is available on GitHub. Setup involves:
- Configuring the Python backend with the VideoRAG server
- Launching the Electron-based frontend
- Uploading videos and issuing queries via natural language
Notably, VideoRAG runs efficiently on a single RTX 3090 (24GB), making advanced long-video understanding accessible without expensive infrastructure.
Performance That Stands Out
VideoRAG was rigorously evaluated on the LongerVideos benchmark, comprising:
- 164 videos across lectures, documentaries, and entertainment
- 602 diverse queries testing factual recall, cross-video reasoning, and temporal understanding
- 134+ total hours of content
Results show significant improvements over existing RAG variants and long-video understanding baselines—precisely because VideoRAG was designed from the ground up for multimodal, long-context video retrieval, not adapted from text-centric systems.
Its dual-channel architecture ensures that both semantic relationships (via knowledge graphs) and visual dynamics (via hierarchical encoding) are preserved, enabling more accurate retrieval and generation.
Limitations and Considerations
While powerful, VideoRAG has practical constraints:
- The Vimo desktop app is still in beta, with macOS support arriving first.
- Running from source requires familiarity with Python, Conda, and GPU environments.
- Optimal performance assumes access to a modern GPU (e.g., RTX 3090); CPU-only inference is not currently supported.
These are reasonable trade-offs for a system tackling one of AI’s hardest challenges: scalable, semantic understanding of ultra-long videos.
Summary
VideoRAG redefines what’s possible with video and AI. By extending Retrieval-Augmented Generation into the multimodal, long-form video domain, it solves real-world problems that text-only RAG or short-video models simply cannot address. Whether you’re a researcher validating hypotheses across video datasets, a creator analyzing narrative arcs, or a developer building the next generation of AI assistants, VideoRAG provides the foundation for deep, accurate, and efficient video understanding at scale.
With open-source code, a comprehensive benchmark, and a user-friendly desktop interface in development, VideoRAG is not just a research prototype—it’s a practical tool ready for adoption.